 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for LRMs
Jan 07, 2026Large Reasoning Models (LRMs) achieve remarkable success through explicit thinking steps, yet the thinking steps introduce a novel risk by potentially amplifying unsafe behaviors. Despite this vulnerability, conventional defense mechanisms remain ineffective as they overlook the unique reasoning dynamics of LRMs. In this work, we find that the emergence of safe-reminding phrases within thinking steps plays a pivotal role in ensuring LRM safety. Motivated by this finding, we propose SafeRemind, a decoding-time defense method that dynamically injects safe-reminding phrases into thinking steps. By leveraging entropy triggers to intervene at decision-locking points, SafeRemind redirects potentially harmful trajectories toward safer outcomes without requiring any parameter updates. Extensive evaluations across five LRMs and six benchmarks demonstrate that SafeRemind substantially enhances safety, achieving improvements of up to 45.5%p while preserving core reasoning utility.
Neuro-Symbolic Regex Synthesis Framework via Neural Example Splitting
May 20, 2022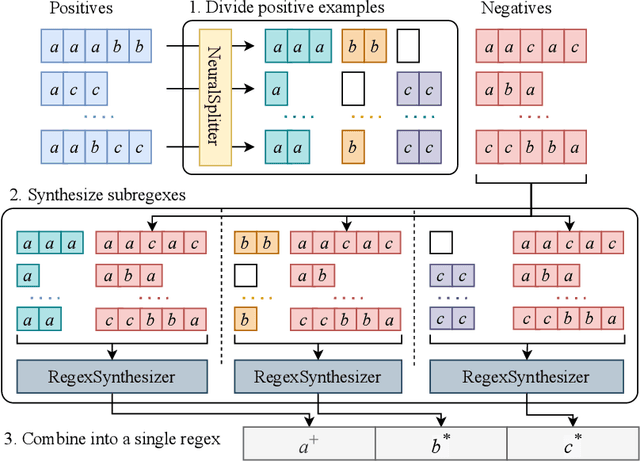
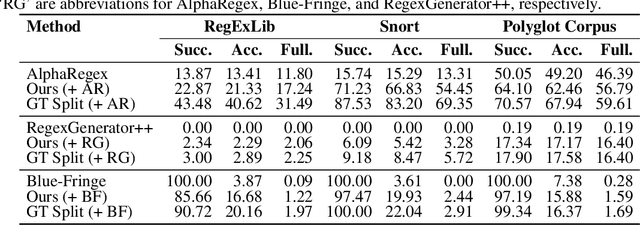

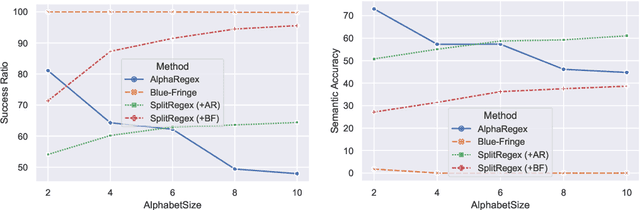
Due to the practical importance of regular expressions (regexes, for short), there has been a lot of research to automatically generate regexes from positive and negative string examples. We tackle the problem of learning regexes faster from positive and negative strings by relying on a novel approach called `neural example splitting'. Our approach essentially split up each example string into multiple parts using a neural network trained to group similar substrings from positive strings. This helps to learn a regex faster and, thus, more accurately since we now learn from several short-length strings. We propose an effective regex synthesis framework called `SplitRegex' that synthesizes subregexes from `split' positive substrings and produces the final regex by concatenating the synthesized subregexes. For the negative sample, we exploit pre-generated subregexes during the subregex synthesis process and perform the matching against negative strings. Then the final regex becomes consistent with all negative strings. SplitRegex is a divided-and-conquer framework for learning target regexes; split (=divide) positive strings and infer partial regexes for multiple parts, which is much more accurate than the whole string inferring, and concatenate (=conquer) inferred regexes while satisfying negative strings. We empirically demonstrate that the proposed SplitRegex framework substantially improves the previous regex synthesis approaches over four benchmark datasets.