 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Bandits with Partially Observable Features
Feb 10, 2025We introduce a novel linear bandit problem with partially observable features, resulting in partial reward information and spurious estimates. Without proper address for latent part, regret possibly grows linearly in decision horizon $T$, as their influence on rewards are unknown. To tackle this, we propose a novel analysis to handle the latent features and an algorithm that achieves sublinear regret. The core of our algorithm involves (i) augmenting basis vectors orthogonal to the observed feature space, and (ii) introducing an efficient doubly robust estimator. Our approach achieves a regret bound of $\tilde{O}(\sqrt{(d + d_h)T})$, where $d$ is the dimension of observed features, and $d_h$ is the unknown dimension of the subspace of the unobserved features. Notably, our algorithm requires no prior knowledge of the unobserved feature space, which may expand as more features become hidden. Numerical experiments confirm that our algorithm outperforms both non-contextual multi-armed bandits and linear bandit algorithms depending solely on observed features.
HFI: A unified framework for training-free detection and implicit watermarking of latent diffusion model generated images
Dec 30, 2024Dramatic advances in the quality of the latent diffusion models (LDMs) also led to the malicious use of AI-generated images. While current AI-generated image detection methods assume the availability of real/AI-generated images for training, this is practically limited given the vast expressibility of LDMs. This motivates the training-free detection setup where no related data are available in advance. The existing LDM-generated image detection method assumes that images generated by LDM are easier to reconstruct using an autoencoder than real images. However, we observe that this reconstruction distance is overfitted to background information, leading the current method to underperform in detecting images with simple backgrounds. To address this, we propose a novel method called HFI. Specifically, by viewing the autoencoder of LDM as a downsampling-upsampling kernel, HFI measures the extent of aliasing, a distortion of high-frequency information that appears in the reconstructed image. HFI is training-free, efficient, and consistently outperforms other training-free methods in detecting challenging images generated by various generative models. We also show that HFI can successfully detect the images generated from the specified LDM as a means of implicit watermarking. HFI outperforms the best baseline method while achieving magnitudes of
Mean-field Chaos Diffusion Models
Jun 08, 2024


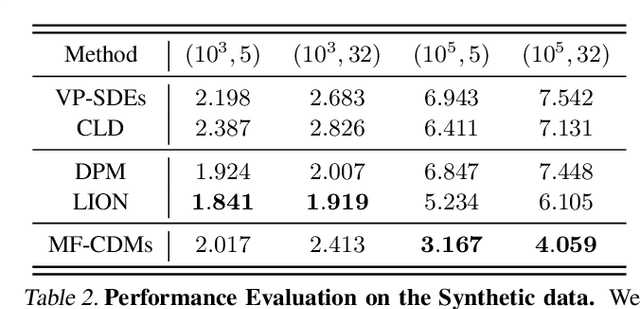
In this paper, we introduce a new class of score-based generative models (SGMs) designed to handle high-cardinality data distributions by leveraging concepts from mean-field theory. We present mean-field chaos diffusion models (MF-CDMs), which address the curse of dimensionality inherent in high-cardinality data by utilizing the propagation of chaos property of interacting particles. By treating high-cardinality data as a large stochastic system of interacting particles, we develop a novel score-matching method for infinite-dimensional chaotic particle systems and propose an approximation scheme that employs a subdivision strategy for efficient training. Our theoretical and empirical results demonstrate the scalability and effectiveness of MF-CDMs for managing large high-cardinality data structures, such as 3D point clouds.
Parameter-Free Algorithms for Performative Regret Minimization under Decision-Dependent Distributions
Feb 23, 2024This paper studies performative risk minimization, a formulation of stochastic optimization under decision-dependent distributions. We consider the general case where the performative risk can be non-convex, for which we develop efficient parameter-free optimistic optimization-based methods. Our algorithms significantly improve upon the existing Lipschitz bandit-based method in many aspects. In particular, our framework does not require knowledge about the sensitivity parameter of the distribution map and the Lipshitz constant of the loss function. This makes our framework practically favorable, together with the efficient optimistic optimization-based tree-search mechanism. We provide experimental results that demonstrate the numerical superiority of our algorithms over the existing method and other black-box optimistic optimization methods.
InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists
Sep 30, 2023



Recent advances in generative diffusion models have enabled text-controlled synthesis of realistic and diverse images with impressive quality. Despite these remarkable advances, the application of text-to-image generative models in computer vision for standard visual recognition tasks remains limited. The current de facto approach for these tasks is to design model architectures and loss functions that are tailored to the task at hand. In this paper, we develop a unified language interface for computer vision tasks that abstracts away task-specific design choices and enables task execution by following natural language instructions. Our approach involves casting multiple computer vision tasks as text-to-image generation problems. Here, the text represents an instruction describing the task, and the resulting image is a visually-encoded task output. To train our model, we pool commonly-used computer vision datasets covering a range of tasks, including segmentation, object detection, depth estimation, and classification. We then use a large language model to paraphrase prompt templates that convey the specific tasks to be conducted on each image, and through this process, we create a multi-modal and multi-task training dataset comprising input and output images along with annotated instructions. Following the InstructPix2Pix architecture, we apply instruction-tuning to a text-to-image diffusion model using our constructed dataset, steering its functionality from a generative model to an instruction-guided multi-task vision learner. Experiments demonstrate that our model, dubbed InstructCV, performs competitively compared to other generalist and task-specific vision models. Moreover, it exhibits compelling generalization capabilities to unseen data, categories, and user instructions.
Curve Your Attention: Mixed-Curvature Transformers for Graph Representation Learning
Sep 08, 2023Real-world graphs naturally exhibit hierarchical or cyclical structures that are unfit for the typical Euclidean space. While there exist graph neural networks that leverage hyperbolic or spherical spaces to learn representations that embed such structures more accurately, these methods are confined under the message-passing paradigm, making the models vulnerable against side-effects such as oversmoothing and oversquashing. More recent work have proposed global attention-based graph Transformers that can easily model long-range interactions, but their extensions towards non-Euclidean geometry are yet unexplored. To bridge this gap, we propose Fully Product-Stereographic Transformer, a generalization of Transformers towards operating entirely on the product of constant curvature spaces. When combined with tokenized graph Transformers, our model can learn the curvature appropriate for the input graph in an end-to-end fashion, without the need of additional tuning on different curvature initializations. We also provide a kernelized approach to non-Euclidean attention, which enables our model to run in time and memory cost linear to the number of nodes and edges while respecting the underlying geometry. Experiments on graph reconstruction and node classification demonstrate the benefits of generalizing Transformers to the non-Euclidean domain.
DisCoHead: Audio-and-Video-Driven Talking Head Generation by Disentangled Control of Head Pose and Facial Expressions
Mar 14, 2023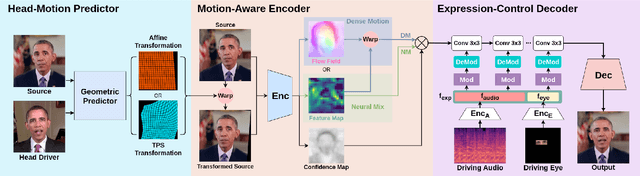
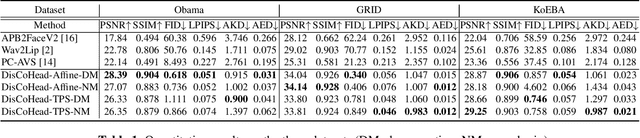


For realistic talking head generation, creating natural head motion while maintaining accurate lip synchronization is essential. To fulfill this challenging task, we propose DisCoHead, a novel method to disentangle and control head pose and facial expressions without supervision. DisCoHead uses a single geometric transformation as a bottleneck to isolate and extract head motion from a head-driving video. Either an affine or a thin-plate spline transformation can be used and both work well as geometric bottlenecks. We enhance the efficiency of DisCoHead by integrating a dense motion estimator and the encoder of a generator which are originally separate modules. Taking a step further, we also propose a neural mix approach where dense motion is estimated and applied implicitly by the encoder. After applying the disentangled head motion to a source identity, DisCoHead controls the mouth region according to speech audio, and it blinks eyes and moves eyebrows following a separate driving video of the eye region, via the weight modulation of convolutional neural networks. The experiments using multiple datasets show that DisCoHead successfully generates realistic audio-and-video-driven talking heads and outperforms state-of-the-art methods. Project page: https://deepbrainai-research.github.io/discohead/
ETF Portfolio Construction via Neural Network trained on Financial Statement Data
Jul 04, 2022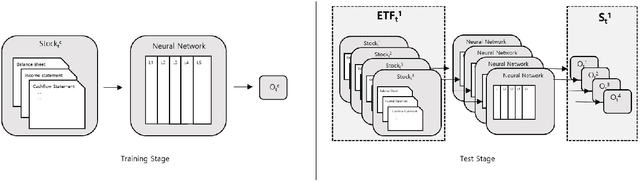
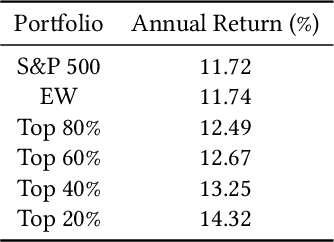
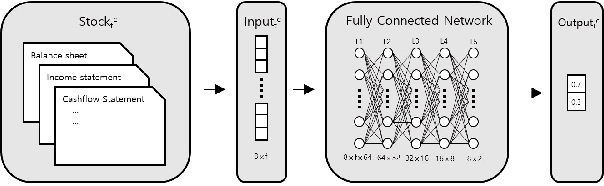
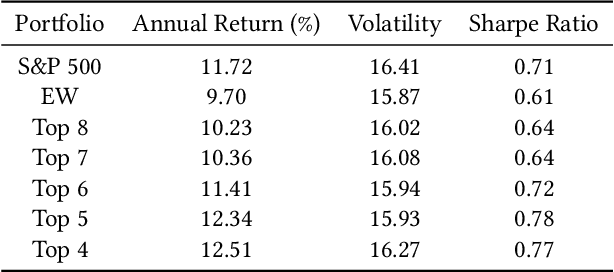
Recently, the application of advanced machine learning methods for asset management has become one of the most intriguing topics. Unfortunately, the application of these methods, such as deep neural networks, is difficult due to the data shortage problem. To address this issue, we propose a novel approach using neural networks to construct a portfolio of exchange traded funds (ETFs) based on the financial statement data of their components. Although a number of ETFs and ETF-managed portfolios have emerged in the past few decades, the ability to apply neural networks to manage ETF portfolios is limited since the number and historical existence of ETFs are relatively smaller and shorter, respectively, than those of individual stocks. Therefore, we use the data of individual stocks to train our neural networks to predict the future performance of individual stocks and use these predictions and the portfolio deposit file (PDF) to construct a portfolio of ETFs. Multiple experiments have been performed, and we have found that our proposed method outperforms the baselines. We believe that our approach can be more beneficial when managing recently listed ETFs, such as thematic ETFs, of which there is relatively limited historical data for training advanced machine learning methods.
Shai-am: A Machine Learning Platform for Investment Strategies
Jul 01, 2022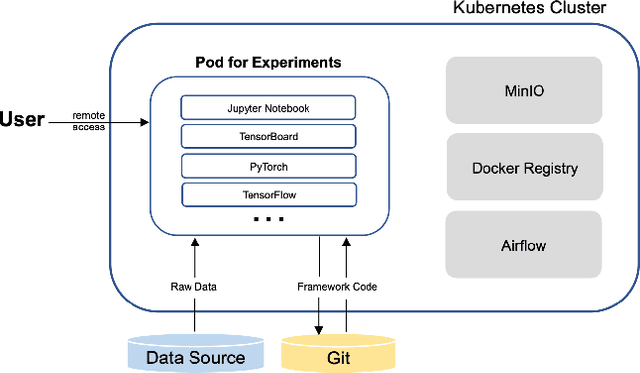
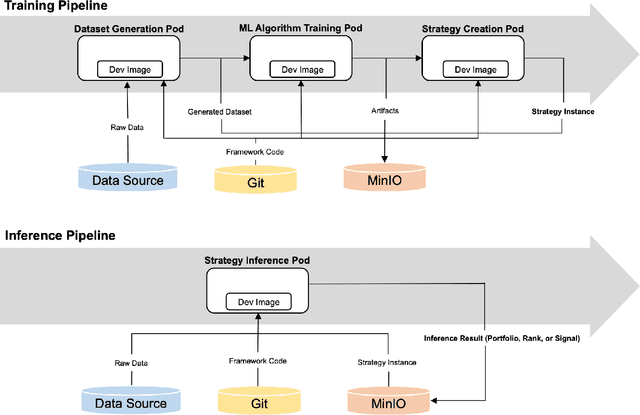
The finance industry has adopted machine learning (ML) as a form of quantitative research to support better investment decisions, yet there are several challenges often overlooked in practice. (1) ML code tends to be unstructured and ad hoc, which hinders cooperation with others. (2) Resource requirements and dependencies vary depending on which algorithm is used, so a flexible and scalable system is needed. (3) It is difficult for domain experts in traditional finance to apply their experience and knowledge in ML-based strategies unless they acquire expertise in recent technologies. This paper presents Shai-am, an ML platform integrated with our own Python framework. The platform leverages existing modern open-source technologies, managing containerized pipelines for ML-based strategies with unified interfaces to solve the aforementioned issues. Each strategy implements the interface defined in the core framework. The framework is designed to enhance reusability and readability, facilitating collaborative work in quantitative research. Shai-am aims to be a pure AI asset manager for solving various tasks in financial markets.
KoDF: A Large-scale Korean DeepFake Detection Dataset
Mar 18, 2021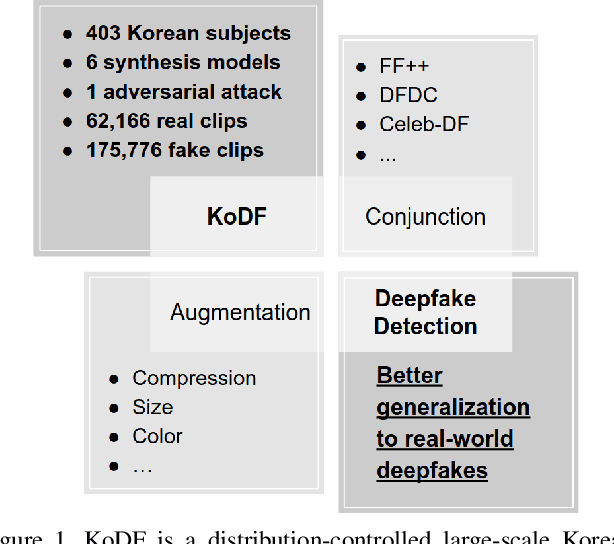
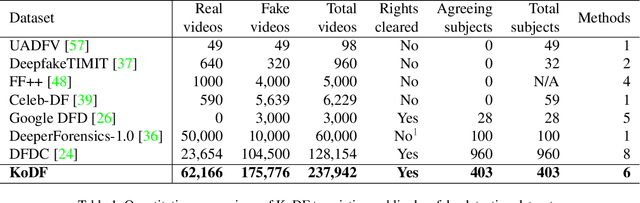
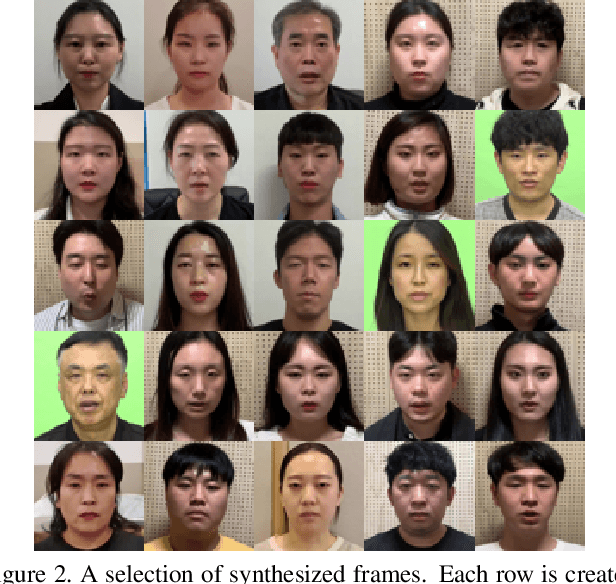
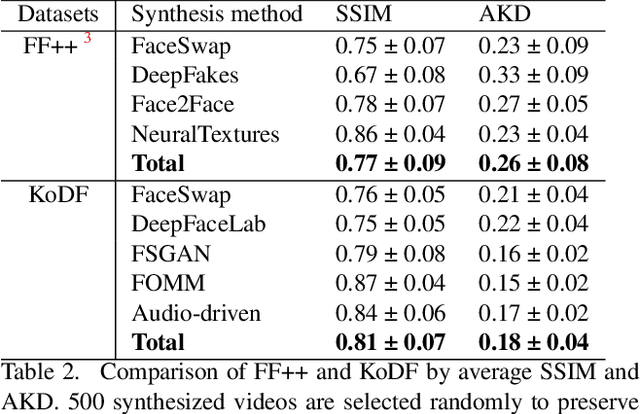
A variety of effective face-swap and face-reenactment methods have been publicized in recent years, democratizing the face synthesis technology to a great extent. Videos generated as such have come to be collectively called deepfakes with a negative connotation, for various social problems they have caused. Facing the emerging threat of deepfakes, we have built the Korean DeepFake Detection Dataset (KoDF), a large-scale collection of synthesized and real videos focused on Korean subjects. In this paper, we provide a detailed description of methods used to construct the dataset, experimentally show the discrepancy between the distributions of KoDF and existing deepfake detection datasets, and underline the importance of using multiple datasets for real-world generalization. KoDF is publicly available at https://moneybrain-research.github.io/kodf in its entirety (i.e. real clips, synthesized clips, clips with additive noise, and their corresponding metadata).