 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Long Semantic IDs in Parallel for Recommendation
Jun 06, 2025Semantic ID-based recommendation models tokenize each item into a small number of discrete tokens that preserve specific semantics, leading to better performance, scalability, and memory efficiency. While recent models adopt a generative approach, they often suffer from inefficient inference due to the reliance on resource-intensive beam search and multiple forward passes through the neural sequence model. As a result, the length of semantic IDs is typically restricted (e.g. to just 4 tokens), limiting their expressiveness. To address these challenges, we propose RPG, a lightweight framework for semantic ID-based recommendation. The key idea is to produce unordered, long semantic IDs, allowing the model to predict all tokens in parallel. We train the model to predict each token independently using a multi-token prediction loss, directly integrating semantics into the learning objective. During inference, we construct a graph connecting similar semantic IDs and guide decoding to avoid generating invalid IDs. Experiments show that scaling up semantic ID length to 64 enables RPG to outperform generative baselines by an average of 12.6% on the NDCG@10, while also improving inference efficiency. Code is available at: https://github.com/facebookresearch/RPG_KDD2025.
Possibility for Proactive Anomaly Detection
Apr 15, 2025Time-series anomaly detection, which detects errors and failures in a workflow, is one of the most important topics in real-world applications. The purpose of time-series anomaly detection is to reduce potential damages or losses. However, existing anomaly detection models detect anomalies through the error between the model output and the ground truth (observed) value, which makes them impractical. In this work, we present a \textit{proactive} approach for time-series anomaly detection based on a time-series forecasting model specialized for anomaly detection and a data-driven anomaly detection model. Our proactive approach establishes an anomaly threshold from training data with a data-driven anomaly detection model, and anomalies are subsequently detected by identifying predicted values that exceed the anomaly threshold. In addition, we extensively evaluated the model using four anomaly detection benchmarks and analyzed both predictable and unpredictable anomalies. We attached the source code as supplementary material.
PAC-FNO: Parallel-Structured All-Component Fourier Neural Operators for Recognizing Low-Quality Images
Feb 20, 2024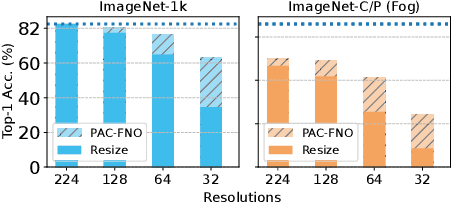
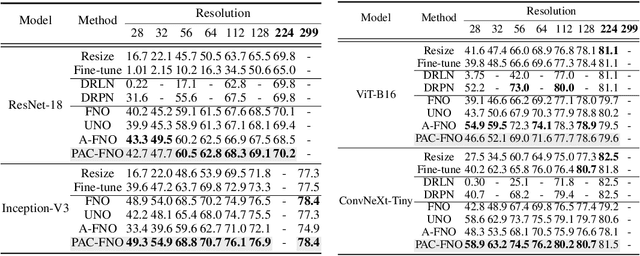
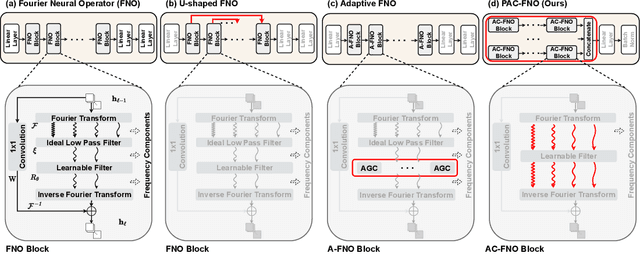
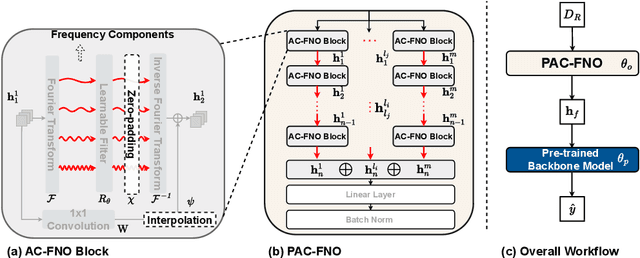
A standard practice in developing image recognition models is to train a model on a specific image resolution and then deploy it. However, in real-world inference, models often encounter images different from the training sets in resolution and/or subject to natural variations such as weather changes, noise types and compression artifacts. While traditional solutions involve training multiple models for different resolutions or input variations, these methods are computationally expensive and thus do not scale in practice. To this end, we propose a novel neural network model, parallel-structured and all-component Fourier neural operator (PAC-FNO), that addresses the problem. Unlike conventional feed-forward neural networks, PAC-FNO operates in the frequency domain, allowing it to handle images of varying resolutions within a single model. We also propose a two-stage algorithm for training PAC-FNO with a minimal modification to the original, downstream model. Moreover, the proposed PAC-FNO is ready to work with existing image recognition models. Extensively evaluating methods with seven image recognition benchmarks, we show that the proposed PAC-FNO improves the performance of existing baseline models on images with various resolutions by up to 77.1% and various types of natural variations in the images at inference.
Operator-learning-inspired Modeling of Neural Ordinary Differential Equations
Dec 16, 2023Neural ordinary differential equations (NODEs), one of the most influential works of the differential equation-based deep learning, are to continuously generalize residual networks and opened a new field. They are currently utilized for various downstream tasks, e.g., image classification, time series classification, image generation, etc. Its key part is how to model the time-derivative of the hidden state, denoted dh(t)/dt. People have habitually used conventional neural network architectures, e.g., fully-connected layers followed by non-linear activations. In this paper, however, we present a neural operator-based method to define the time-derivative term. Neural operators were initially proposed to model the differential operator of partial differential equations (PDEs). Since the time-derivative of NODEs can be understood as a special type of the differential operator, our proposed method, called branched Fourier neural operator (BFNO), makes sense. In our experiments with general downstream tasks, our method significantly outperforms existing methods.
Long-term Time Series Forecasting based on Decomposition and Neural Ordinary Differential Equations
Nov 10, 2023



Long-term time series forecasting (LTSF) is a challenging task that has been investigated in various domains such as finance investment, health care, traffic, and weather forecasting. In recent years, Linear-based LTSF models showed better performance, pointing out the problem of Transformer-based approaches causing temporal information loss. However, Linear-based approach has also limitations that the model is too simple to comprehensively exploit the characteristics of the dataset. To solve these limitations, we propose LTSF-DNODE, which applies a model based on linear ordinary differential equations (ODEs) and a time series decomposition method according to data statistical characteristics. We show that LTSF-DNODE outperforms the baselines on various real-world datasets. In addition, for each dataset, we explore the impacts of regularization in the neural ordinary differential equation (NODE) framework.
GT-GAN: General Purpose Time Series Synthesis with Generative Adversarial Networks
Oct 11, 2022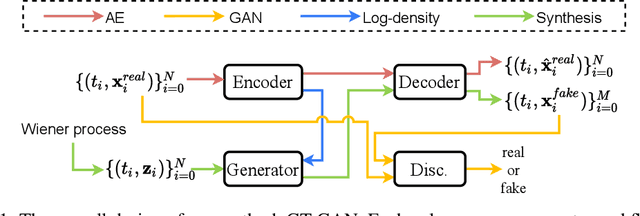
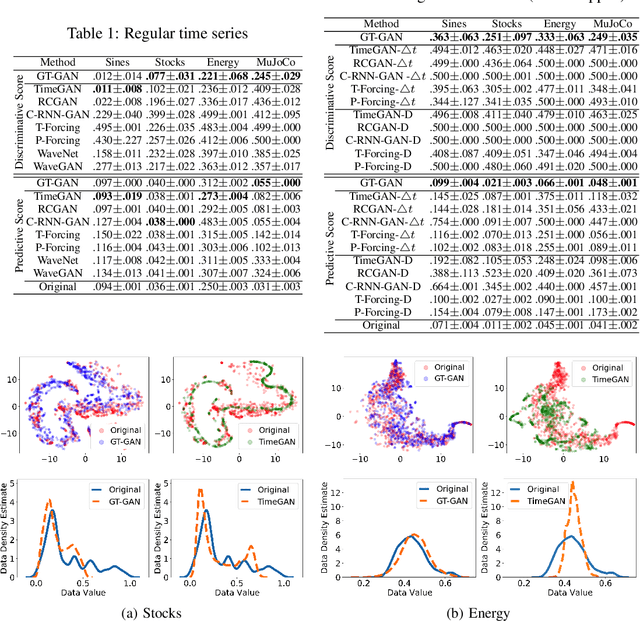

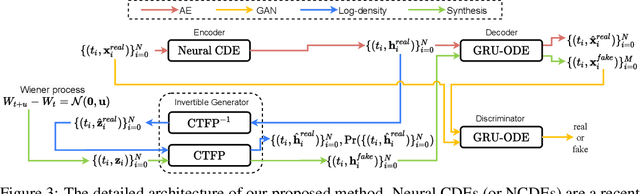
Time series synthesis is an important research topic in the field of deep learning, which can be used for data augmentation. Time series data types can be broadly classified into regular or irregular. However, there are no existing generative models that show good performance for both types without any model changes. Therefore, we present a general purpose model capable of synthesizing regular and irregular time series data. To our knowledge, we are the first designing a general purpose time series synthesis model, which is one of the most challenging settings for time series synthesis. To this end, we design a generative adversarial network-based method, where many related techniques are carefully integrated into a single framework, ranging from neural ordinary/controlled differential equations to continuous time-flow processes. Our method outperforms all existing methods.
SPI-GAN: Distilling Score-based Generative Models with Straight-Path Interpolations
Jun 29, 2022

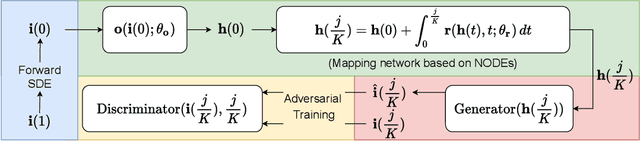
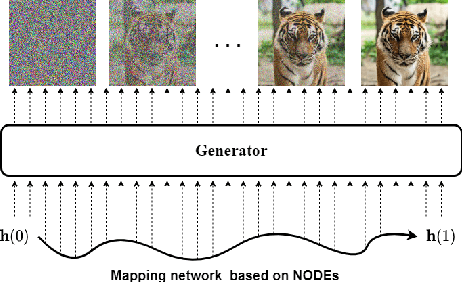
Score-based generative models (SGMs) are a recently proposed paradigm for deep generative tasks and now show the state-of-the-art sampling performance. It is known that the original SGM design solves the two problems of the generative trilemma: i) sampling quality, and ii) sampling diversity. However, the last problem of the trilemma was not solved, i.e., their training/sampling complexity is notoriously high. To this end, distilling SGMs into simpler models, e.g., generative adversarial networks (GANs), is gathering much attention currently. We present an enhanced distillation method, called straight-path interpolation GAN (SPI-GAN), which can be compared to the state-of-the-art shortcut-based distillation method, called denoising diffusion GAN (DD-GAN). However, our method corresponds to an extreme method that does not use any intermediate shortcut information of the reverse SDE path, in which case DD-GAN fails to obtain good results. Nevertheless, our straight-path interpolation method greatly stabilizes the overall training process. As a result, SPI-GAN is one of the best models in terms of the sampling quality/diversity/time for CIFAR-10, CelebA-HQ-256, and LSUN-Church-256.
LORD: Lower-Dimensional Embedding of Log-Signature in Neural Rough Differential Equations
Apr 19, 2022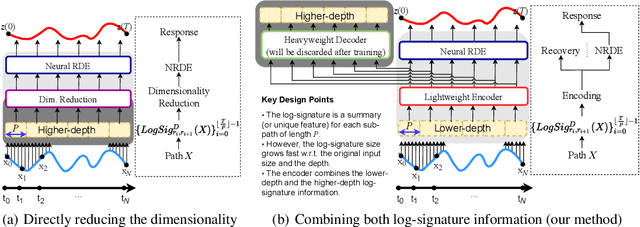

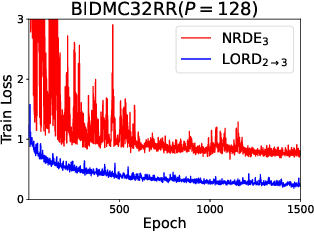
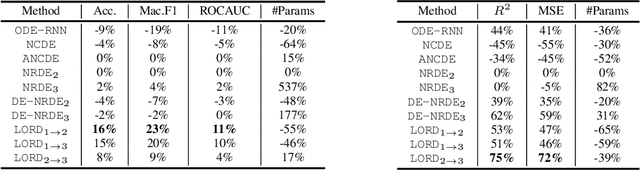
The problem of processing very long time-series data (e.g., a length of more than 10,000) is a long-standing research problem in machine learning. Recently, one breakthrough, called neural rough differential equations (NRDEs), has been proposed and has shown that it is able to process such data. Their main concept is to use the log-signature transform, which is known to be more efficient than the Fourier transform for irregular long time-series, to convert a very long time-series sample into a relatively shorter series of feature vectors. However, the log-signature transform causes non-trivial spatial overheads. To this end, we present the method of LOweR-Dimensional embedding of log-signature (LORD), where we define an NRDE-based autoencoder to implant the higher-depth log-signature knowledge into the lower-depth log-signature. We show that the encoder successfully combines the higher-depth and the lower-depth log-signature knowledge, which greatly stabilizes the training process and increases the model accuracy. In our experiments with benchmark datasets, the improvement ratio by our method is up to 75\% in terms of various classification and forecasting evaluation metrics.
EXIT: Extrapolation and Interpolation-based Neural Controlled Differential Equations for Time-series Classification and Forecasting
Apr 19, 2022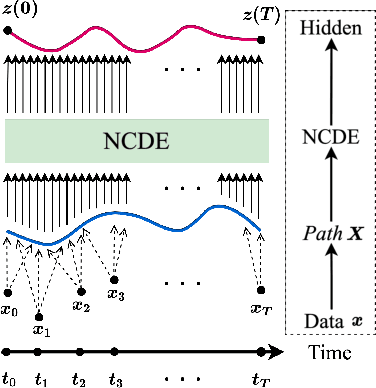
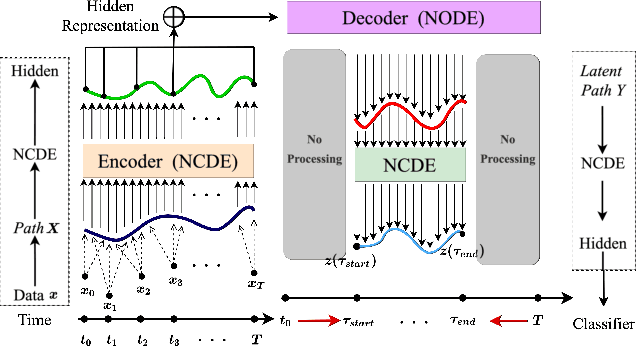
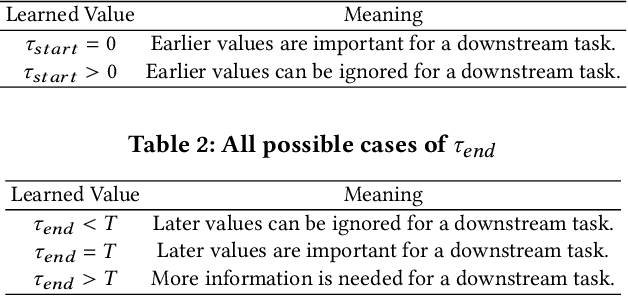
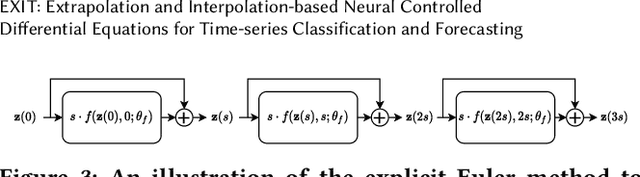
Deep learning inspired by differential equations is a recent research trend and has marked the state of the art performance for many machine learning tasks. Among them, time-series modeling with neural controlled differential equations (NCDEs) is considered as a breakthrough. In many cases, NCDE-based models not only provide better accuracy than recurrent neural networks (RNNs) but also make it possible to process irregular time-series. In this work, we enhance NCDEs by redesigning their core part, i.e., generating a continuous path from a discrete time-series input. NCDEs typically use interpolation algorithms to convert discrete time-series samples to continuous paths. However, we propose to i) generate another latent continuous path using an encoder-decoder architecture, which corresponds to the interpolation process of NCDEs, i.e., our neural network-based interpolation vs. the existing explicit interpolation, and ii) exploit the generative characteristic of the decoder, i.e., extrapolation beyond the time domain of original data if needed. Therefore, our NCDE design can use both the interpolated and the extrapolated information for downstream machine learning tasks. In our experiments with 5 real-world datasets and 12 baselines, our extrapolation and interpolation-based NCDEs outperform existing baselines by non-trivial margins.
Invertible Tabular GANs: Killing Two Birds with OneStone for Tabular Data Synthesis
Feb 08, 2022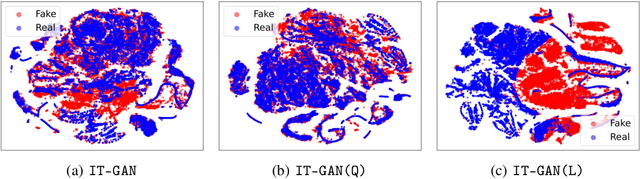
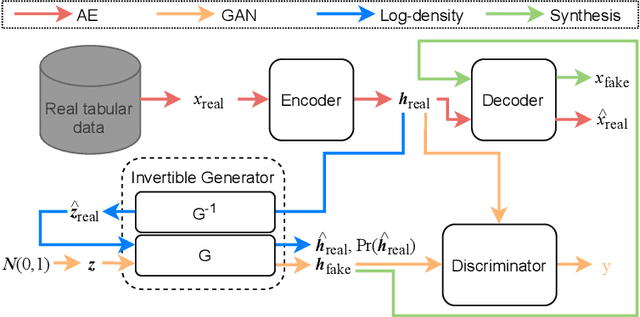
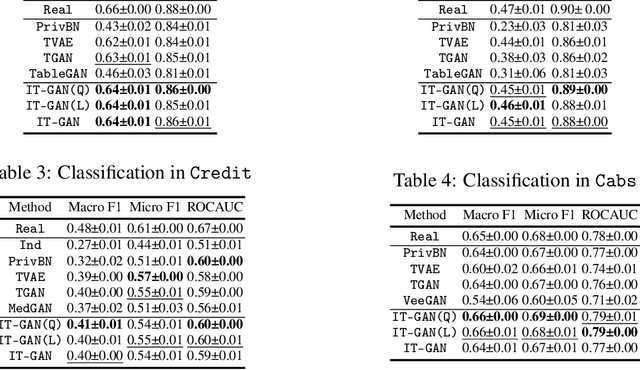
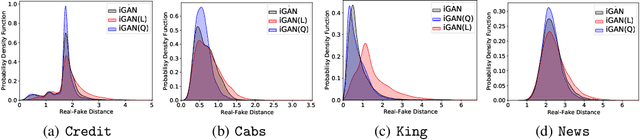
Tabular data synthesis has received wide attention in the literature. This is because available data is often limited, incomplete, or cannot be obtained easily, and data privacy is becoming increasingly important. In this work, we present a generalized GAN framework for tabular synthesis, which combines the adversarial training of GANs and the negative log-density regularization of invertible neural networks. The proposed framework can be used for two distinctive objectives. First, we can further improve the synthesis quality, by decreasing the negative log-density of real records in the process of adversarial training. On the other hand, by increasing the negative log-density of real records, realistic fake records can be synthesized in a way that they are not too much close to real records and reduce the chance of potential information leakage. We conduct experiments with real-world datasets for classification, regression, and privacy attacks. In general, the proposed method demonstrates the best synthesis quality (in terms of task-oriented evaluation metrics, e.g., F1) when decreasing the negative log-density during the adversarial training. If increasing the negative log-density, our experimental results show that the distance between real and fake records increases, enhancing robustness against privacy attacks.