 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle LLM Debate, MoLaCE: Mixture of Latent Concept Experts Against Confirmation Bias
Dec 29, 2025Large language models (LLMs) are highly vulnerable to input confirmation bias. When a prompt implies a preferred answer, models often reinforce that bias rather than explore alternatives. This phenomenon remains underexplored, yet it is already harmful in base models and poses an even greater risk in multi-agent debate, where echo chambers reinforce bias instead of correction. We introduce Mixture of Latent Concept Experts (MoLaCE), a lightweight inference-time framework that addresses confirmation bias by mixing experts instantiated as different activation strengths over latent concepts that shape model responses. Our key insight is that, due to the compositional nature of language, differently phrased prompts reweight latent concepts in prompt-specific ways that affect factual correctness, so no single fixed intervention can be applied universally across inputs. This design enables a single LLM to emulate the benefits of debate internally while remaining computationally efficient and scalable. It can also be integrated into multi-agent debate frameworks to diversify perspectives and reduce correlated errors. We empirically show that it consistently reduces confirmation bias, improves robustness, and matches or surpasses multi-agent debate while requiring only a fraction of the computation.
Detecting LLM Hallucination Through Layer-wise Information Deficiency: Analysis of Unanswerable Questions and Ambiguous Prompts
Dec 13, 2024



Large language models (LLMs) frequently generate confident yet inaccurate responses, introducing significant risks for deployment in safety-critical domains. We present a novel approach to detecting model hallucination through systematic analysis of information flow across model layers when processing inputs with insufficient or ambiguous context. Our investigation reveals that hallucination manifests as usable information deficiencies in inter-layer transmissions. While existing approaches primarily focus on final-layer output analysis, we demonstrate that tracking cross-layer information dynamics ($\mathcal{L}$I) provides robust indicators of model reliability, accounting for both information gain and loss during computation. $\mathcal{L}$I improves model reliability by immediately integrating with universal LLMs without additional training or architectural modifications.
AURA: Natural Language Reasoning for Aleatoric Uncertainty in Rationales
Feb 22, 2024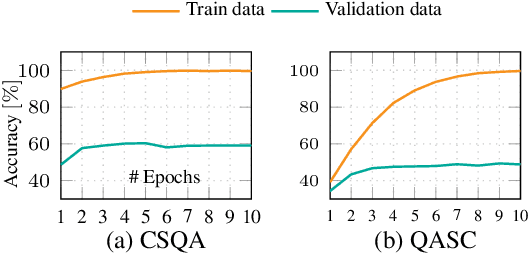
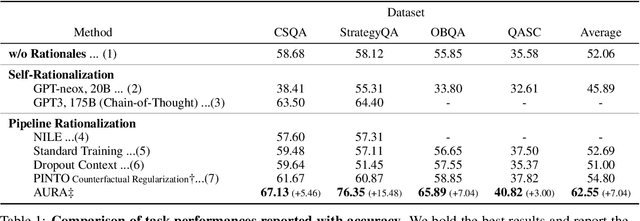
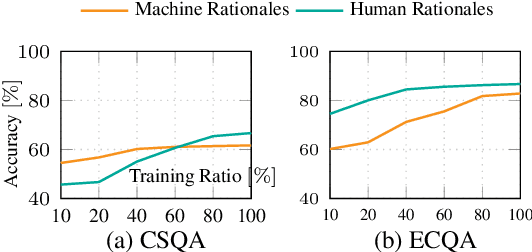
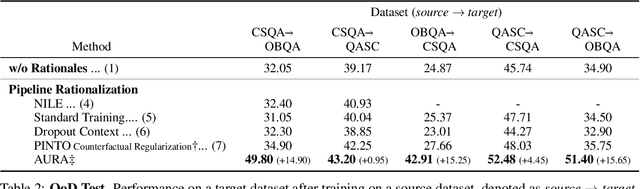
Rationales behind answers not only explain model decisions but boost language models to reason well on complex reasoning tasks. However, obtaining impeccable rationales is often impossible. Besides, it is non-trivial to estimate the degree to which the rationales are faithful enough to encourage model performance. Thus, such reasoning tasks often compel models to output correct answers under undesirable rationales and are sub-optimal compared to what the models are fully capable of. In this work, we propose how to deal with imperfect rationales causing aleatoric uncertainty. We first define the ambiguous rationales with entropy scores of given rationales, using model prior beliefs as informativeness. We then guide models to select one of two different reasoning models according to the ambiguity of rationales. We empirically argue that our proposed method produces robust performance superiority against the adversarial quality of rationales and low-resource settings.
ATHENA: Mathematical Reasoning with Thought Expansion
Nov 02, 2023Solving math word problems depends on how to articulate the problems, the lens through which models view human linguistic expressions. Real-world settings count on such a method even more due to the diverse practices of the same mathematical operations. Earlier works constrain available thinking processes by limited prediction strategies without considering their significance in acquiring mathematical knowledge. We introduce Attention-based THought Expansion Network Architecture (ATHENA) to tackle the challenges of real-world practices by mimicking human thought expansion mechanisms in the form of neural network propagation. A thought expansion recurrently generates the candidates carrying the thoughts of possible math expressions driven from the previous step and yields reasonable thoughts by selecting the valid pathways to the goal. Our experiments show that ATHENA achieves a new state-of-the-art stage toward the ideal model that is compelling in variant questions even when the informativeness in training examples is restricted.
LST: Lexicon-Guided Self-Training for Few-Shot Text Classification
Feb 05, 2022Self-training provides an effective means of using an extremely small amount of labeled data to create pseudo-labels for unlabeled data. Many state-of-the-art self-training approaches hinge on different regularization methods to prevent overfitting and improve generalization. Yet they still rely heavily on predictions initially trained with the limited labeled data as pseudo-labels and are likely to put overconfident label belief on erroneous classes depending on the first prediction. To tackle this issue in text classification, we introduce LST, a simple self-training method that uses a lexicon to guide the pseudo-labeling mechanism in a linguistically-enriched manner. We consistently refine the lexicon by predicting confidence of the unseen data to teach pseudo-labels better in the training iterations. We demonstrate that this simple yet well-crafted lexical knowledge achieves 1.0-2.0% better performance on 30 labeled samples per class for five benchmark datasets than the current state-of-the-art approaches.
ALP: Data Augmentation using Lexicalized PCFGs for Few-Shot Text Classification
Dec 16, 2021

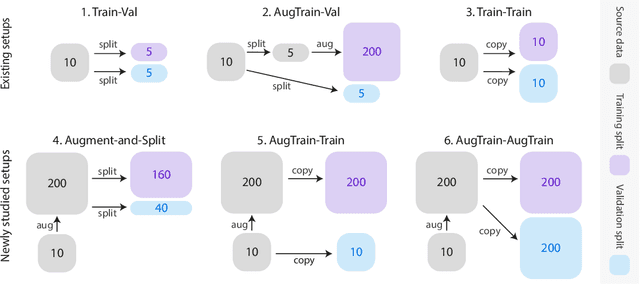
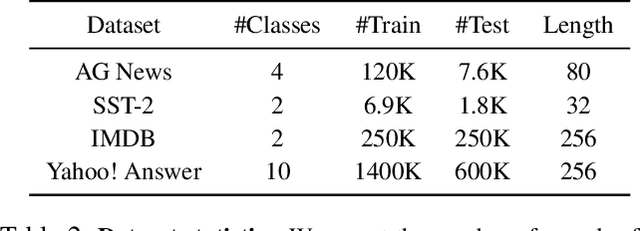
Data augmentation has been an important ingredient for boosting performances of learned models. Prior data augmentation methods for few-shot text classification have led to great performance boosts. However, they have not been designed to capture the intricate compositional structure of natural language. As a result, they fail to generate samples with plausible and diverse sentence structures. Motivated by this, we present the data Augmentation using Lexicalized Probabilistic context-free grammars (ALP) that generates augmented samples with diverse syntactic structures with plausible grammar. The lexicalized PCFG parse trees consider both the constituents and dependencies to produce a syntactic frame that maximizes a variety of word choices in a syntactically preservable manner without specific domain experts. Experiments on few-shot text classification tasks demonstrate that ALP enhances many state-of-the-art classification methods. As a second contribution, we delve into the train-val splitting methodologies when a data augmentation method comes into play. We argue empirically that the traditional splitting of training and validation sets is sub-optimal compared to our novel augmentation-based splitting strategies that further expand the training split with the same number of labeled data. Taken together, our contributions on the data augmentation strategies yield a strong training recipe for few-shot text classification tasks.