 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Alignment with Heterogeneous Preferences
Feb 22, 2025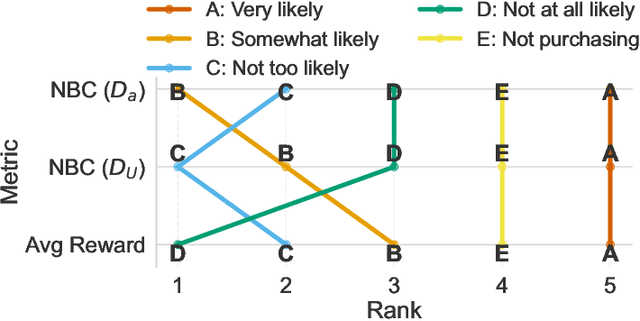

Alignment with human preferences is commonly framed using a universal reward function, even though human preferences are inherently heterogeneous. We formalize this heterogeneity by introducing user types and examine the limits of the homogeneity assumption. We show that aligning to heterogeneous preferences with a single policy is best achieved using the average reward across user types. However, this requires additional information about annotators. We examine improvements under different information settings, focusing on direct alignment methods. We find that minimal information can yield first-order improvements, while full feedback from each user type leads to consistent learning of the optimal policy. Surprisingly, however, no sample-efficient consistent direct loss exists in this latter setting. These results reveal a fundamental tension between consistency and sample efficiency in direct policy alignment.
Allocation Requires Prediction Only if Inequality Is Low
Jun 19, 2024
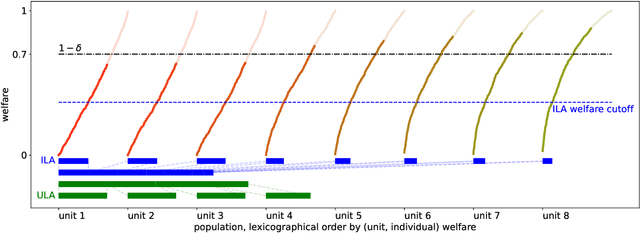
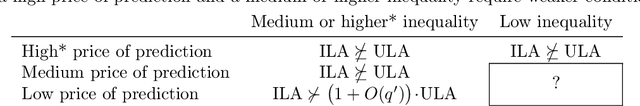

Algorithmic predictions are emerging as a promising solution concept for efficiently allocating societal resources. Fueling their use is an underlying assumption that such systems are necessary to identify individuals for interventions. We propose a principled framework for assessing this assumption: Using a simple mathematical model, we evaluate the efficacy of prediction-based allocations in settings where individuals belong to larger units such as hospitals, neighborhoods, or schools. We find that prediction-based allocations outperform baseline methods using aggregate unit-level statistics only when between-unit inequality is low and the intervention budget is high. Our results hold for a wide range of settings for the price of prediction, treatment effect heterogeneity, and unit-level statistics' learnability. Combined, we highlight the potential limits to improving the efficacy of interventions through prediction.
Collective Counterfactual Explanations via Optimal Transport
Feb 07, 2024Counterfactual explanations provide individuals with cost-optimal actions that can alter their labels to desired classes. However, if substantial instances seek state modification, such individual-centric methods can lead to new competitions and unanticipated costs. Furthermore, these recommendations, disregarding the underlying data distribution, may suggest actions that users perceive as outliers. To address these issues, our work proposes a collective approach for formulating counterfactual explanations, with an emphasis on utilizing the current density of the individuals to inform the recommended actions. Our problem naturally casts as an optimal transport problem. Leveraging the extensive literature on optimal transport, we illustrate how this collective method improves upon the desiderata of classical counterfactual explanations. We support our proposal with numerical simulations, illustrating the effectiveness of the proposed approach and its relation to classic methods.
What Makes ImageNet Look Unlike LAION
Jun 27, 2023



ImageNet was famously created from Flickr image search results. What if we recreated ImageNet instead by searching the massive LAION dataset based on image captions alone? In this work, we carry out this counterfactual investigation. We find that the resulting ImageNet recreation, which we call LAIONet, looks distinctly unlike the original. Specifically, the intra-class similarity of images in the original ImageNet is dramatically higher than it is for LAIONet. Consequently, models trained on ImageNet perform significantly worse on LAIONet. We propose a rigorous explanation for the discrepancy in terms of a subtle, yet important, difference in two plausible causal data-generating processes for the respective datasets, that we support with systematic experimentation. In a nutshell, searching based on an image caption alone creates an information bottleneck that mitigates the selection bias otherwise present in image-based filtering. Our explanation formalizes a long-held intuition in the community that ImageNet images are stereotypical, unnatural, and overly simple representations of the class category. At the same time, it provides a simple and actionable takeaway for future dataset creation efforts.
Pruning the Way to Reliable Policies: A Multi-Objective Deep Q-Learning Approach to Critical Care
Jun 13, 2023Most medical treatment decisions are sequential in nature. Hence, there is substantial hope that reinforcement learning may make it possible to formulate precise data-driven treatment plans. However, a key challenge for most applications in this field is the sparse nature of primarily mortality-based reward functions, leading to decreased stability of offline estimates. In this work, we introduce a deep Q-learning approach able to obtain more reliable critical care policies. This method integrates relevant but noisy intermediate biomarker signals into the reward specification, without compromising the optimization of the main outcome of interest (e.g. patient survival). We achieve this by first pruning the action set based on all available rewards, and second training a final model based on the sparse main reward but with a restricted action set. By disentangling accurate and approximated rewards through action pruning, potential distortions of the main objective are minimized, all while enabling the extraction of valuable information from intermediate signals that can guide the learning process. We evaluate our method in both off-policy and offline settings using simulated environments and real health records of patients in intensive care units. Our empirical results indicate that pruning significantly reduces the size of the action space while staying mostly consistent with the actions taken by physicians, outperforming the current state-of-the-art offline reinforcement learning method conservative Q-learning. Our work is a step towards developing reliable policies by effectively harnessing the wealth of available information in data-intensive critical care environments.
A Theory of Dynamic Benchmarks
Oct 06, 2022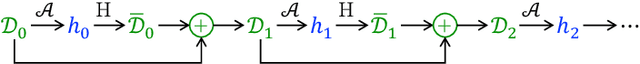
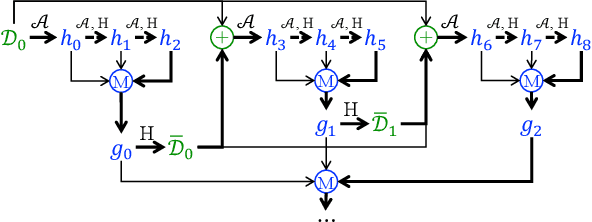
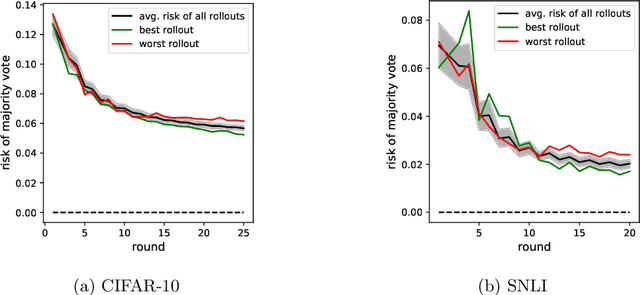
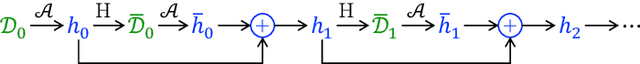
Dynamic benchmarks interweave model fitting and data collection in an attempt to mitigate the limitations of static benchmarks. In contrast to an extensive theoretical and empirical study of the static setting, the dynamic counterpart lags behind due to limited empirical studies and no apparent theoretical foundation to date. Responding to this deficit, we initiate a theoretical study of dynamic benchmarking. We examine two realizations, one capturing current practice and the other modeling more complex settings. In the first model, where data collection and model fitting alternate sequentially, we prove that model performance improves initially but can stall after only three rounds. Label noise arising from, for instance, annotator disagreement leads to even stronger negative results. Our second model generalizes the first to the case where data collection and model fitting have a hierarchical dependency structure. We show that this design guarantees strictly more progress than the first, albeit at a significant increase in complexity. We support our theoretical analysis by simulating dynamic benchmarks on two popular datasets. These results illuminate the benefits and practical limitations of dynamic benchmarking, providing both a theoretical foundation and a causal explanation for observed bottlenecks in empirical work.
Sequential Nature of Recommender Systems Disrupts the Evaluation Process
May 26, 2022



Datasets are often generated in a sequential manner, where the previous samples and intermediate decisions or interventions affect subsequent samples. This is especially prominent in cases where there are significant human-AI interactions, such as in recommender systems. To characterize the importance of this relationship across samples, we propose to use adversarial attacks on popular evaluation processes. We present sequence-aware boosting attacks and provide a lower bound on the amount of extra information that can be exploited from a confidential test set solely based on the order of the observed data. We use real and synthetic data to test our methods and show that the evaluation process on the MovieLense-100k dataset can be affected by $\sim1\%$ which is important when considering the close competition. Codes are publicly available.