 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemiparametric Estimation and Inference on Structural Target Functions using Machine Learning and Influence Functions
Paper and Code
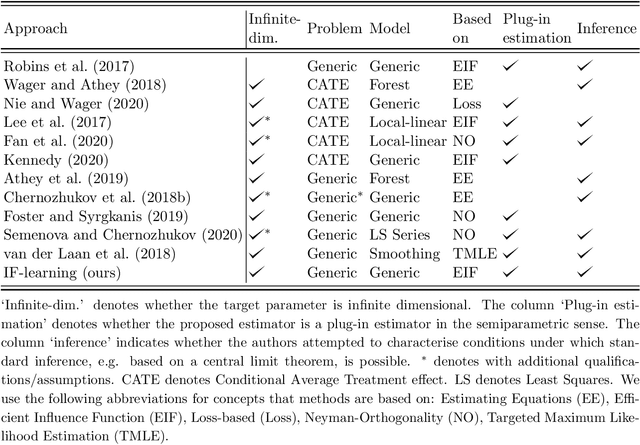
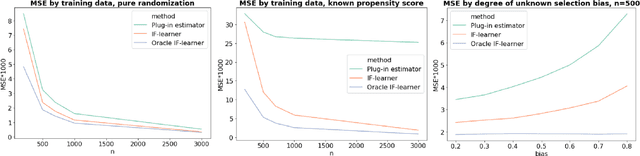
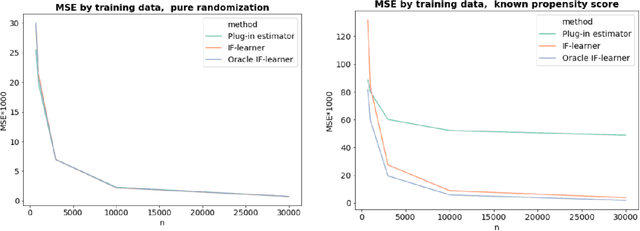
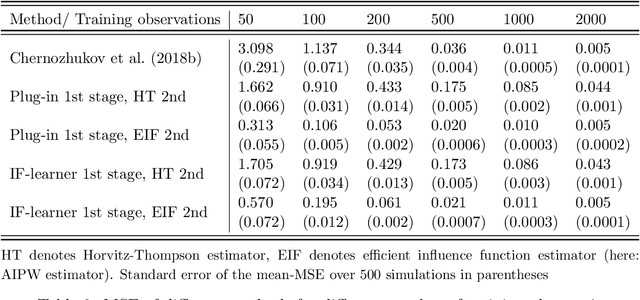
We aim to construct a class of learning algorithms that are of practical value to applied researchers in fields such as biostatistics, epidemiology and econometrics, where the need to learn from incompletely observed information is ubiquitous. To do so, we propose a new framework for statistical machine learning, which we call 'IF-learning' due to its reliance on influence functions (IFs). To characterise the fundamental limits of what is achievable within this framework, we need to enable semiparametric estimation and inference on structural target parameters that are functions of continuous inputs arising as identifiable functionals from statistical models. Therefore, we introduce a pointwise IF to replace the true IF when it does not exist and propose learning its uncentered pointwise expected value from data. This allows us to give provable guarantees, leveraging existing general results from statistics. Our framework is problem- and model-agnostic and can be used to estimate a broad variety of target parameters of interest in applied statistics: we can consider any target function for which an IF of a population-averaged version exists in analytic form. Throughout, we put particular focus on so-called coarsening at random/doubly robust problems with partially unobserved information. This includes problems such as treatment effect estimation and inference in the presence of missing outcome data. Within this framework, we then propose two general learning algorithms that leverage ideas from the theoretical analysis: the 'IF-learner' which relies on large samples and outputs entire target functions without confidence bands, and the 'Group-IF-learner', which outputs only approximations to a function but can give confidence estimates if sufficient information on coarsening mechanisms is available. We close with a simulation study on inferring treatment effects.