 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
Data reuse enables cost-efficient randomized trials of medical AI models
Nov 13, 2025Randomized controlled trials (RCTs) are indispensable for establishing the clinical value of medical artificial-intelligence (AI) tools, yet their high cost and long timelines hinder timely validation as new models emerge rapidly. Here, we propose BRIDGE, a data-reuse RCT design for AI-based risk models. AI risk models support a broad range of interventions, including screening, treatment selection, and clinical alerts. BRIDGE trials recycle participant-level data from completed trials of AI models when legacy and updated models make concordant predictions, thereby reducing the enrollment requirement for subsequent trials. We provide a practical checklist for investigators to assess whether reusing data from previous trials allows for valid causal inference and preserves type I error. Using real-world datasets across breast cancer, cardiovascular disease, and sepsis, we demonstrate concordance between successive AI models, with up to 64.8% overlap in top 5% high-risk cohorts. We then simulate a series of breast cancer screening studies, where our design reduced required enrollment by 46.6%--saving over US$2.8 million--while maintaining 80% power. By transforming trials into adaptive, modular studies, our proposed design makes Level I evidence generation feasible for every model iteration, thereby accelerating cost-effective translation of AI into routine care.
Dr-LLaVA: Visual Instruction Tuning with Symbolic Clinical Grounding
May 29, 2024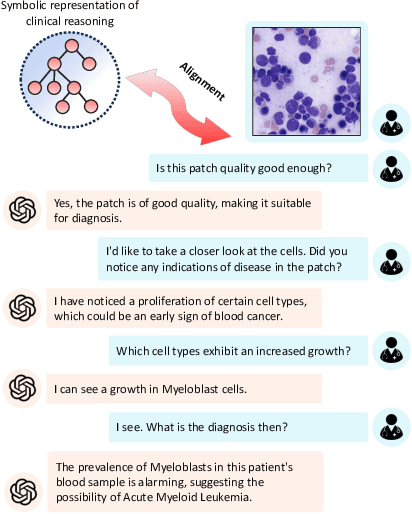
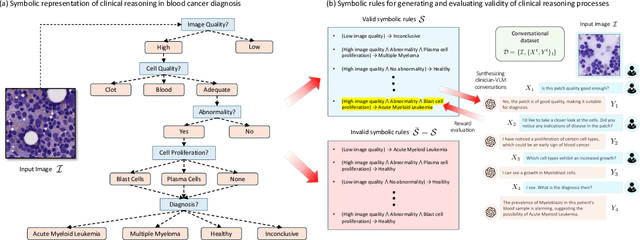
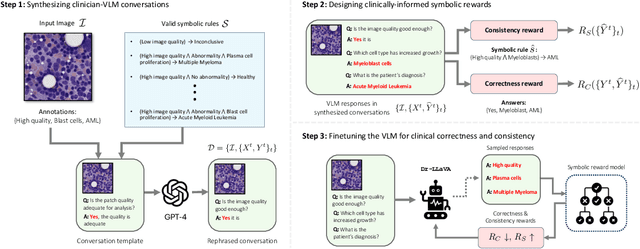
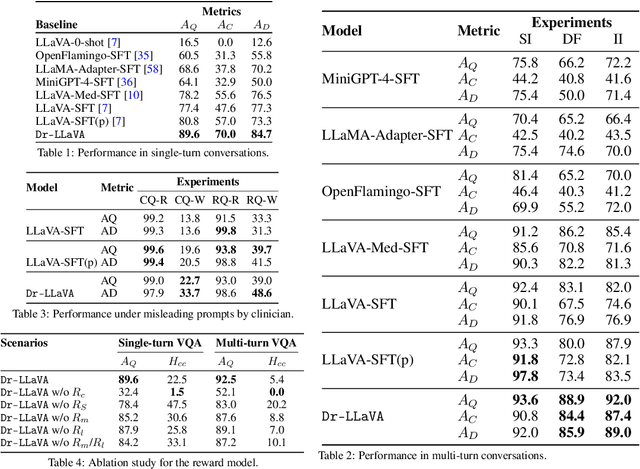
Vision-Language Models (VLM) can support clinicians by analyzing medical images and engaging in natural language interactions to assist in diagnostic and treatment tasks. However, VLMs often exhibit "hallucinogenic" behavior, generating textual outputs not grounded in contextual multimodal information. This challenge is particularly pronounced in the medical domain, where we do not only require VLM outputs to be accurate in single interactions but also to be consistent with clinical reasoning and diagnostic pathways throughout multi-turn conversations. For this purpose, we propose a new alignment algorithm that uses symbolic representations of clinical reasoning to ground VLMs in medical knowledge. These representations are utilized to (i) generate GPT-4-guided visual instruction tuning data at scale, simulating clinician-VLM conversations with demonstrations of clinical reasoning, and (ii) create an automatic reward function that evaluates the clinical validity of VLM generations throughout clinician-VLM interactions. Our algorithm eliminates the need for human involvement in training data generation or reward model construction, reducing costs compared to standard reinforcement learning with human feedback (RLHF). We apply our alignment algorithm to develop Dr-LLaVA, a conversational VLM finetuned for analyzing bone marrow pathology slides, demonstrating strong performance in multi-turn medical conversations.
InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists
Sep 30, 2023



Recent advances in generative diffusion models have enabled text-controlled synthesis of realistic and diverse images with impressive quality. Despite these remarkable advances, the application of text-to-image generative models in computer vision for standard visual recognition tasks remains limited. The current de facto approach for these tasks is to design model architectures and loss functions that are tailored to the task at hand. In this paper, we develop a unified language interface for computer vision tasks that abstracts away task-specific design choices and enables task execution by following natural language instructions. Our approach involves casting multiple computer vision tasks as text-to-image generation problems. Here, the text represents an instruction describing the task, and the resulting image is a visually-encoded task output. To train our model, we pool commonly-used computer vision datasets covering a range of tasks, including segmentation, object detection, depth estimation, and classification. We then use a large language model to paraphrase prompt templates that convey the specific tasks to be conducted on each image, and through this process, we create a multi-modal and multi-task training dataset comprising input and output images along with annotated instructions. Following the InstructPix2Pix architecture, we apply instruction-tuning to a text-to-image diffusion model using our constructed dataset, steering its functionality from a generative model to an instruction-guided multi-task vision learner. Experiments demonstrate that our model, dubbed InstructCV, performs competitively compared to other generalist and task-specific vision models. Moreover, it exhibits compelling generalization capabilities to unseen data, categories, and user instructions.
Pruning the Way to Reliable Policies: A Multi-Objective Deep Q-Learning Approach to Critical Care
Jun 13, 2023Most medical treatment decisions are sequential in nature. Hence, there is substantial hope that reinforcement learning may make it possible to formulate precise data-driven treatment plans. However, a key challenge for most applications in this field is the sparse nature of primarily mortality-based reward functions, leading to decreased stability of offline estimates. In this work, we introduce a deep Q-learning approach able to obtain more reliable critical care policies. This method integrates relevant but noisy intermediate biomarker signals into the reward specification, without compromising the optimization of the main outcome of interest (e.g. patient survival). We achieve this by first pruning the action set based on all available rewards, and second training a final model based on the sparse main reward but with a restricted action set. By disentangling accurate and approximated rewards through action pruning, potential distortions of the main objective are minimized, all while enabling the extraction of valuable information from intermediate signals that can guide the learning process. We evaluate our method in both off-policy and offline settings using simulated environments and real health records of patients in intensive care units. Our empirical results indicate that pruning significantly reduces the size of the action space while staying mostly consistent with the actions taken by physicians, outperforming the current state-of-the-art offline reinforcement learning method conservative Q-learning. Our work is a step towards developing reliable policies by effectively harnessing the wealth of available information in data-intensive critical care environments.