 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSteering Language Models Before They Speak: Logit-Level Interventions
Jan 16, 2026Steering LLMs is essential for specialized applications such as style-sensitive text rewriting, user-adaptive communication, and toxicity mitigation. Current steering methods, such as prompting-based and activation-based approaches, are widely used to guide model behavior. However, activation-based techniques require deep access to internal layers, while prompting-based steering often fails to provide consistent or fine-grained control. In order to address these limitations, we propose a training-free inference-time logit intervention for controllable generation. Our approach utilizes a statistical token score table derived from z-normalized log-odds of labeled corpora to shift the decoding distribution. Empirical evaluations across three diverse datasets focusing on writing complexity, formality, and toxicity demonstrate that our method effectively steers output characteristics, confirming its broad applicability and task-agnostic nature. Our results show that statistically grounded logit steering can achieve large, consistent, and multi-task control gains: up to +47%p accuracy and 50x f1 improvement.
How Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for LRMs
Jan 07, 2026Large Reasoning Models (LRMs) achieve remarkable success through explicit thinking steps, yet the thinking steps introduce a novel risk by potentially amplifying unsafe behaviors. Despite this vulnerability, conventional defense mechanisms remain ineffective as they overlook the unique reasoning dynamics of LRMs. In this work, we find that the emergence of safe-reminding phrases within thinking steps plays a pivotal role in ensuring LRM safety. Motivated by this finding, we propose SafeRemind, a decoding-time defense method that dynamically injects safe-reminding phrases into thinking steps. By leveraging entropy triggers to intervene at decision-locking points, SafeRemind redirects potentially harmful trajectories toward safer outcomes without requiring any parameter updates. Extensive evaluations across five LRMs and six benchmarks demonstrate that SafeRemind substantially enhances safety, achieving improvements of up to 45.5%p while preserving core reasoning utility.
WaterMod: Modular Token-Rank Partitioning for Probability-Balanced LLM Watermarking
Nov 13, 2025



Large language models now draft news, legal analyses, and software code with human-level fluency. At the same time, regulations such as the EU AI Act mandate that each synthetic passage carry an imperceptible, machine-verifiable mark for provenance. Conventional logit-based watermarks satisfy this requirement by selecting a pseudorandom green vocabulary at every decoding step and boosting its logits, yet the random split can exclude the highest-probability token and thus erode fluency. WaterMod mitigates this limitation through a probability-aware modular rule. The vocabulary is first sorted in descending model probability; the resulting ranks are then partitioned by the residue rank mod k, which distributes adjacent-and therefore semantically similar-tokens across different classes. A fixed bias of small magnitude is applied to one selected class. In the zero-bit setting (k=2), an entropy-adaptive gate selects either the even or the odd parity as the green list. Because the top two ranks fall into different parities, this choice embeds a detectable signal while guaranteeing that at least one high-probability token remains available for sampling. In the multi-bit regime (k>2), the current payload digit d selects the color class whose ranks satisfy rank mod k = d. Biasing the logits of that class embeds exactly one base-k digit per decoding step, thereby enabling fine-grained provenance tracing. The same modular arithmetic therefore supports both binary attribution and rich payloads. Experimental results demonstrate that WaterMod consistently attains strong watermark detection performance while maintaining generation quality in both zero-bit and multi-bit settings. This robustness holds across a range of tasks, including natural language generation, mathematical reasoning, and code synthesis. Our code and data are available at https://github.com/Shinwoo-Park/WaterMod.
AmpleHate: Amplifying the Attention for Versatile Implicit Hate Detection
May 26, 2025Implicit hate speech detection is challenging due to its subtlety and reliance on contextual interpretation rather than explicit offensive words. Current approaches rely on contrastive learning, which are shown to be effective on distinguishing hate and non-hate sentences. Humans, however, detect implicit hate speech by first identifying specific targets within the text and subsequently interpreting how these target relate to their surrounding context. Motivated by this reasoning process, we propose AmpleHate, a novel approach designed to mirror human inference for implicit hate detection. AmpleHate identifies explicit target using a pretrained Named Entity Recognition model and capture implicit target information via [CLS] tokens. It computes attention-based relationships between explicit, implicit targets and sentence context and then, directly injects these relational vectors into the final sentence representation. This amplifies the critical signals of target-context relations for determining implicit hate. Experiments demonstrate that AmpleHate achieves state-of-the-art performance, outperforming contrastive learning baselines by an average of 82.14% and achieve faster convergence. Qualitative analyses further reveal that attention patterns produced by AmpleHate closely align with human judgement, underscoring its interpretability and robustness.
LogiCase: Effective Test Case Generation from Logical Description in Competitive Programming
May 21, 2025Automated Test Case Generation (ATCG) is crucial for evaluating software reliability, particularly in competitive programming where robust algorithm assessments depend on diverse and accurate test cases. However, existing ATCG methods often fail to meet complex specifications or generate effective corner cases, limiting their utility. In this work, we introduce Context-Free Grammars with Counters (CCFGs), a formalism that captures both syntactic and semantic structures in input specifications. Using a fine-tuned CodeT5 model, we translate natural language input specifications into CCFGs, enabling the systematic generation of high-quality test cases. Experiments on the CodeContests dataset demonstrate that CCFG-based test cases outperform baseline methods in identifying incorrect algorithms, achieving significant gains in validity and effectiveness. Our approach provides a scalable and reliable grammar-driven framework for enhancing automated competitive programming evaluations.
Marking Code Without Breaking It: Code Watermarking for Detecting LLM-Generated Code
Feb 26, 2025
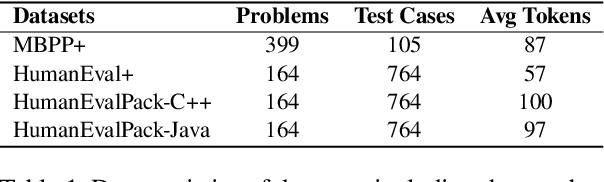


Code watermarking identifies AI-generated code by embedding patterns into the code during generation. Effective watermarking requires meeting two key conditions: the watermark should be reliably detectable, and the code should retain its original functionality. However, existing methods often modify tokens that are critical for program logic, such as keywords in conditional expressions or operators in arithmetic computations. These modifications can cause syntax errors or functional failures, limiting the practical use of watermarking. We present STONE, a method that preserves functional integrity by selectively inserting watermarks only into non-syntax tokens. By excluding tokens essential for code execution, STONE minimizes the risk of functional degradation. In addition, we introduce CWEM, a comprehensive evaluation metric that evaluates watermarking techniques based on correctness, detectability, and naturalness. While correctness and detectability have been widely used, naturalness remains underexplored despite its importance. Unnatural patterns can reveal the presence of a watermark, making it easier for adversaries to remove. We evaluate STONE using CWEM and compare its performance with the state-of-the-art approach. The results show that STONE achieves an average improvement of 7.69% in CWEM across Python, C++, and Java. Our code is available in https://github.com/inistory/STONE-watermarking/.
Detection of LLM-Paraphrased Code and Identification of the Responsible LLM Using Coding Style Features
Feb 25, 2025Recent progress in large language models (LLMs) for code generation has raised serious concerns about intellectual property protection. Malicious users can exploit LLMs to produce paraphrased versions of proprietary code that closely resemble the original. While the potential for LLM-assisted code paraphrasing continues to grow, research on detecting it remains limited, underscoring an urgent need for detection system. We respond to this need by proposing two tasks. The first task is to detect whether code generated by an LLM is a paraphrased version of original human-written code. The second task is to identify which LLM is used to paraphrase the original code. For these tasks, we construct a dataset LPcode consisting of pairs of human-written code and LLM-paraphrased code using various LLMs. We statistically confirm significant differences in the coding styles of human-written and LLM-paraphrased code, particularly in terms of naming consistency, code structure, and readability. Based on these findings, we develop LPcodedec, a detection method that identifies paraphrase relationships between human-written and LLM-generated code, and discover which LLM is used for the paraphrasing. LPcodedec outperforms the best baselines in two tasks, improving F1 scores by 2.64% and 15.17% while achieving speedups of 1,343x and 213x, respectively.
URECA: The Chain of Two Minimum Set Cover Problems exists behind Adaptation to Shifts in Semantic Code Search
Feb 11, 2025Adaptation is to make model learn the patterns shifted from the training distribution. In general, this adaptation is formulated as the minimum entropy problem. However, the minimum entropy problem has inherent limitation -- shifted initialization cascade phenomenon. We extend the relationship between the minimum entropy problem and the minimum set cover problem via Lebesgue integral. This extension reveals that internal mechanism of the minimum entropy problem ignores the relationship between disentangled representations, which leads to shifted initialization cascade. From the analysis, we introduce a new clustering algorithm, Union-find based Recursive Clustering Algorithm~(URECA). URECA is an efficient clustering algorithm for the leverage of the relationships between disentangled representations. The update rule of URECA depends on Thresholdly-Updatable Stationary Assumption to dynamics as a released version of Stationary Assumption. This assumption helps URECA to transport disentangled representations with no errors based on the relationships between disentangled representations. URECA also utilize simulation trick to efficiently cluster disentangled representations. The wide range of evaluations show that URECA achieves consistent performance gains for the few-shot adaptation to diverse types of shifts along with advancement to State-of-The-Art performance in CoSQA in the scenario of query shift.
A Framework for Quantum Finite-State Languages with Density Mapping
Jul 03, 2024A quantum finite-state automaton (QFA) is a theoretical model designed to simulate the evolution of a quantum system with finite memory in response to sequential input strings. We define the language of a QFA as the set of strings that lead the QFA to an accepting state when processed from its initial state. QFAs exemplify how quantum computing can achieve greater efficiency compared to classical computing. While being one of the simplest quantum models, QFAs are still notably challenging to construct from scratch due to the preliminary knowledge of quantum mechanics required for superimposing unitary constraints on the automata. Furthermore, even when QFAs are correctly assembled, the limitations of a current quantum computer may cause fluctuations in the simulation results depending on how an assembled QFA is translated into a quantum circuit. We present a framework that provides a simple and intuitive way to build QFAs and maximize the simulation accuracy. Our framework relies on two methods: First, it offers a predefined construction for foundational types of QFAs that recognize special languages MOD and EQU. They play a role of basic building blocks for more complex QFAs. In other words, one can obtain more complex QFAs from these foundational automata using standard language operations. Second, we improve the simulation accuracy by converting these QFAs into quantum circuits such that the resulting circuits perform well on noisy quantum computers. Our framework is available at https://github.com/sybaik1/qfa-toolkit.
ATHENA: Mathematical Reasoning with Thought Expansion
Nov 02, 2023Solving math word problems depends on how to articulate the problems, the lens through which models view human linguistic expressions. Real-world settings count on such a method even more due to the diverse practices of the same mathematical operations. Earlier works constrain available thinking processes by limited prediction strategies without considering their significance in acquiring mathematical knowledge. We introduce Attention-based THought Expansion Network Architecture (ATHENA) to tackle the challenges of real-world practices by mimicking human thought expansion mechanisms in the form of neural network propagation. A thought expansion recurrently generates the candidates carrying the thoughts of possible math expressions driven from the previous step and yields reasonable thoughts by selecting the valid pathways to the goal. Our experiments show that ATHENA achieves a new state-of-the-art stage toward the ideal model that is compelling in variant questions even when the informativeness in training examples is restricted.