 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Active Learning with Contrastive Learning Under Realistic Data Pool Assumptions
Paper and Code
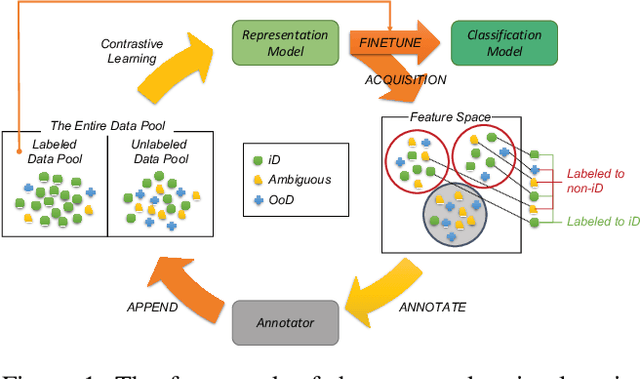
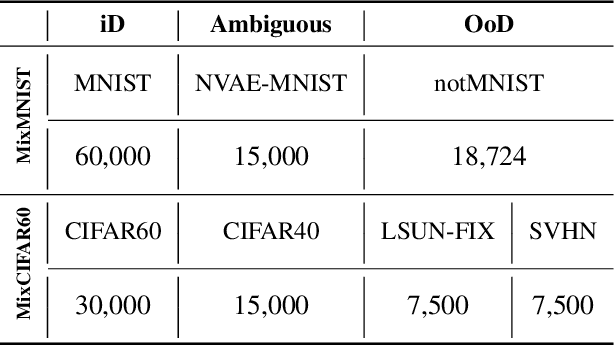
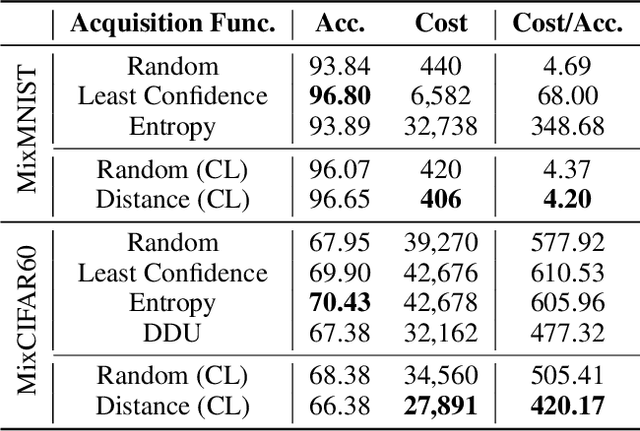
Active learning aims to identify the most informative data from an unlabeled data pool that enables a model to reach the desired accuracy rapidly. This benefits especially deep neural networks which generally require a huge number of labeled samples to achieve high performance. Most existing active learning methods have been evaluated in an ideal setting where only samples relevant to the target task, i.e., in-distribution samples, exist in an unlabeled data pool. A data pool gathered from the wild, however, is likely to include samples that are irrelevant to the target task at all and/or too ambiguous to assign a single class label even for the oracle. We argue that assuming an unlabeled data pool consisting of samples from various distributions is more realistic. In this work, we introduce new active learning benchmarks that include ambiguous, task-irrelevant out-of-distribution as well as in-distribution samples. We also propose an active learning method designed to acquire informative in-distribution samples in priority. The proposed method leverages both labeled and unlabeled data pools and selects samples from clusters on the feature space constructed via contrastive learning. Experimental results demonstrate that the proposed method requires a lower annotation budget than existing active learning methods to reach the same level of accuracy.