 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAURA: Natural Language Reasoning for Aleatoric Uncertainty in Rationales
Paper and Code
Feb 22, 2024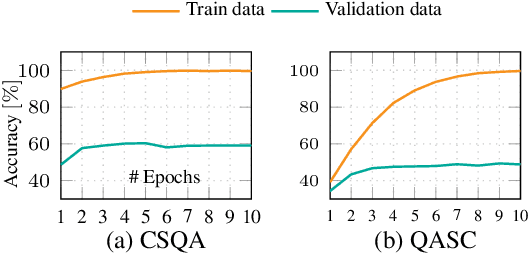
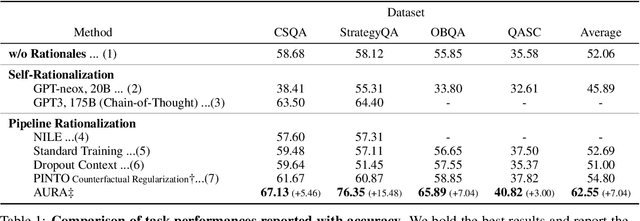
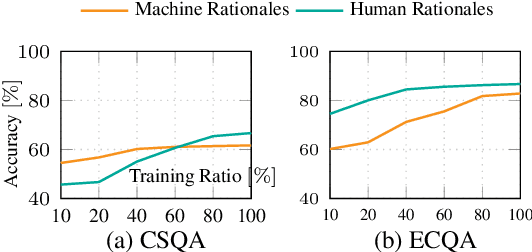
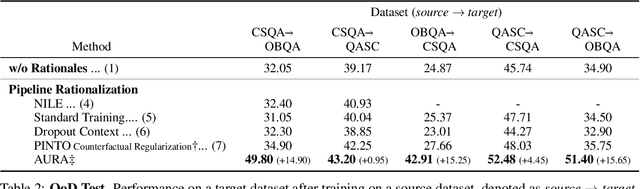
Rationales behind answers not only explain model decisions but boost language models to reason well on complex reasoning tasks. However, obtaining impeccable rationales is often impossible. Besides, it is non-trivial to estimate the degree to which the rationales are faithful enough to encourage model performance. Thus, such reasoning tasks often compel models to output correct answers under undesirable rationales and are sub-optimal compared to what the models are fully capable of. In this work, we propose how to deal with imperfect rationales causing aleatoric uncertainty. We first define the ambiguous rationales with entropy scores of given rationales, using model prior beliefs as informativeness. We then guide models to select one of two different reasoning models according to the ambiguity of rationales. We empirically argue that our proposed method produces robust performance superiority against the adversarial quality of rationales and low-resource settings.