 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Invasive Medical Digital Twins using Physics-Informed Self-Supervised Learning
Feb 29, 2024A digital twin is a virtual replica of a real-world physical phenomena that uses mathematical modeling to characterize and simulate its defining features. By constructing digital twins for disease processes, we can perform in-silico simulations that mimic patients' health conditions and counterfactual outcomes under hypothetical interventions in a virtual setting. This eliminates the need for invasive procedures or uncertain treatment decisions. In this paper, we propose a method to identify digital twin model parameters using only noninvasive patient health data. We approach the digital twin modeling as a composite inverse problem, and observe that its structure resembles pretraining and finetuning in self-supervised learning (SSL). Leveraging this, we introduce a physics-informed SSL algorithm that initially pretrains a neural network on the pretext task of solving the physical model equations. Subsequently, the model is trained to reconstruct low-dimensional health measurements from noninvasive modalities while being constrained by the physical equations learned in pretraining. We apply our method to identify digital twins of cardiac hemodynamics using noninvasive echocardiogram videos, and demonstrate its utility in unsupervised disease detection and in-silico clinical trials.
Self-Consistent Conformal Prediction
Feb 11, 2024In decision-making guided by machine learning, decision-makers often take identical actions in contexts with identical predicted outcomes. Conformal prediction helps decision-makers quantify outcome uncertainty for actions, allowing for better risk management. Inspired by this perspective, we introduce self-consistent conformal prediction, which yields both Venn-Abers calibrated predictions and conformal prediction intervals that are valid conditional on actions prompted by model predictions. Our procedure can be applied post-hoc to any black-box predictor to provide rigorous, action-specific decision-making guarantees. Numerical experiments show our approach strikes a balance between interval efficiency and conditional validity.
Estimating Uncertainty in Multimodal Foundation Models using Public Internet Data
Oct 15, 2023Foundation models are trained on vast amounts of data at scale using self-supervised learning, enabling adaptation to a wide range of downstream tasks. At test time, these models exhibit zero-shot capabilities through which they can classify previously unseen (user-specified) categories. In this paper, we address the problem of quantifying uncertainty in these zero-shot predictions. We propose a heuristic approach for uncertainty estimation in zero-shot settings using conformal prediction with web data. Given a set of classes at test time, we conduct zero-shot classification with CLIP-style models using a prompt template, e.g., "an image of a <category>", and use the same template as a search query to source calibration data from the open web. Given a web-based calibration set, we apply conformal prediction with a novel conformity score that accounts for potential errors in retrieved web data. We evaluate the utility of our proposed method in Biomedical foundation models; our preliminary results show that web-based conformal prediction sets achieve the target coverage with satisfactory efficiency on a variety of biomedical datasets.
InstructCV: Instruction-Tuned Text-to-Image Diffusion Models as Vision Generalists
Sep 30, 2023



Recent advances in generative diffusion models have enabled text-controlled synthesis of realistic and diverse images with impressive quality. Despite these remarkable advances, the application of text-to-image generative models in computer vision for standard visual recognition tasks remains limited. The current de facto approach for these tasks is to design model architectures and loss functions that are tailored to the task at hand. In this paper, we develop a unified language interface for computer vision tasks that abstracts away task-specific design choices and enables task execution by following natural language instructions. Our approach involves casting multiple computer vision tasks as text-to-image generation problems. Here, the text represents an instruction describing the task, and the resulting image is a visually-encoded task output. To train our model, we pool commonly-used computer vision datasets covering a range of tasks, including segmentation, object detection, depth estimation, and classification. We then use a large language model to paraphrase prompt templates that convey the specific tasks to be conducted on each image, and through this process, we create a multi-modal and multi-task training dataset comprising input and output images along with annotated instructions. Following the InstructPix2Pix architecture, we apply instruction-tuning to a text-to-image diffusion model using our constructed dataset, steering its functionality from a generative model to an instruction-guided multi-task vision learner. Experiments demonstrate that our model, dubbed InstructCV, performs competitively compared to other generalist and task-specific vision models. Moreover, it exhibits compelling generalization capabilities to unseen data, categories, and user instructions.
Aligning Synthetic Medical Images with Clinical Knowledge using Human Feedback
Jun 16, 2023



Generative models capable of capturing nuanced clinical features in medical images hold great promise for facilitating clinical data sharing, enhancing rare disease datasets, and efficiently synthesizing annotated medical images at scale. Despite their potential, assessing the quality of synthetic medical images remains a challenge. While modern generative models can synthesize visually-realistic medical images, the clinical validity of these images may be called into question. Domain-agnostic scores, such as FID score, precision, and recall, cannot incorporate clinical knowledge and are, therefore, not suitable for assessing clinical sensibility. Additionally, there are numerous unpredictable ways in which generative models may fail to synthesize clinically plausible images, making it challenging to anticipate potential failures and manually design scores for their detection. To address these challenges, this paper introduces a pathologist-in-the-loop framework for generating clinically-plausible synthetic medical images. Starting with a diffusion model pretrained using real images, our framework comprises three steps: (1) evaluating the generated images by expert pathologists to assess whether they satisfy clinical desiderata, (2) training a reward model that predicts the pathologist feedback on new samples, and (3) incorporating expert knowledge into the diffusion model by using the reward model to inform a finetuning objective. We show that human feedback significantly improves the quality of synthetic images in terms of fidelity, diversity, utility in downstream applications, and plausibility as evaluated by experts.
Conformalized Unconditional Quantile Regression
Apr 04, 2023
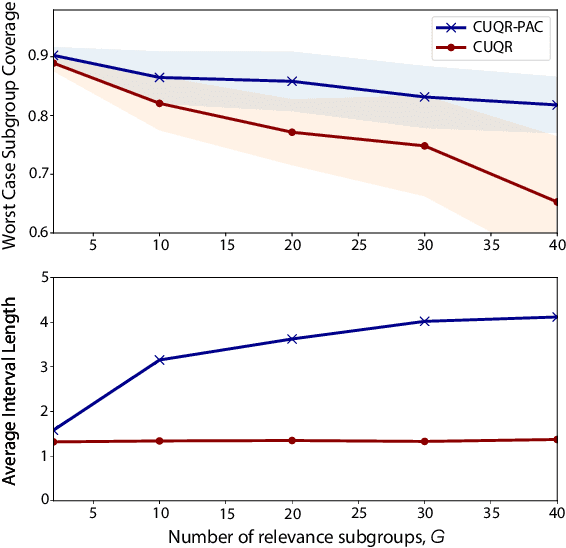


We develop a predictive inference procedure that combines conformal prediction (CP) with unconditional quantile regression (QR) -- a commonly used tool in econometrics that involves regressing the recentered influence function (RIF) of the quantile functional over input covariates. Unlike the more widely-known conditional QR, unconditional QR explicitly captures the impact of changes in covariate distribution on the quantiles of the marginal distribution of outcomes. Leveraging this property, our procedure issues adaptive predictive intervals with localized frequentist coverage guarantees. It operates by fitting a machine learning model for the RIFs using training data, and then applying the CP procedure for any test covariate with respect to a ``hypothetical'' covariate distribution localized around the new instance. Experiments show that our procedure is adaptive to heteroscedasticity, provides transparent coverage guarantees that are relevant to the test instance at hand, and performs competitively with existing methods in terms of efficiency.
How Faithful is your Synthetic Data? Sample-level Metrics for Evaluating and Auditing Generative Models
Feb 17, 2021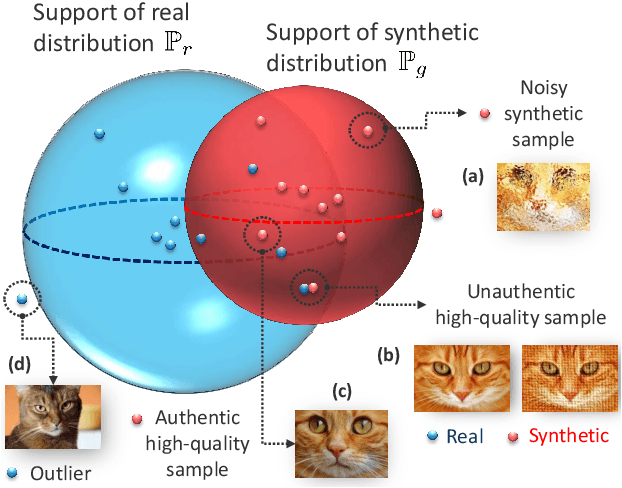

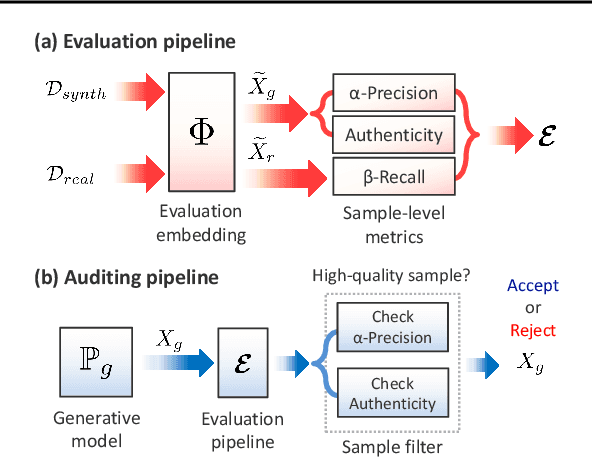
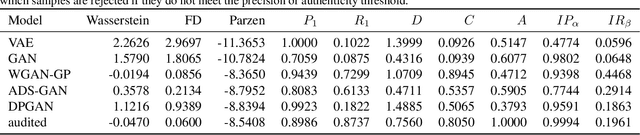
Devising domain- and model-agnostic evaluation metrics for generative models is an important and as yet unresolved problem. Most existing metrics, which were tailored solely to the image synthesis setup, exhibit a limited capacity for diagnosing the different modes of failure of generative models across broader application domains. In this paper, we introduce a 3-dimensional evaluation metric, ($\alpha$-Precision, $\beta$-Recall, Authenticity), that characterizes the fidelity, diversity and generalization performance of any generative model in a domain-agnostic fashion. Our metric unifies statistical divergence measures with precision-recall analysis, enabling sample- and distribution-level diagnoses of model fidelity and diversity. We introduce generalization as an additional, independent dimension (to the fidelity-diversity trade-off) that quantifies the extent to which a model copies training data -- a crucial performance indicator when modeling sensitive data with requirements on privacy. The three metric components correspond to (interpretable) probabilistic quantities, and are estimated via sample-level binary classification. The sample-level nature of our metric inspires a novel use case which we call model auditing, wherein we judge the quality of individual samples generated by a (black-box) model, discarding low-quality samples and hence improving the overall model performance in a post-hoc manner.
Learning Matching Representations for Individualized Organ Transplantation Allocation
Feb 02, 2021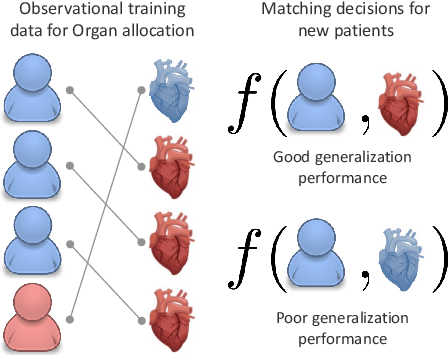
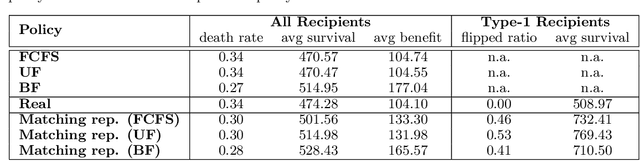
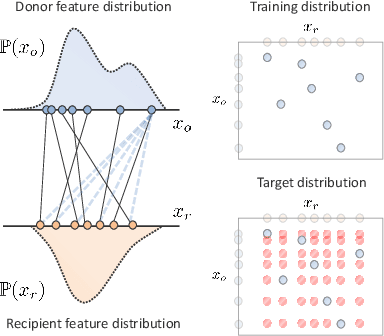

Organ transplantation is often the last resort for treating end-stage illness, but the probability of a successful transplantation depends greatly on compatibility between donors and recipients. Current medical practice relies on coarse rules for donor-recipient matching, but is short of domain knowledge regarding the complex factors underlying organ compatibility. In this paper, we formulate the problem of learning data-driven rules for organ matching using observational data for organ allocations and transplant outcomes. This problem departs from the standard supervised learning setup in that it involves matching the two feature spaces (i.e., donors and recipients), and requires estimating transplant outcomes under counterfactual matches not observed in the data. To address these problems, we propose a model based on representation learning to predict donor-recipient compatibility; our model learns representations that cluster donor features, and applies donor-invariant transformations to recipient features to predict outcomes for a given donor-recipient feature instance. Experiments on semi-synthetic and real-world datasets show that our model outperforms state-of-art allocation methods and policies executed by human experts.
Semiparametric Estimation and Inference on Structural Target Functions using Machine Learning and Influence Functions
Sep 14, 2020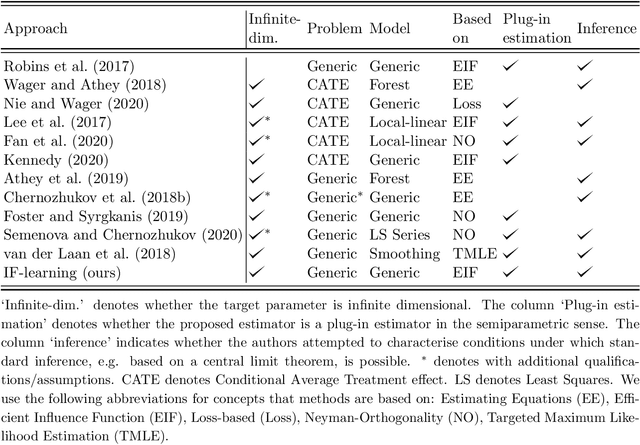
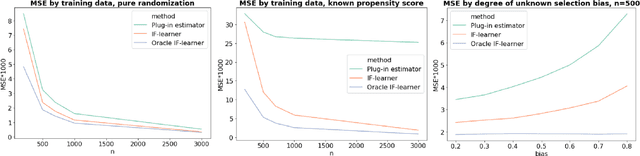
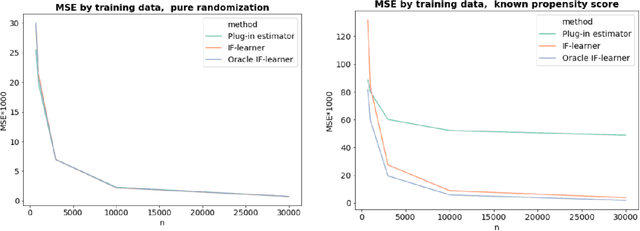
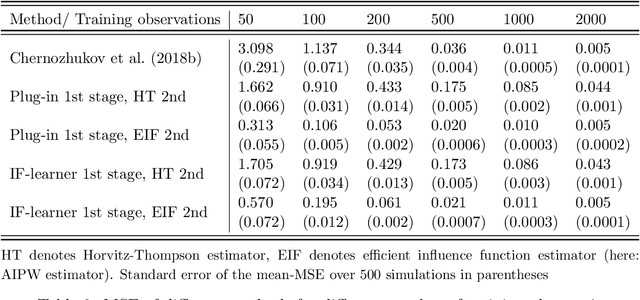
We aim to construct a class of learning algorithms that are of practical value to applied researchers in fields such as biostatistics, epidemiology and econometrics, where the need to learn from incompletely observed information is ubiquitous. To do so, we propose a new framework for statistical machine learning, which we call 'IF-learning' due to its reliance on influence functions (IFs). To characterise the fundamental limits of what is achievable within this framework, we need to enable semiparametric estimation and inference on structural target parameters that are functions of continuous inputs arising as identifiable functionals from statistical models. Therefore, we introduce a pointwise IF to replace the true IF when it does not exist and propose learning its uncentered pointwise expected value from data. This allows us to give provable guarantees, leveraging existing general results from statistics. Our framework is problem- and model-agnostic and can be used to estimate a broad variety of target parameters of interest in applied statistics: we can consider any target function for which an IF of a population-averaged version exists in analytic form. Throughout, we put particular focus on so-called coarsening at random/doubly robust problems with partially unobserved information. This includes problems such as treatment effect estimation and inference in the presence of missing outcome data. Within this framework, we then propose two general learning algorithms that leverage ideas from the theoretical analysis: the 'IF-learner' which relies on large samples and outputs entire target functions without confidence bands, and the 'Group-IF-learner', which outputs only approximations to a function but can give confidence estimates if sufficient information on coarsening mechanisms is available. We close with a simulation study on inferring treatment effects.
CPAS: the UK's National Machine Learning-based Hospital Capacity Planning System for COVID-19
Jul 27, 2020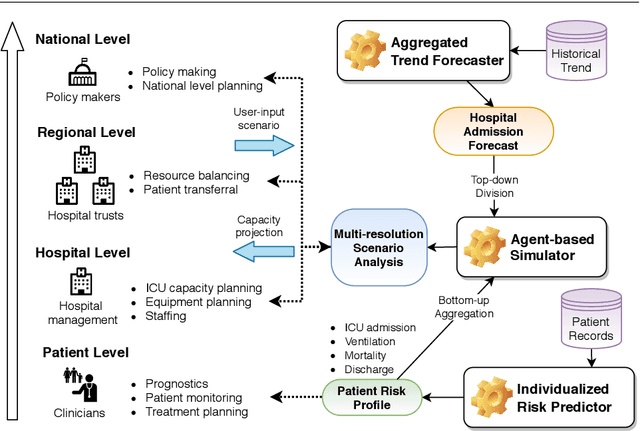
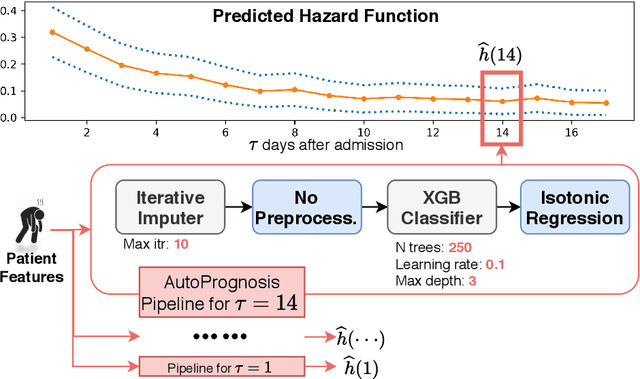
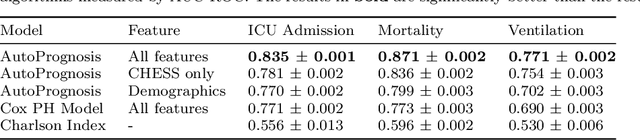

The coronavirus disease 2019 (COVID-19) global pandemic poses the threat of overwhelming healthcare systems with unprecedented demands for intensive care resources. Managing these demands cannot be effectively conducted without a nationwide collective effort that relies on data to forecast hospital demands on the national, regional, hospital and individual levels. To this end, we developed the COVID-19 Capacity Planning and Analysis System (CPAS) - a machine learning-based system for hospital resource planning that we have successfully deployed at individual hospitals and across regions in the UK in coordination with NHS Digital. In this paper, we discuss the main challenges of deploying a machine learning-based decision support system at national scale, and explain how CPAS addresses these challenges by (1) defining the appropriate learning problem, (2) combining bottom-up and top-down analytical approaches, (3) using state-of-the-art machine learning algorithms, (4) integrating heterogeneous data sources, and (5) presenting the result with an interactive and transparent interface. CPAS is one of the first machine learning-based systems to be deployed in hospitals on a national scale to address the COVID-19 pandemic - we conclude the paper with a summary of the lessons learned from this experience.