 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflexive Guidance: Improving OoDD in Vision-Language Models via Self-Guided Image-Adaptive Concept Generation
Oct 19, 2024With the recent emergence of foundation models trained on internet-scale data and demonstrating remarkable generalization capabilities, such foundation models have become more widely adopted, leading to an expanding range of application domains. Despite this rapid proliferation, the trustworthiness of foundation models remains underexplored. Specifically, the out-of-distribution detection (OoDD) capabilities of large vision-language models (LVLMs), such as GPT-4o, which are trained on massive multi-modal data, have not been sufficiently addressed. The disparity between their demonstrated potential and practical reliability raises concerns regarding the safe and trustworthy deployment of foundation models. To address this gap, we evaluate and analyze the OoDD capabilities of various proprietary and open-source LVLMs. Our investigation contributes to a better understanding of how these foundation models represent confidence scores through their generated natural language responses. Based on our observations, we propose a self-guided prompting approach, termed \emph{Reflexive Guidance (ReGuide)}, aimed at enhancing the OoDD capability of LVLMs by leveraging self-generated image-adaptive concept suggestions. Experimental results demonstrate that our ReGuide enhances the performance of current LVLMs in both image classification and OoDD tasks.
Few-shot Fine-tuning is All You Need for Source-free Domain Adaptation
Apr 24, 2023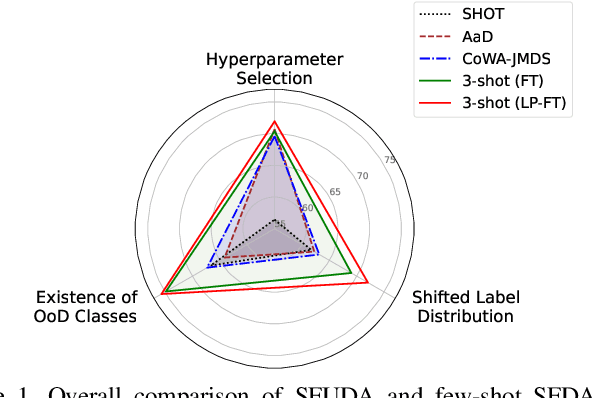
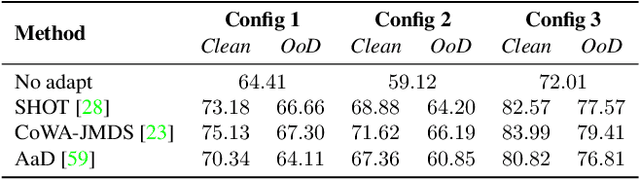
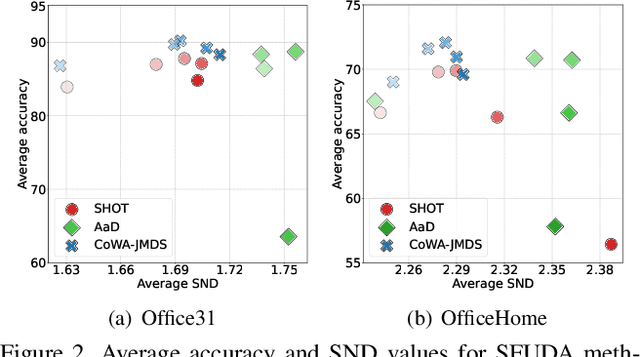
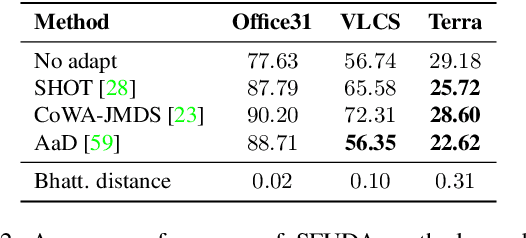
Recently, source-free unsupervised domain adaptation (SFUDA) has emerged as a more practical and feasible approach compared to unsupervised domain adaptation (UDA) which assumes that labeled source data are always accessible. However, significant limitations associated with SFUDA approaches are often overlooked, which limits their practicality in real-world applications. These limitations include a lack of principled ways to determine optimal hyperparameters and performance degradation when the unlabeled target data fail to meet certain requirements such as a closed-set and identical label distribution to the source data. All these limitations stem from the fact that SFUDA entirely relies on unlabeled target data. We empirically demonstrate the limitations of existing SFUDA methods in real-world scenarios including out-of-distribution and label distribution shifts in target data, and verify that none of these methods can be safely applied to real-world settings. Based on our experimental results, we claim that fine-tuning a source pretrained model with a few labeled data (e.g., 1- or 3-shot) is a practical and reliable solution to circumvent the limitations of SFUDA. Contrary to common belief, we find that carefully fine-tuned models do not suffer from overfitting even when trained with only a few labeled data, and also show little change in performance due to sampling bias. Our experimental results on various domain adaptation benchmarks demonstrate that the few-shot fine-tuning approach performs comparatively under the standard SFUDA settings, and outperforms comparison methods under realistic scenarios. Our code is available at https://github.com/daintlab/fewshot-SFDA .
Deep Active Learning with Contrastive Learning Under Realistic Data Pool Assumptions
Mar 25, 2023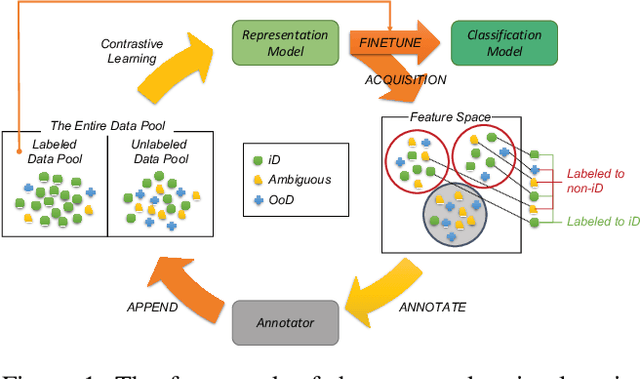
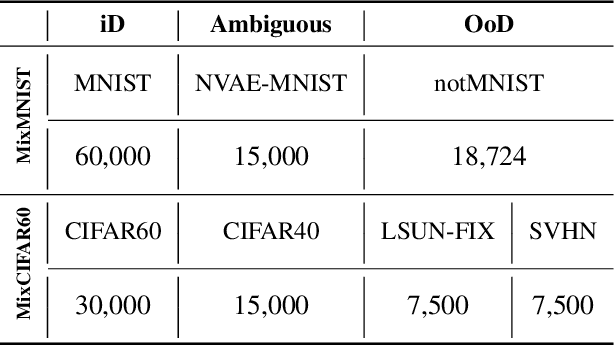
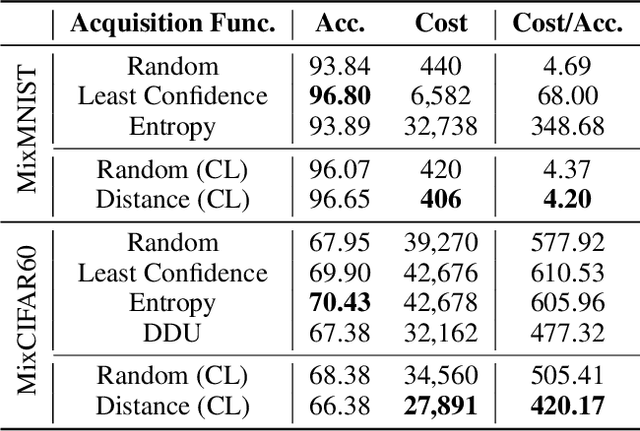
Active learning aims to identify the most informative data from an unlabeled data pool that enables a model to reach the desired accuracy rapidly. This benefits especially deep neural networks which generally require a huge number of labeled samples to achieve high performance. Most existing active learning methods have been evaluated in an ideal setting where only samples relevant to the target task, i.e., in-distribution samples, exist in an unlabeled data pool. A data pool gathered from the wild, however, is likely to include samples that are irrelevant to the target task at all and/or too ambiguous to assign a single class label even for the oracle. We argue that assuming an unlabeled data pool consisting of samples from various distributions is more realistic. In this work, we introduce new active learning benchmarks that include ambiguous, task-irrelevant out-of-distribution as well as in-distribution samples. We also propose an active learning method designed to acquire informative in-distribution samples in priority. The proposed method leverages both labeled and unlabeled data pools and selects samples from clusters on the feature space constructed via contrastive learning. Experimental results demonstrate that the proposed method requires a lower annotation budget than existing active learning methods to reach the same level of accuracy.
A Unified Benchmark for the Unknown Detection Capability of Deep Neural Networks
Dec 01, 2021



Deep neural networks have achieved outstanding performance over various tasks, but they have a critical issue: over-confident predictions even for completely unknown samples. Many studies have been proposed to successfully filter out these unknown samples, but they only considered narrow and specific tasks, referred to as misclassification detection, open-set recognition, or out-of-distribution detection. In this work, we argue that these tasks should be treated as fundamentally an identical problem because an ideal model should possess detection capability for all those tasks. Therefore, we introduce the unknown detection task, an integration of previous individual tasks, for a rigorous examination of the detection capability of deep neural networks on a wide spectrum of unknown samples. To this end, unified benchmark datasets on different scales were constructed and the unknown detection capabilities of existing popular methods were subject to comparison. We found that Deep Ensemble consistently outperforms the other approaches in detecting unknowns; however, all methods are only successful for a specific type of unknown. The reproducible code and benchmark datasets are available at https://github.com/daintlab/unknown-detection-benchmarks .
Confidence-Aware Learning for Deep Neural Networks
Jul 07, 2020
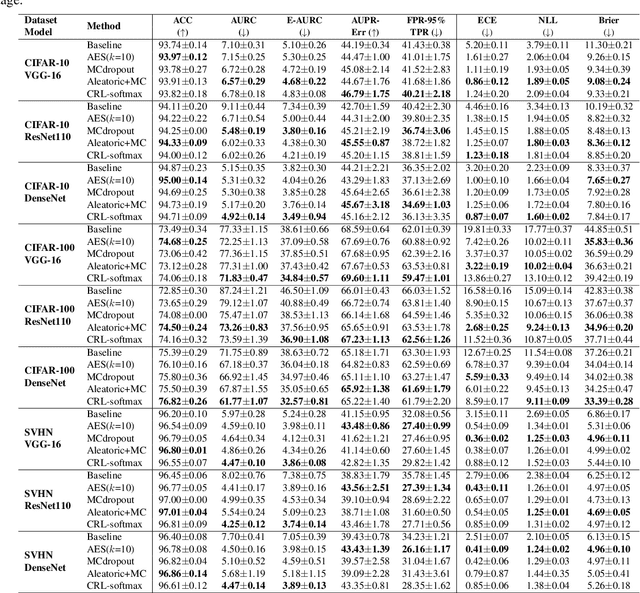
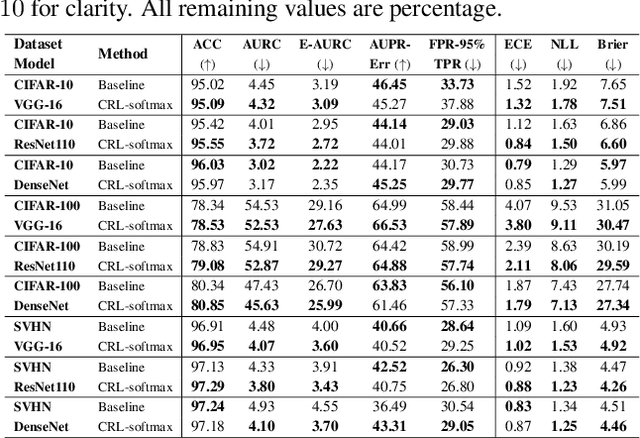
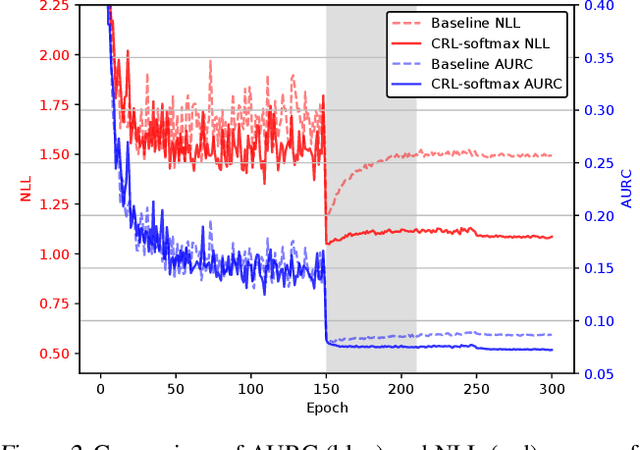
Despite the power of deep neural networks for a wide range of tasks, an overconfident prediction issue has limited their practical use in many safety-critical applications. Many recent works have been proposed to mitigate this issue, but most of them require either additional computational costs in training and/or inference phases or customized architectures to output confidence estimates separately. In this paper, we propose a method of training deep neural networks with a novel loss function, named Correctness Ranking Loss, which regularizes class probabilities explicitly to be better confidence estimates in terms of ordinal ranking according to confidence. The proposed method is easy to implement and can be applied to the existing architectures without any modification. Also, it has almost the same computational costs for training as conventional deep classifiers and outputs reliable predictions by a single inference. Extensive experimental results on classification benchmark datasets indicate that the proposed method helps networks to produce well-ranked confidence estimates. We also demonstrate that it is effective for the tasks closely related to confidence estimation, out-of-distribution detection and active learning.