 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Pathomic Learning Defines Prognostic Subtypes and Molecular Drivers in Colorectal Cancer
Nov 19, 2025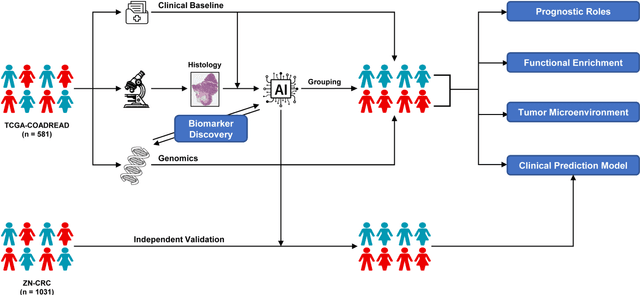
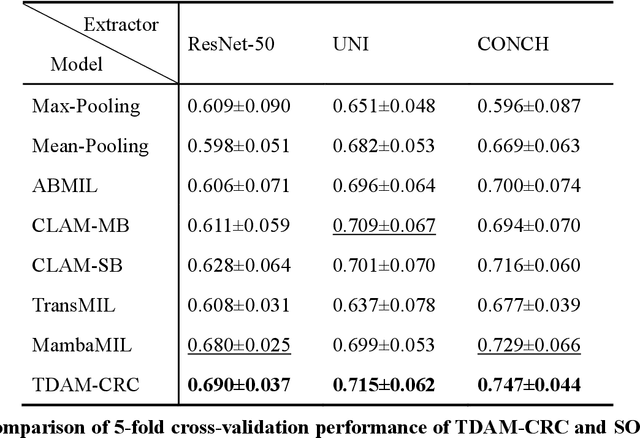
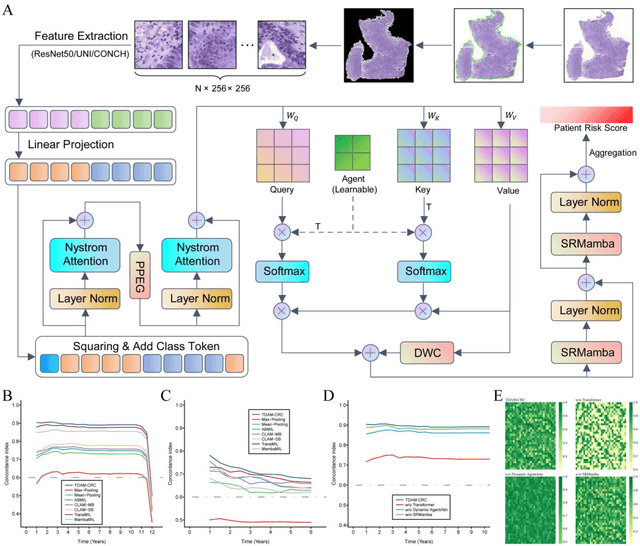
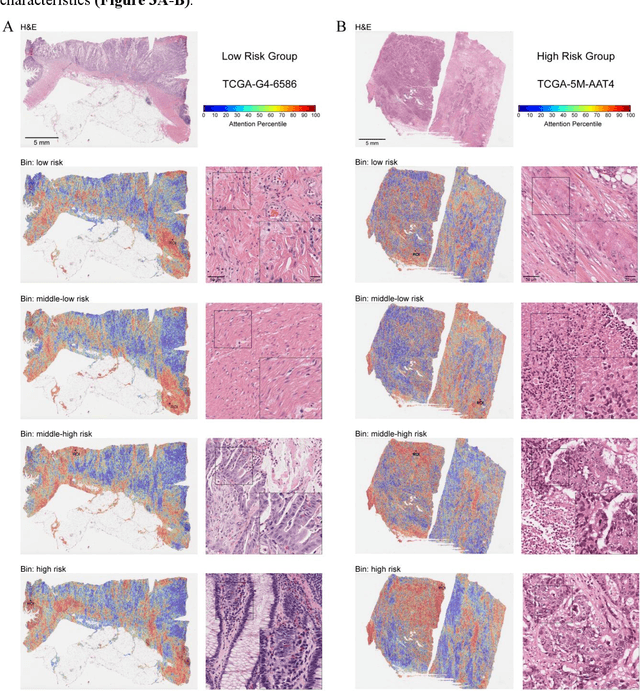
Precise prognostic stratification of colorectal cancer (CRC) remains a major clinical challenge due to its high heterogeneity. The conventional TNM staging system is inadequate for personalized medicine. We aimed to develop and validate a novel multiple instance learning model TDAM-CRC using histopathological whole-slide images for accurate prognostic prediction and to uncover its underlying molecular mechanisms. We trained the model on the TCGA discovery cohort (n=581), validated it in an independent external cohort (n=1031), and further we integrated multi-omics data to improve model interpretability and identify novel prognostic biomarkers. The results demonstrated that the TDAM-CRC achieved robust risk stratification in both cohorts. Its predictive performance significantly outperformed the conventional clinical staging system and multiple state-of-the-art models. The TDAM-CRC risk score was confirmed as an independent prognostic factor in multivariable analysis. Multi-omics analysis revealed that the high-risk subtype is closely associated with metabolic reprogramming and an immunosuppressive tumor microenvironment. Through interaction network analysis, we identified and validated Mitochondrial Ribosomal Protein L37 (MRPL37) as a key hub gene linking deep pathomic features to clinical prognosis. We found that high expression of MRPL37, driven by promoter hypomethylation, serves as an independent biomarker of favorable prognosis. Finally, we constructed a nomogram incorporating the TDAM-CRC risk score and clinical factors to provide a precise and interpretable clinical decision-making tool for CRC patients. Our AI-driven pathological model TDAM-CRC provides a robust tool for improved CRC risk stratification, reveals new molecular targets, and facilitates personalized clinical decision-making.
Real-Time Human Action Recognition on Embedded Platforms
Sep 11, 2024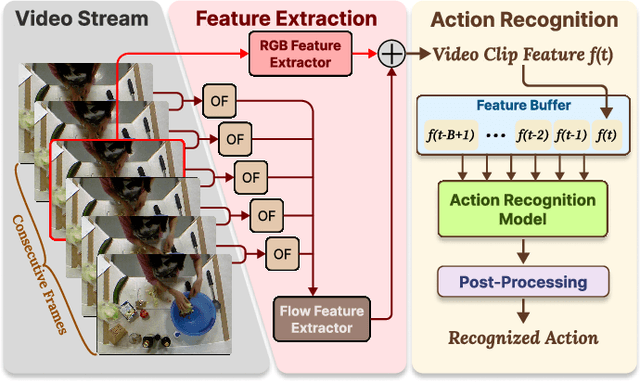
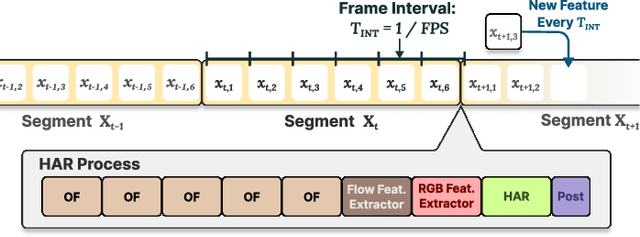
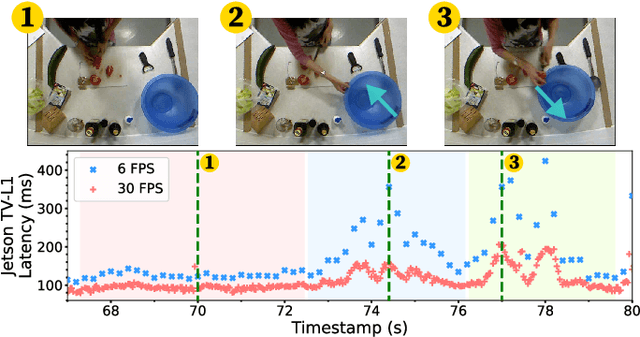
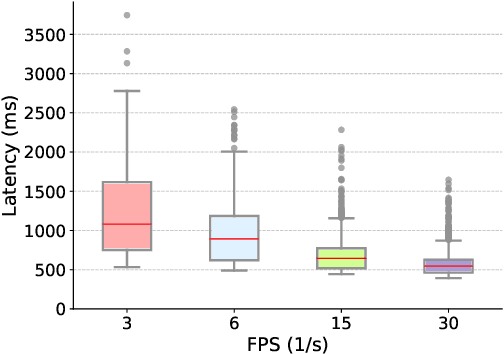
With advancements in computer vision and deep learning, video-based human action recognition (HAR) has become practical. However, due to the complexity of the computation pipeline, running HAR on live video streams incurs excessive delays on embedded platforms. This work tackles the real-time performance challenges of HAR with four contributions: 1) an experimental study identifying a standard Optical Flow (OF) extraction technique as the latency bottleneck in a state-of-the-art HAR pipeline, 2) an exploration of the latency-accuracy tradeoff between the standard and deep learning approaches to OF extraction, which highlights the need for a novel, efficient motion feature extractor, 3) the design of Integrated Motion Feature Extractor (IMFE), a novel single-shot neural network architecture for motion feature extraction with drastic improvement in latency, 4) the development of RT-HARE, a real-time HAR system tailored for embedded platforms. Experimental results on an Nvidia Jetson Xavier NX platform demonstrated that RT-HARE realizes real-time HAR at a video frame rate of 30 frames per second while delivering high levels of recognition accuracy.
Learning by Planning: Language-Guided Global Image Editing
Jun 24, 2021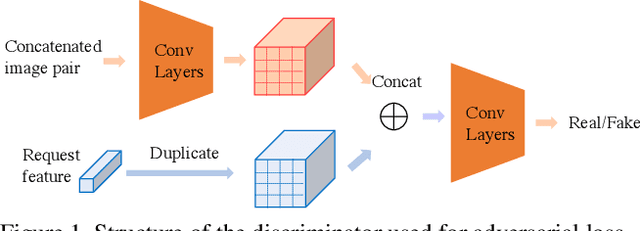
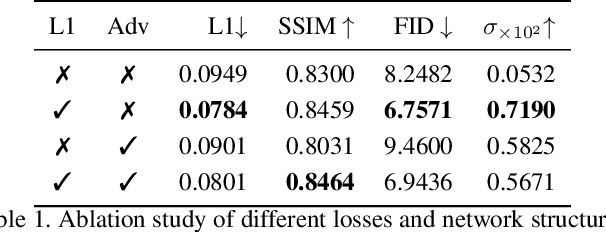
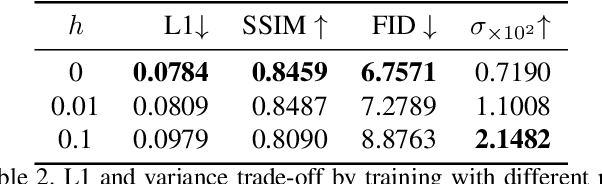

Recently, language-guided global image editing draws increasing attention with growing application potentials. However, previous GAN-based methods are not only confined to domain-specific, low-resolution data but also lacking in interpretability. To overcome the collective difficulties, we develop a text-to-operation model to map the vague editing language request into a series of editing operations, e.g., change contrast, brightness, and saturation. Each operation is interpretable and differentiable. Furthermore, the only supervision in the task is the target image, which is insufficient for a stable training of sequential decisions. Hence, we propose a novel operation planning algorithm to generate possible editing sequences from the target image as pseudo ground truth. Comparison experiments on the newly collected MA5k-Req dataset and GIER dataset show the advantages of our methods. Code is available at https://jshi31.github.io/T2ONet.
Actor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020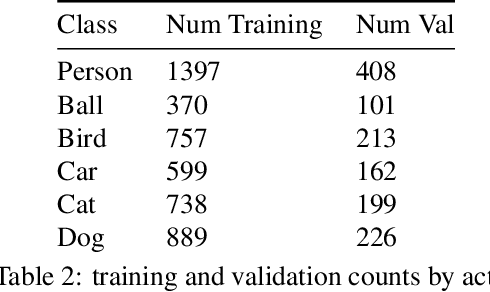
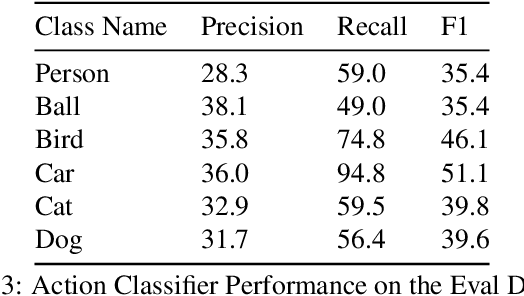
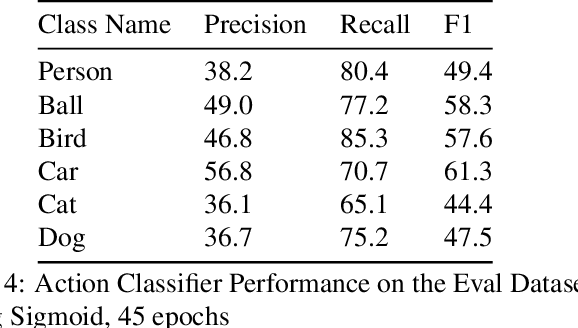
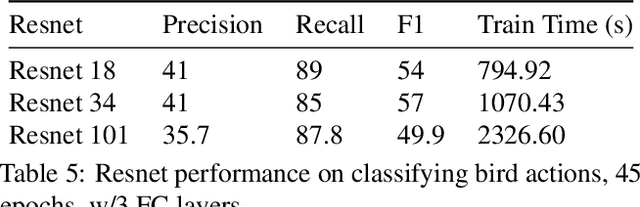
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester