 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRaFT: Circuit-Guided Refusal Feature Selection via Cross-Layer Transcoders
Apr 02, 2026As safety concerns around large language models (LLMs) grow, understanding the internal mechanisms underlying refusal behavior has become increasingly important. Recent work has studied this behavior by identifying internal features associated with refusal and manipulating them to induce compliance with harmful requests. However, existing refusal feature selection methods rely on how strongly features activate on harmful prompts, which tends to capture superficial signals rather than the causal factors underlying the refusal decision. We propose CRaFT, a circuit-guided refusal feature selection framework that ranks features by their influence on the model's refusal-compliance decision using prompts near the refusal boundary. On Gemma-3-1B-it, CRaFT improves attack success rate (ASR) from 6.7% to 48.2% and outperforms baseline methods across multiple jailbreak benchmarks. These results suggest that circuit influence is a more reliable criterion than activation magnitude for identifying features that causally mediate refusal behavior.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
How Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for LRMs
Jan 07, 2026Large Reasoning Models (LRMs) achieve remarkable success through explicit thinking steps, yet the thinking steps introduce a novel risk by potentially amplifying unsafe behaviors. Despite this vulnerability, conventional defense mechanisms remain ineffective as they overlook the unique reasoning dynamics of LRMs. In this work, we find that the emergence of safe-reminding phrases within thinking steps plays a pivotal role in ensuring LRM safety. Motivated by this finding, we propose SafeRemind, a decoding-time defense method that dynamically injects safe-reminding phrases into thinking steps. By leveraging entropy triggers to intervene at decision-locking points, SafeRemind redirects potentially harmful trajectories toward safer outcomes without requiring any parameter updates. Extensive evaluations across five LRMs and six benchmarks demonstrate that SafeRemind substantially enhances safety, achieving improvements of up to 45.5%p while preserving core reasoning utility.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
AmpleHate: Amplifying the Attention for Versatile Implicit Hate Detection
May 26, 2025Implicit hate speech detection is challenging due to its subtlety and reliance on contextual interpretation rather than explicit offensive words. Current approaches rely on contrastive learning, which are shown to be effective on distinguishing hate and non-hate sentences. Humans, however, detect implicit hate speech by first identifying specific targets within the text and subsequently interpreting how these target relate to their surrounding context. Motivated by this reasoning process, we propose AmpleHate, a novel approach designed to mirror human inference for implicit hate detection. AmpleHate identifies explicit target using a pretrained Named Entity Recognition model and capture implicit target information via [CLS] tokens. It computes attention-based relationships between explicit, implicit targets and sentence context and then, directly injects these relational vectors into the final sentence representation. This amplifies the critical signals of target-context relations for determining implicit hate. Experiments demonstrate that AmpleHate achieves state-of-the-art performance, outperforming contrastive learning baselines by an average of 82.14% and achieve faster convergence. Qualitative analyses further reveal that attention patterns produced by AmpleHate closely align with human judgement, underscoring its interpretability and robustness.
Voicing Personas: Rewriting Persona Descriptions into Style Prompts for Controllable Text-to-Speech
May 21, 2025In this paper, we propose a novel framework to control voice style in prompt-based, controllable text-to-speech systems by leveraging textual personas as voice style prompts. We present two persona rewriting strategies to transform generic persona descriptions into speech-oriented prompts, enabling fine-grained manipulation of prosodic attributes such as pitch, emotion, and speaking rate. Experimental results demonstrate that our methods enhance the naturalness, clarity, and consistency of synthesized speech. Finally, we analyze implicit social biases introduced by LLM-based rewriting, with a focus on gender. We underscore voice style as a crucial factor for persona-driven AI dialogue systems.
Color Flow Imaging Microscopy Improves Identification of Stress Sources of Protein Aggregates in Biopharmaceuticals
Jan 26, 2025Protein-based therapeutics play a pivotal role in modern medicine targeting various diseases. Despite their therapeutic importance, these products can aggregate and form subvisible particles (SvPs), which can compromise their efficacy and trigger immunological responses, emphasizing the critical need for robust monitoring techniques. Flow Imaging Microscopy (FIM) has been a significant advancement in detecting SvPs, evolving from monochrome to more recently incorporating color imaging. Complementing SvP images obtained via FIM, deep learning techniques have recently been employed successfully for stress source identification of monochrome SvPs. In this study, we explore the potential of color FIM to enhance the characterization of stress sources in SvPs. To achieve this, we curate a new dataset comprising 16,000 SvPs from eight commercial monoclonal antibodies subjected to heat and mechanical stress. Using both supervised and self-supervised convolutional neural networks, as well as vision transformers in large-scale experiments, we demonstrate that deep learning with color FIM images consistently outperforms monochrome images, thus highlighting the potential of color FIM in stress source classification compared to its monochrome counterparts.
Real-Time Human Action Recognition on Embedded Platforms
Sep 11, 2024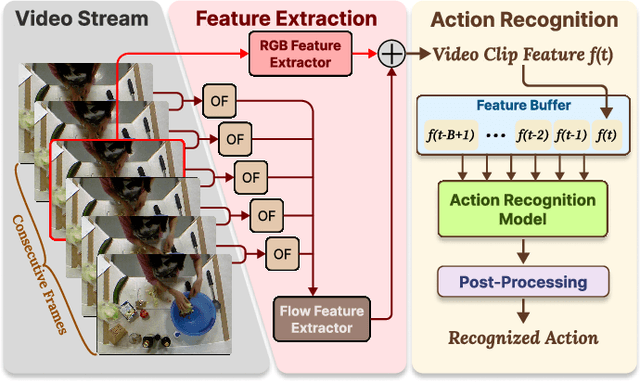
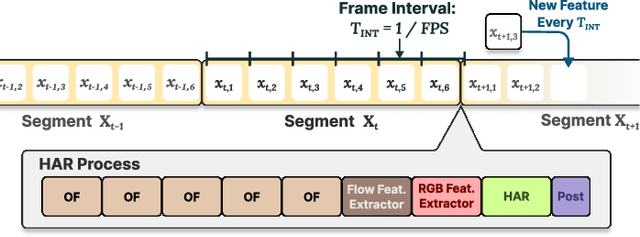
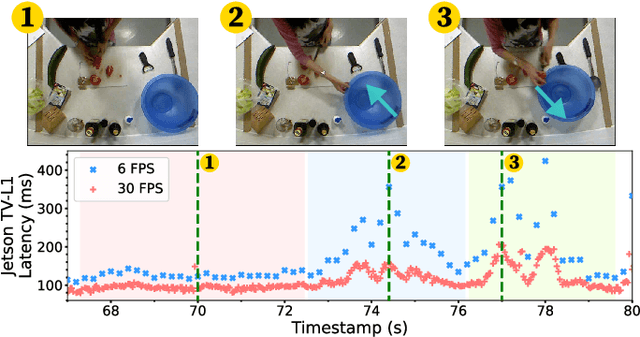
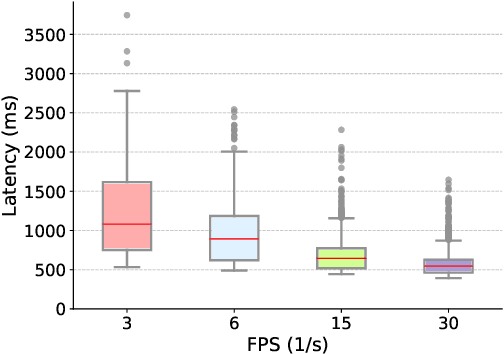
With advancements in computer vision and deep learning, video-based human action recognition (HAR) has become practical. However, due to the complexity of the computation pipeline, running HAR on live video streams incurs excessive delays on embedded platforms. This work tackles the real-time performance challenges of HAR with four contributions: 1) an experimental study identifying a standard Optical Flow (OF) extraction technique as the latency bottleneck in a state-of-the-art HAR pipeline, 2) an exploration of the latency-accuracy tradeoff between the standard and deep learning approaches to OF extraction, which highlights the need for a novel, efficient motion feature extractor, 3) the design of Integrated Motion Feature Extractor (IMFE), a novel single-shot neural network architecture for motion feature extraction with drastic improvement in latency, 4) the development of RT-HARE, a real-time HAR system tailored for embedded platforms. Experimental results on an Nvidia Jetson Xavier NX platform demonstrated that RT-HARE realizes real-time HAR at a video frame rate of 30 frames per second while delivering high levels of recognition accuracy.
Is Flash Attention Stable?
May 05, 2024



Training large-scale machine learning models poses distinct system challenges, given both the size and complexity of today's workloads. Recently, many organizations training state-of-the-art Generative AI models have reported cases of instability during training, often taking the form of loss spikes. Numeric deviation has emerged as a potential cause of this training instability, although quantifying this is especially challenging given the costly nature of training runs. In this work, we develop a principled approach to understanding the effects of numeric deviation, and construct proxies to put observations into context when downstream effects are difficult to quantify. As a case study, we apply this framework to analyze the widely-adopted Flash Attention optimization. We find that Flash Attention sees roughly an order of magnitude more numeric deviation as compared to Baseline Attention at BF16 when measured during an isolated forward pass. We then use a data-driven analysis based on the Wasserstein Distance to provide upper bounds on how this numeric deviation impacts model weights during training, finding that the numerical deviation present in Flash Attention is 2-5 times less significant than low-precision training.
CHAI: Clustered Head Attention for Efficient LLM Inference
Mar 12, 2024



Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute. In our experiments, we show that CHAI is able to reduce the memory requirements for storing K,V cache by up to 21.4% and inference time latency by up to 1.73x without any fine-tuning required. CHAI achieves this with a maximum 3.2% deviation in accuracy across 3 different models (i.e. OPT-66B, LLAMA-7B, LLAMA-33B) and 5 different evaluation datasets.