 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFEATHer: Fourier-Efficient Adaptive Temporal Hierarchy Forecaster for Time-Series Forecasting
Jan 16, 2026Time-series forecasting is fundamental in industrial domains like manufacturing and smart factories. As systems evolve toward automation, models must operate on edge devices (e.g., PLCs, microcontrollers) with strict constraints on latency and memory, limiting parameters to a few thousand. Conventional deep architectures are often impractical here. We propose the Fourier-Efficient Adaptive Temporal Hierarchy Forecaster (FEATHer) for accurate long-term forecasting under severe limits. FEATHer introduces: (i) ultra-lightweight multiscale decomposition into frequency pathways; (ii) a shared Dense Temporal Kernel using projection-depthwise convolution-projection without recurrence or attention; (iii) frequency-aware branch gating that adaptively fuses representations based on spectral characteristics; and (iv) a Sparse Period Kernel reconstructing outputs via period-wise downsampling to capture seasonality. FEATHer maintains a compact architecture (as few as 400 parameters) while outperforming baselines. Across eight benchmarks, it achieves the best ranking, recording 60 first-place results with an average rank of 2.05. These results demonstrate that reliable long-range forecasting is achievable on constrained edge hardware, offering a practical direction for industrial real-time inference.
Adaptive Information Routing for Multimodal Time Series Forecasting
Dec 23, 2025Time series forecasting is a critical task for artificial intelligence with numerous real-world applications. Traditional approaches primarily rely on historical time series data to predict the future values. However, in practical scenarios, this is often insufficient for accurate predictions due to the limited information available. To address this challenge, multimodal time series forecasting methods which incorporate additional data modalities, mainly text data, alongside time series data have been explored. In this work, we introduce the Adaptive Information Routing (AIR) framework, a novel approach for multimodal time series forecasting. Unlike existing methods that treat text data on par with time series data as interchangeable auxiliary features for forecasting, AIR leverages text information to dynamically guide the time series model by controlling how and to what extent multivariate time series information should be combined. We also present a text-refinement pipeline that employs a large language model to convert raw text data into a form suitable for multimodal forecasting, and we introduce a benchmark that facilitates multimodal forecasting experiments based on this pipeline. Experiment results with the real world market data such as crude oil price and exchange rates demonstrate that AIR effectively modulates the behavior of the time series model using textual inputs, significantly enhancing forecasting accuracy in various time series forecasting tasks.
SDS KoPub VDR: A Benchmark Dataset for Visual Document Retrieval in Korean Public Documents
Nov 07, 2025Existing benchmarks for visual document retrieval (VDR) largely overlook non-English languages and the structural complexity of official publications. To address this critical gap, we introduce SDS KoPub VDR, the first large-scale, publicly available benchmark for retrieving and understanding Korean public documents. The benchmark is built upon a corpus of 361 real-world documents (40,781 pages), including 256 files under the KOGL Type 1 license and 105 from official legal portals, capturing complex visual elements like tables, charts, and multi-column layouts. To establish a challenging and reliable evaluation set, we constructed 600 query-page-answer triples. These were initially generated using multimodal models (e.g., GPT-4o) and subsequently underwent a rigorous human verification and refinement process to ensure factual accuracy and contextual relevance. The queries span six major public domains and are systematically categorized by the reasoning modality required: text-based, visual-based (e.g., chart interpretation), and cross-modal. We evaluate SDS KoPub VDR on two complementary tasks that reflect distinct retrieval paradigms: (1) text-only retrieval, which measures a model's ability to locate relevant document pages based solely on textual signals, and (2) multimodal retrieval, which assesses retrieval performance when visual features (e.g., tables, charts, and layouts) are jointly leveraged alongside text. This dual-task evaluation reveals substantial performance gaps, particularly in multimodal scenarios requiring cross-modal reasoning, even for state-of-the-art models. As a foundational resource, SDS KoPub VDR not only enables rigorous and fine-grained evaluation across textual and multimodal retrieval tasks but also provides a clear roadmap for advancing multimodal AI in complex, real-world document intelligence.
THEME : Enhancing Thematic Investing with Semantic Stock Representations and Temporal Dynamics
Aug 23, 2025Thematic investing aims to construct portfolios aligned with structural trends, yet selecting relevant stocks remains challenging due to overlapping sector boundaries and evolving market dynamics. To address this challenge, we construct the Thematic Representation Set (TRS), an extended dataset that begins with real-world thematic ETFs and expands upon them by incorporating industry classifications and financial news to overcome their coverage limitations. The final dataset contains both the explicit mapping of themes to their constituent stocks and the rich textual profiles for each. Building on this dataset, we introduce \textsc{THEME}, a hierarchical contrastive learning framework. By representing the textual profiles of themes and stocks as embeddings, \textsc{THEME} first leverages their hierarchical relationship to achieve semantic alignment. Subsequently, it refines these semantic embeddings through a temporal refinement stage that incorporates individual stock returns. The final stock representations are designed for effective retrieval of thematically aligned assets with strong return potential. Empirical results show that \textsc{THEME} outperforms strong baselines across multiple retrieval metrics and significantly improves performance in portfolio construction. By jointly modeling thematic relationships from text and market dynamics from returns, \textsc{THEME} provides a scalable and adaptive solution for navigating complex investment themes.
From What to Respond to When to Respond: Timely Response Generation for Open-domain Dialogue Agents
Jun 17, 2025While research on dialogue response generation has primarily focused on generating coherent responses conditioning on textual context, the critical question of when to respond grounded on the temporal context remains underexplored. To bridge this gap, we propose a novel task called timely dialogue response generation and introduce the TimelyChat benchmark, which evaluates the capabilities of language models to predict appropriate time intervals and generate time-conditioned responses. Additionally, we construct a large-scale training dataset by leveraging unlabeled event knowledge from a temporal commonsense knowledge graph and employing a large language model (LLM) to synthesize 55K event-driven dialogues. We then train Timer, a dialogue agent designed to proactively predict time intervals and generate timely responses that align with those intervals. Experimental results show that Timer outperforms prompting-based LLMs and other fine-tuned baselines in both turn-level and dialogue-level evaluations. We publicly release our data, model, and code.
DCG-SQL: Enhancing In-Context Learning for Text-to-SQL with Deep Contextual Schema Link Graph
May 26, 2025Text-to-SQL, which translates a natural language question into an SQL query, has advanced with in-context learning of Large Language Models (LLMs). However, existing methods show little improvement in performance compared to randomly chosen demonstrations, and significant performance drops when smaller LLMs (e.g., Llama 3.1-8B) are used. This indicates that these methods heavily rely on the intrinsic capabilities of hyper-scaled LLMs, rather than effectively retrieving useful demonstrations. In this paper, we propose a novel approach for effectively retrieving demonstrations and generating SQL queries. We construct a Deep Contextual Schema Link Graph, which contains key information and semantic relationship between a question and its database schema items. This graph-based structure enables effective representation of Text-to-SQL samples and retrieval of useful demonstrations for in-context learning. Experimental results on the Spider benchmark demonstrate the effectiveness of our approach, showing consistent improvements in SQL generation performance and efficiency across both hyper-scaled LLMs and small LLMs. Our code will be released.
HFI: A unified framework for training-free detection and implicit watermarking of latent diffusion model generated images
Dec 30, 2024Dramatic advances in the quality of the latent diffusion models (LDMs) also led to the malicious use of AI-generated images. While current AI-generated image detection methods assume the availability of real/AI-generated images for training, this is practically limited given the vast expressibility of LDMs. This motivates the training-free detection setup where no related data are available in advance. The existing LDM-generated image detection method assumes that images generated by LDM are easier to reconstruct using an autoencoder than real images. However, we observe that this reconstruction distance is overfitted to background information, leading the current method to underperform in detecting images with simple backgrounds. To address this, we propose a novel method called HFI. Specifically, by viewing the autoencoder of LDM as a downsampling-upsampling kernel, HFI measures the extent of aliasing, a distortion of high-frequency information that appears in the reconstructed image. HFI is training-free, efficient, and consistently outperforms other training-free methods in detecting challenging images generated by various generative models. We also show that HFI can successfully detect the images generated from the specified LDM as a means of implicit watermarking. HFI outperforms the best baseline method while achieving magnitudes of
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Partial-Multivariate Model for Forecasting
Aug 19, 2024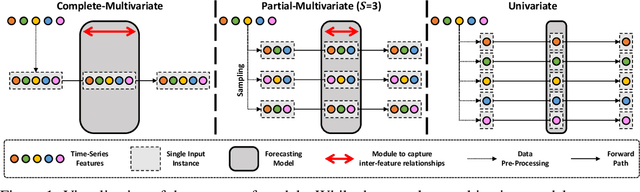
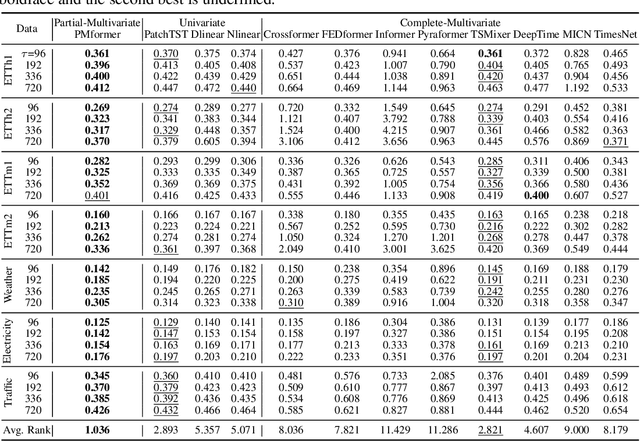

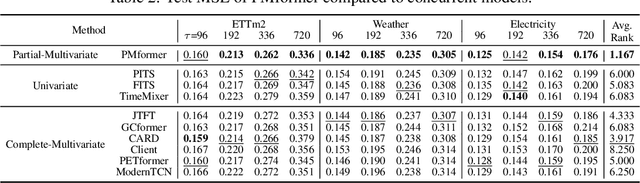
When solving forecasting problems including multiple time-series features, existing approaches often fall into two extreme categories, depending on whether to utilize inter-feature information: univariate and complete-multivariate models. Unlike univariate cases which ignore the information, complete-multivariate models compute relationships among a complete set of features. However, despite the potential advantage of leveraging the additional information, complete-multivariate models sometimes underperform univariate ones. Therefore, our research aims to explore a middle ground between these two by introducing what we term Partial-Multivariate models where a neural network captures only partial relationships, that is, dependencies within subsets of all features. To this end, we propose PMformer, a Transformer-based partial-multivariate model, with its training algorithm. We demonstrate that PMformer outperforms various univariate and complete-multivariate models, providing a theoretical rationale and empirical analysis for its superiority. Additionally, by proposing an inference technique for PMformer, the forecasting accuracy is further enhanced. Finally, we highlight other advantages of PMformer: efficiency and robustness under missing features.
Training Language Models on the Knowledge Graph: Insights on Hallucinations and Their Detectability
Aug 14, 2024



While many capabilities of language models (LMs) improve with increased training budget, the influence of scale on hallucinations is not yet fully understood. Hallucinations come in many forms, and there is no universally accepted definition. We thus focus on studying only those hallucinations where a correct answer appears verbatim in the training set. To fully control the training data content, we construct a knowledge graph (KG)-based dataset, and use it to train a set of increasingly large LMs. We find that for a fixed dataset, larger and longer-trained LMs hallucinate less. However, hallucinating on $\leq5$% of the training data requires an order of magnitude larger model, and thus an order of magnitude more compute, than Hoffmann et al. (2022) reported was optimal. Given this costliness, we study how hallucination detectors depend on scale. While we see detector size improves performance on fixed LM's outputs, we find an inverse relationship between the scale of the LM and the detectability of its hallucinations.