 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPIC: Efficient and Parallel Inference under CFG Constraints for Diffusion Language Models
May 30, 2026Controlling language model outputs is essential for ensuring structural validity, reliability, and downstream usability, and diffusion language models are no exception. Recent advances in diffusion language model decoding have extended output control beyond regular constraints to context-free grammar (CFG) constraints. Existing methods, however, can be up to four times slower than unconstrained decoding. More importantly, they substantially diminish one of the key advantages of diffusion language models over autoregressive models, namely parallel decoding. This slowdown arises because sequential validity checking introduces significant overhead during parallel generation. We propose an efficient CFG-constrained decoding framework, EPIC, that addresses this limitation. Our method improves decoding efficiency by combining lexing memoization, validation using Earley-style parsing instead of deterministic automata, and relaxed compatible subset selection for parallel commit. It reduces repeated lexing and validation overhead while allowing multiple compatible tokens to be committed together. Experiments on three benchmarks using four models show that our method reduces inference time by up to 67.5% and decreases the additional overhead by up to 90.5% compared with existing CFG-constrained decoding methods. Our implementation is available at https://github.com/hyundong98/EPIC-Decoding.git .
STAB: Specification-driven Testing for Algorithmic Bottlenecks
May 27, 2026Evaluating the efficiency of algorithmic code requires test cases that expose runtime bottlenecks. Previous methods generate efficiency test cases either by increasing input size or by generating code-specific inputs that make the given implementation run slowly. Consequently, they do not address the structural input conditions that drive the algorithmic worst case. We introduce STAB, a specification-driven pipeline that generates test cases that expose algorithmic bottlenecks from a natural-language problem specification alone. STAB separates the task into constraint-bound maximization and adversarial structure injection. (i) The constraint saturator extracts constraints and resolves large admissible size assignments using rule-based saturation and CP-SAT optimization over related variables. (ii) The adversarial scenario injector retrieves implementation-level adversarial construction principles from a curated scenario catalog using keyword matching and K-nearest neighbors (KNN). STAB encodes the problem specification, resolved boundary, and retrieved construction principles into a structured generation specification, from which the LLM synthesizes a Python test case generator. On CodeContests, STAB raises the rate of generated test cases that expose algorithmic bottlenecks from 50.43% to 73.45% on average across open-source LLMs and from 57.45% to 71.85% on average across closed-source LLMs, with consistent gains across Python, Java, and C++. Our code is available at https://github.com/suhanmen/STAB.
NCO: A Versatile Plug-in for Handling Negative Constraints in Decoding
May 11, 2026Controlling Large Language Models (LLMs) to prevent the generation of undesirable content, such as profanity and personally identifiable information (PII), has become increasingly critical. While earlier approaches relied on post-processing or resampling, recent research has shifted towards constrained decoding methods that control outputs during generation to mitigate high computational costs and quality degradation. However, preventing multiple forbidden hard constraints or regex constraints from appearing anywhere in the output is computationally challenging. A straightforward solution is to convert these constraints into a single automaton that tracks all forbidden patterns during decoding, but this often becomes impractically large. Standard regex engines also do not readily support the operations needed to build such a constraint, such as complement and intersection. In order to address these limitations, we propose NCO, a decoding strategy that performs online pattern matching over finite hard constraints and regex constraints, reducing computational overhead without inducing state explosion. NCO is fully compatible with standard inference strategies, including various sampling methods and beam search, while also supporting soft masking for probabilistic suppression. We empirically demonstrate its effectiveness across practical tasks, including PII and profanity suppression. Our implementation is available at https://github.com/hyundong98/NCO-Decoding.git .
CRaFT: Circuit-Guided Refusal Feature Selection via Cross-Layer Transcoders
Apr 02, 2026As safety concerns around large language models (LLMs) grow, understanding the internal mechanisms underlying refusal behavior has become increasingly important. Recent work has studied this behavior by identifying internal features associated with refusal and manipulating them to induce compliance with harmful requests. However, existing refusal feature selection methods rely on how strongly features activate on harmful prompts, which tends to capture superficial signals rather than the causal factors underlying the refusal decision. We propose CRaFT, a circuit-guided refusal feature selection framework that ranks features by their influence on the model's refusal-compliance decision using prompts near the refusal boundary. On Gemma-3-1B-it, CRaFT improves attack success rate (ASR) from 6.7% to 48.2% and outperforms baseline methods across multiple jailbreak benchmarks. These results suggest that circuit influence is a more reliable criterion than activation magnitude for identifying features that causally mediate refusal behavior.
Which Concepts to Forget and How to Refuse? Decomposing Concepts for Continual Unlearning in Large Vision-Language Models
Mar 23, 2026Continual unlearning poses the challenge of enabling large vision-language models to selectively refuse specific image-instruction pairs in response to sequential deletion requests, while preserving general utility. However, sequential unlearning updates distort shared representations, creating spurious associations between vision-language pairs and refusal behaviors that hinder precise identification of refusal targets, resulting in inappropriate refusals. To address this challenge, we propose a novel continual unlearning framework that grounds refusal behavior in fine-grained descriptions of visual and textual concepts decomposed from deletion targets. We first identify which visual-linguistic concept combinations characterize each forget category through a concept modulator, then determine how to generate appropriate refusal responses via a mixture of refusal experts, termed refusers, each specialized for concept-aligned refusal generation. To generate concept-specific refusal responses across sequential tasks, we introduce a multimodal, concept-driven routing scheme that reuses refusers for tasks sharing similar concepts and adapts underutilized ones for novel concepts. Extensive experiments on vision-language benchmarks demonstrate that the proposed framework outperforms existing methods by generating concept-grounded refusal responses and preserving the general utility across unlearning sequences.
Steering Language Models Before They Speak: Logit-Level Interventions
Jan 16, 2026Steering LLMs is essential for specialized applications such as style-sensitive text rewriting, user-adaptive communication, and toxicity mitigation. Current steering methods, such as prompting-based and activation-based approaches, are widely used to guide model behavior. However, activation-based techniques require deep access to internal layers, while prompting-based steering often fails to provide consistent or fine-grained control. In order to address these limitations, we propose a training-free inference-time logit intervention for controllable generation. Our approach utilizes a statistical token score table derived from z-normalized log-odds of labeled corpora to shift the decoding distribution. Empirical evaluations across three diverse datasets focusing on writing complexity, formality, and toxicity demonstrate that our method effectively steers output characteristics, confirming its broad applicability and task-agnostic nature. Our results show that statistically grounded logit steering can achieve large, consistent, and multi-task control gains: up to +47%p accuracy and 50x f1 improvement.
How Does the Thinking Step Influence Model Safety? An Entropy-based Safety Reminder for LRMs
Jan 07, 2026Large Reasoning Models (LRMs) achieve remarkable success through explicit thinking steps, yet the thinking steps introduce a novel risk by potentially amplifying unsafe behaviors. Despite this vulnerability, conventional defense mechanisms remain ineffective as they overlook the unique reasoning dynamics of LRMs. In this work, we find that the emergence of safe-reminding phrases within thinking steps plays a pivotal role in ensuring LRM safety. Motivated by this finding, we propose SafeRemind, a decoding-time defense method that dynamically injects safe-reminding phrases into thinking steps. By leveraging entropy triggers to intervene at decision-locking points, SafeRemind redirects potentially harmful trajectories toward safer outcomes without requiring any parameter updates. Extensive evaluations across five LRMs and six benchmarks demonstrate that SafeRemind substantially enhances safety, achieving improvements of up to 45.5%p while preserving core reasoning utility.
Instruction-Grounded Visual Projectors for Continual Learning of Generative Vision-Language Models
Aug 01, 2025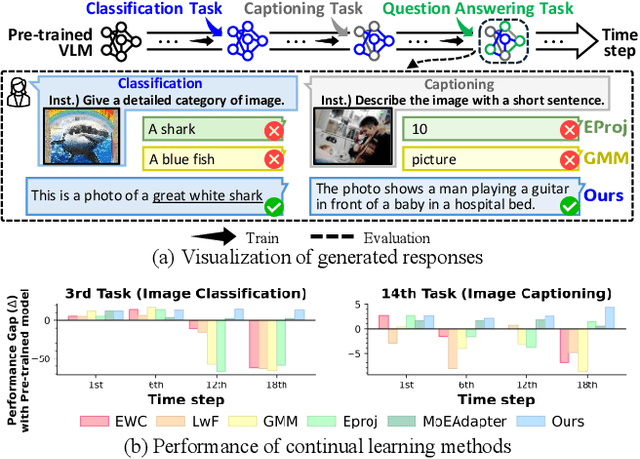
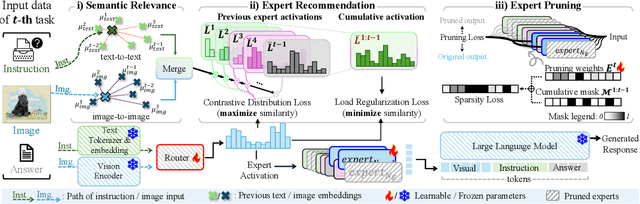
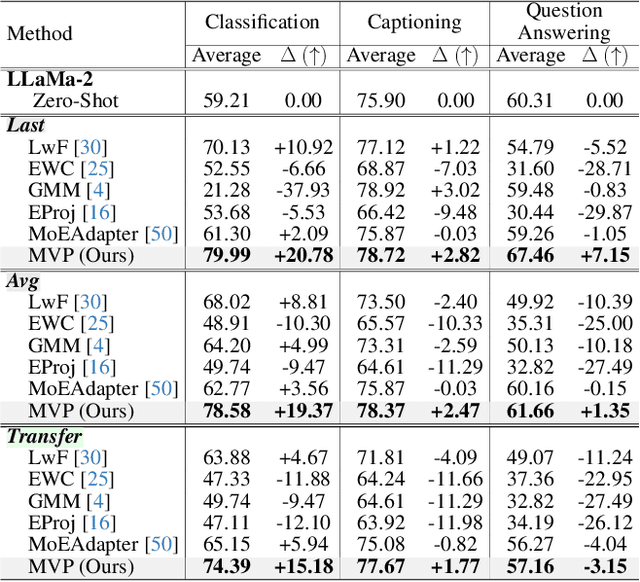
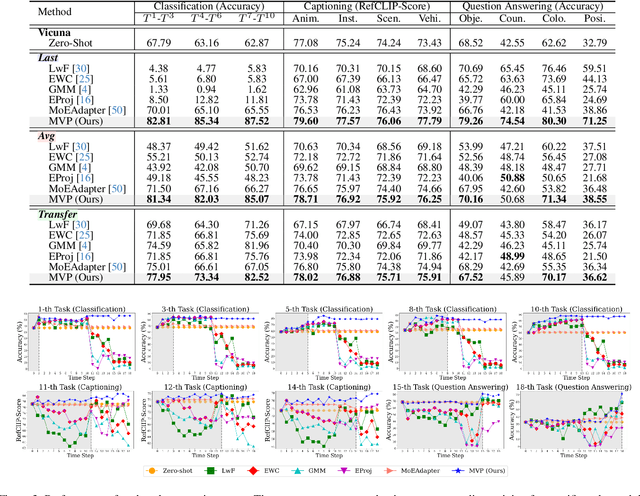
Continual learning enables pre-trained generative vision-language models (VLMs) to incorporate knowledge from new tasks without retraining data from previous ones. Recent methods update a visual projector to translate visual information for new tasks, connecting pre-trained vision encoders with large language models. However, such adjustments may cause the models to prioritize visual inputs over language instructions, particularly learning tasks with repetitive types of textual instructions. To address the neglect of language instructions, we propose a novel framework that grounds the translation of visual information on instructions for language models. We introduce a mixture of visual projectors, each serving as a specialized visual-to-language translation expert based on the given instruction context to adapt to new tasks. To avoid using experts for irrelevant instruction contexts, we propose an expert recommendation strategy that reuses experts for tasks similar to those previously learned. Additionally, we introduce expert pruning to alleviate interference from the use of experts that cumulatively activated in previous tasks. Extensive experiments on diverse vision-language tasks demonstrate that our method outperforms existing continual learning approaches by generating instruction-following responses.
Continual Learning for Multiple Modalities
Mar 11, 2025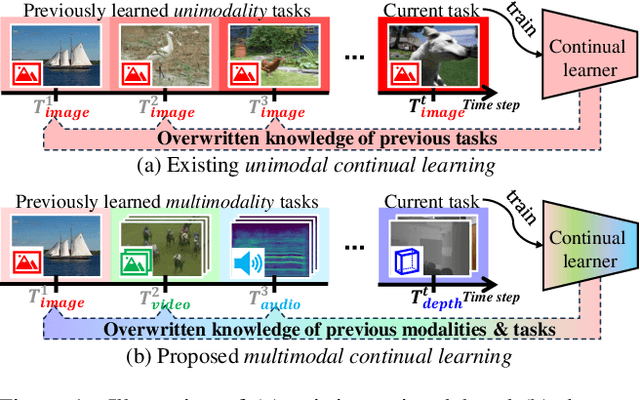
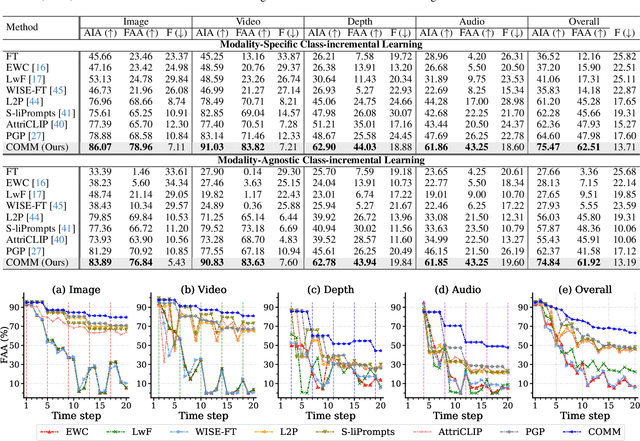
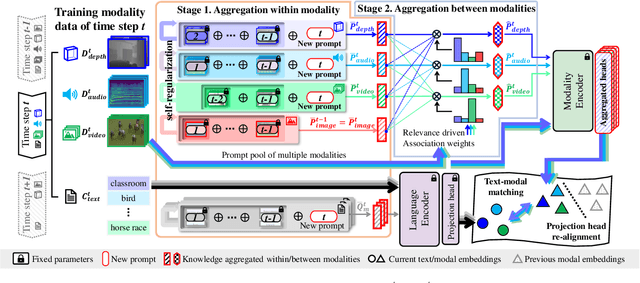
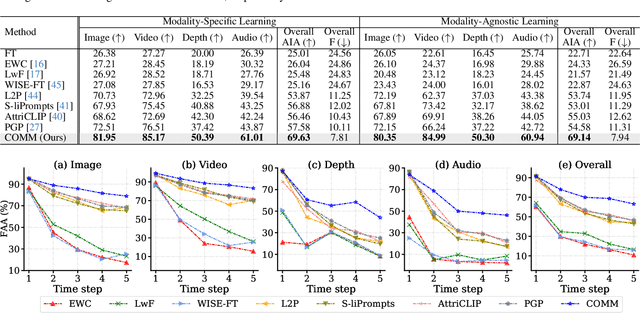
Continual learning aims to learn knowledge of tasks observed in sequential time steps while mitigating the forgetting of previously learned knowledge. Existing methods were proposed under the assumption of learning a single modality (e.g., image) over time, which limits their applicability in scenarios involving multiple modalities. In this work, we propose a novel continual learning framework that accommodates multiple modalities (image, video, audio, depth, and text). We train a model to align various modalities with text, leveraging its rich semantic information. However, this increases the risk of forgetting previously learned knowledge, exacerbated by the differing input traits of each task. To alleviate the overwriting of the previous knowledge of modalities, we propose a method for aggregating knowledge within and across modalities. The aggregated knowledge is obtained by assimilating new information through self-regularization within each modality and associating knowledge between modalities by prioritizing contributions from relevant modalities. Furthermore, we propose a strategy that re-aligns the embeddings of modalities to resolve biased alignment between modalities. We evaluate the proposed method in a wide range of continual learning scenarios using multiple datasets with different modalities. Extensive experiments demonstrate that ours outperforms existing methods in the scenarios, regardless of whether the identity of the modality is given.
Detection of LLM-Paraphrased Code and Identification of the Responsible LLM Using Coding Style Features
Feb 25, 2025Recent progress in large language models (LLMs) for code generation has raised serious concerns about intellectual property protection. Malicious users can exploit LLMs to produce paraphrased versions of proprietary code that closely resemble the original. While the potential for LLM-assisted code paraphrasing continues to grow, research on detecting it remains limited, underscoring an urgent need for detection system. We respond to this need by proposing two tasks. The first task is to detect whether code generated by an LLM is a paraphrased version of original human-written code. The second task is to identify which LLM is used to paraphrase the original code. For these tasks, we construct a dataset LPcode consisting of pairs of human-written code and LLM-paraphrased code using various LLMs. We statistically confirm significant differences in the coding styles of human-written and LLM-paraphrased code, particularly in terms of naming consistency, code structure, and readability. Based on these findings, we develop LPcodedec, a detection method that identifies paraphrase relationships between human-written and LLM-generated code, and discover which LLM is used for the paraphrasing. LPcodedec outperforms the best baselines in two tasks, improving F1 scores by 2.64% and 15.17% while achieving speedups of 1,343x and 213x, respectively.