 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochCA: A Novel Approach for Exploiting Pretrained Models with Cross-Attention
Feb 25, 2024



Utilizing large-scale pretrained models is a well-known strategy to enhance performance on various target tasks. It is typically achieved through fine-tuning pretrained models on target tasks. However, na\"{\i}ve fine-tuning may not fully leverage knowledge embedded in pretrained models. In this study, we introduce a novel fine-tuning method, called stochastic cross-attention (StochCA), specific to Transformer architectures. This method modifies the Transformer's self-attention mechanism to selectively utilize knowledge from pretrained models during fine-tuning. Specifically, in each block, instead of self-attention, cross-attention is performed stochastically according to the predefined probability, where keys and values are extracted from the corresponding block of a pretrained model. By doing so, queries and channel-mixing multi-layer perceptron layers of a target model are fine-tuned to target tasks to learn how to effectively exploit rich representations of pretrained models. To verify the effectiveness of StochCA, extensive experiments are conducted on benchmarks in the areas of transfer learning and domain generalization, where the exploitation of pretrained models is critical. Our experimental results show the superiority of StochCA over state-of-the-art approaches in both areas. Furthermore, we demonstrate that StochCA is complementary to existing approaches, i.e., it can be combined with them to further improve performance. Our code is available at https://github.com/daintlab/stochastic_cross_attention
Few-shot Fine-tuning is All You Need for Source-free Domain Adaptation
Apr 24, 2023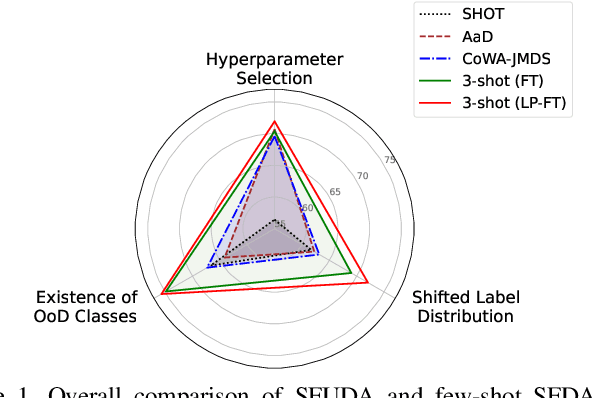
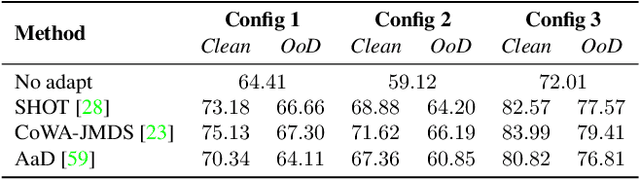
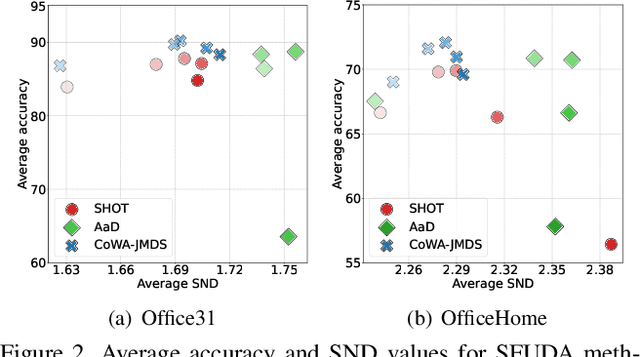
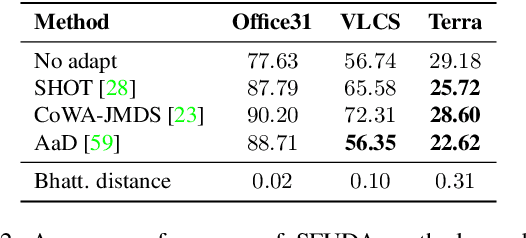
Recently, source-free unsupervised domain adaptation (SFUDA) has emerged as a more practical and feasible approach compared to unsupervised domain adaptation (UDA) which assumes that labeled source data are always accessible. However, significant limitations associated with SFUDA approaches are often overlooked, which limits their practicality in real-world applications. These limitations include a lack of principled ways to determine optimal hyperparameters and performance degradation when the unlabeled target data fail to meet certain requirements such as a closed-set and identical label distribution to the source data. All these limitations stem from the fact that SFUDA entirely relies on unlabeled target data. We empirically demonstrate the limitations of existing SFUDA methods in real-world scenarios including out-of-distribution and label distribution shifts in target data, and verify that none of these methods can be safely applied to real-world settings. Based on our experimental results, we claim that fine-tuning a source pretrained model with a few labeled data (e.g., 1- or 3-shot) is a practical and reliable solution to circumvent the limitations of SFUDA. Contrary to common belief, we find that carefully fine-tuned models do not suffer from overfitting even when trained with only a few labeled data, and also show little change in performance due to sampling bias. Our experimental results on various domain adaptation benchmarks demonstrate that the few-shot fine-tuning approach performs comparatively under the standard SFUDA settings, and outperforms comparison methods under realistic scenarios. Our code is available at https://github.com/daintlab/fewshot-SFDA .