 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020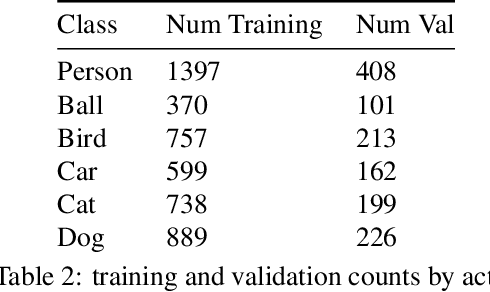
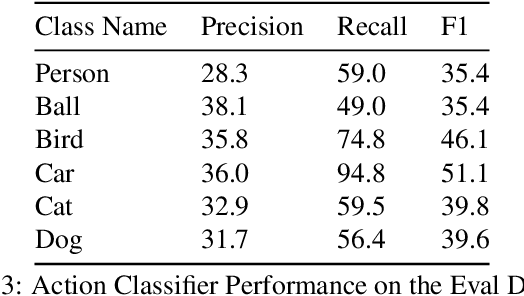
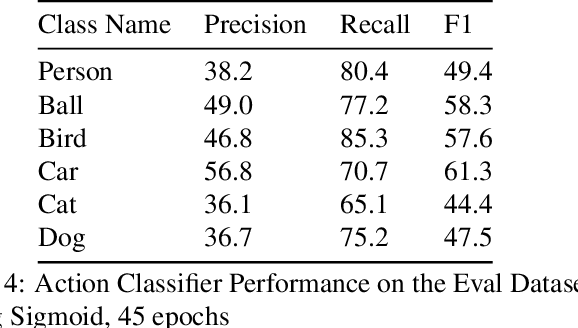
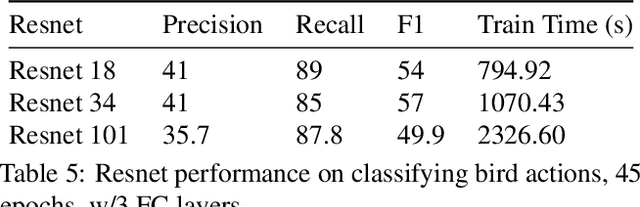
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester
Learning from Interventions using Hierarchical Policies for Safe Learning
Dec 04, 2019


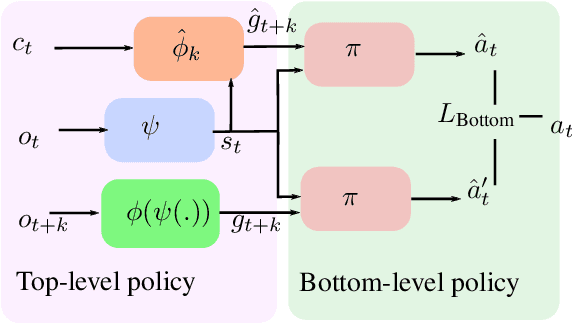
Learning from Demonstrations (LfD) via Behavior Cloning (BC) works well on multiple complex tasks. However, a limitation of the typical LfD approach is that it requires expert demonstrations for all scenarios, including those in which the algorithm is already well-trained. The recently proposed Learning from Interventions (LfI) overcomes this limitation by using an expert overseer. The expert overseer only intervenes when it suspects that an unsafe action is about to be taken. Although LfI significantly improves over LfD, the state-of-the-art LfI fails to account for delay caused by the expert's reaction time and only learns short-term behavior. We address these limitations by 1) interpolating the expert's interventions back in time, and 2) by splitting the policy into two hierarchical levels, one that generates sub-goals for the future and another that generates actions to reach those desired sub-goals. This sub-goal prediction forces the algorithm to learn long-term behavior while also being robust to the expert's reaction time. Our experiments show that LfI using sub-goals in a hierarchical policy framework trains faster and achieves better asymptotic performance than typical LfD.
Navigation by Imitation in a Pedestrian-Rich Environment
Nov 01, 2018
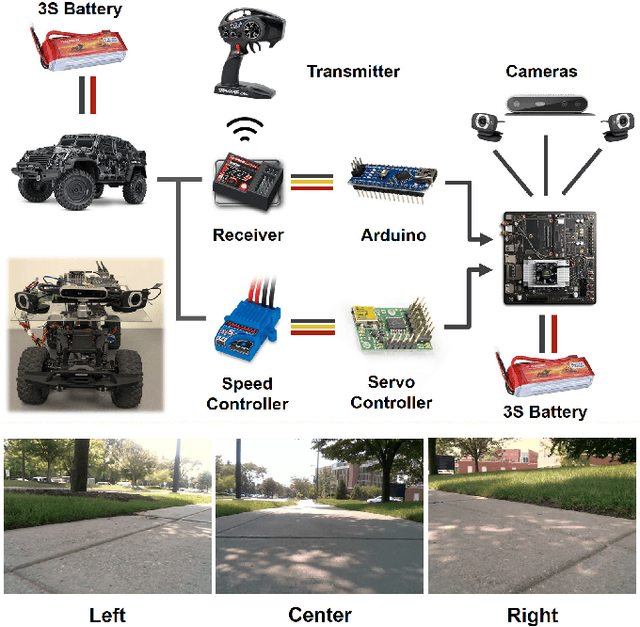
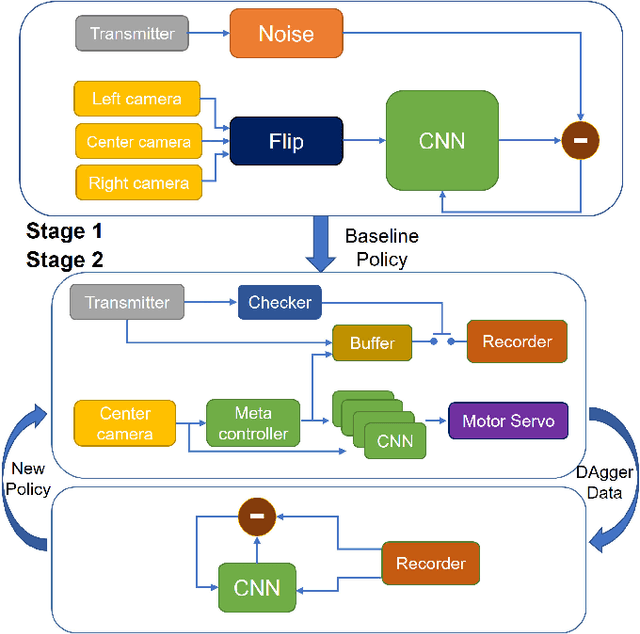
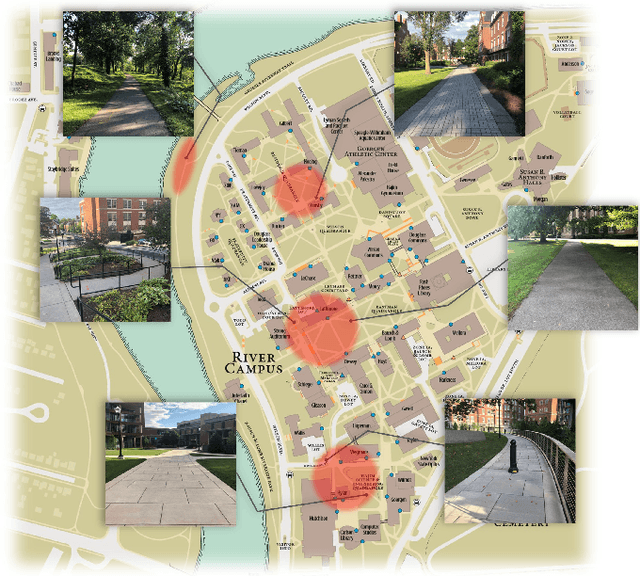
Deep neural networks trained on demonstrations of human actions give robot the ability to perform self-driving on the road. However, navigation in a pedestrian-rich environment, such as a campus setup, is still challenging---one needs to take frequent interventions to the robot and take control over the robot from early steps leading to a mistake. An arduous burden is, hence, placed on the learning framework design and data acquisition. In this paper, we propose a new learning-from-intervention Dataset Aggregation (DAgger) algorithm to overcome the limitations brought by applying imitation learning to navigation in the pedestrian-rich environment. Our new learning algorithm implements an error backtrack function that is able to effectively learn from expert interventions. Combining our new learning algorithm with deep convolutional neural networks and a hierarchically-nested policy-selection mechanism, we show that our robot is able to map pixels direct to control commands and navigate successfully in real world without explicitly modeling the pedestrian behaviors or the world model.