 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Ambiguity Sets for Distributionally Robust Optimization Using Structural Causal Optimal Transport
Oct 01, 2025Distributionally robust optimization tackles out-of-sample issues like overfitting and distribution shifts by adopting an adversarial approach over a range of possible data distributions, known as the ambiguity set. To balance conservatism and accuracy, these sets must include realistic probability distributions by leveraging information from the nominal distribution. Assuming that nominal distributions arise from a structural causal model with a directed acyclic graph $\mathcal{G}$ and structural equations, previous methods such as adapted and $\mathcal{G}$-causal optimal transport have only utilized causal graph information in designing ambiguity sets. In this work, we propose incorporating structural equations, which include causal graph information, to enhance ambiguity sets, resulting in more realistic distributions. We introduce structural causal optimal transport and its associated ambiguity set, demonstrating their advantages and connections to previous methods. A key benefit of our approach is a relaxed version, where a regularization term replaces the complex causal constraints, enabling an efficient algorithm via difference-of-convex programming to solve structural causal optimal transport. We also show that when structural information is absent and must be estimated, our approach remains effective and provides finite sample guarantees. Lastly, we address the radius of ambiguity sets, illustrating how our method overcomes the curse of dimensionality in optimal transport problems, achieving faster shrinkage with dimension-free order.
Online Decision Deferral under Budget Constraints
Sep 30, 2024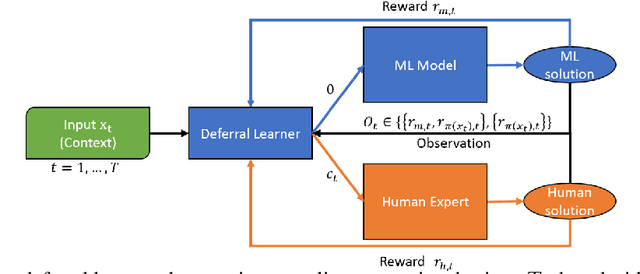
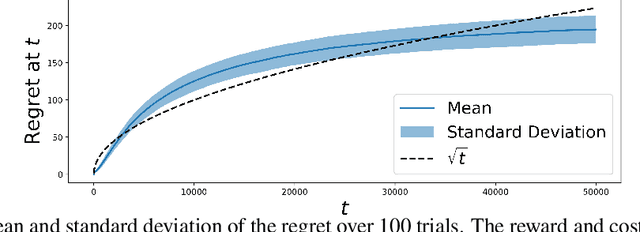
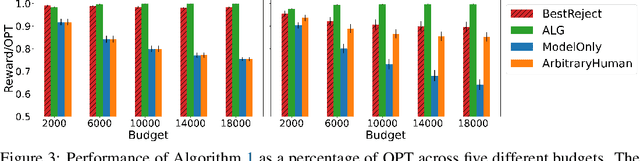
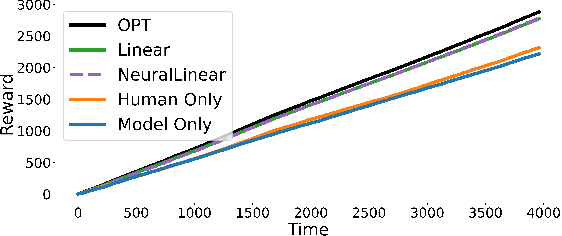
Machine Learning (ML) models are increasingly used to support or substitute decision making. In applications where skilled experts are a limited resource, it is crucial to reduce their burden and automate decisions when the performance of an ML model is at least of equal quality. However, models are often pre-trained and fixed, while tasks arrive sequentially and their distribution may shift. In that case, the respective performance of the decision makers may change, and the deferral algorithm must remain adaptive. We propose a contextual bandit model of this online decision making problem. Our framework includes budget constraints and different types of partial feedback models. Beyond the theoretical guarantees of our algorithm, we propose efficient extensions that achieve remarkable performance on real-world datasets.
A Unifying Post-Processing Framework for Multi-Objective Learn-to-Defer Problems
Jul 17, 2024Learn-to-Defer is a paradigm that enables learning algorithms to work not in isolation but as a team with human experts. In this paradigm, we permit the system to defer a subset of its tasks to the expert. Although there are currently systems that follow this paradigm and are designed to optimize the accuracy of the final human-AI team, the general methodology for developing such systems under a set of constraints (e.g., algorithmic fairness, expert intervention budget, defer of anomaly, etc.) remains largely unexplored. In this paper, using a $d$-dimensional generalization to the fundamental lemma of Neyman and Pearson (d-GNP), we obtain the Bayes optimal solution for learn-to-defer systems under various constraints. Furthermore, we design a generalizable algorithm to estimate that solution and apply this algorithm to the COMPAS and ACSIncome datasets. Our algorithm shows improvements in terms of constraint violation over a set of baselines.
A Dynamic Model of Performative Human-ML Collaboration: Theory and Empirical Evidence
May 22, 2024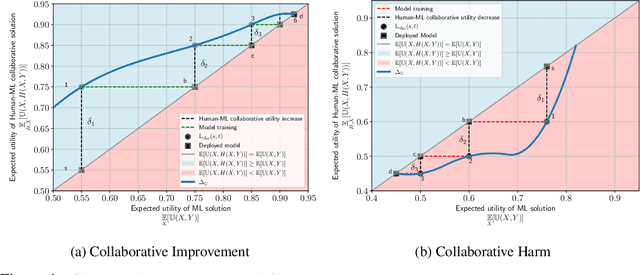
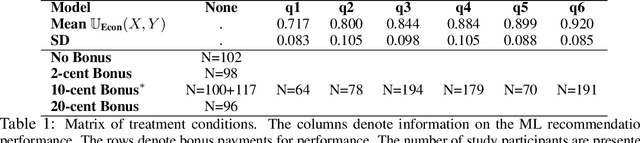
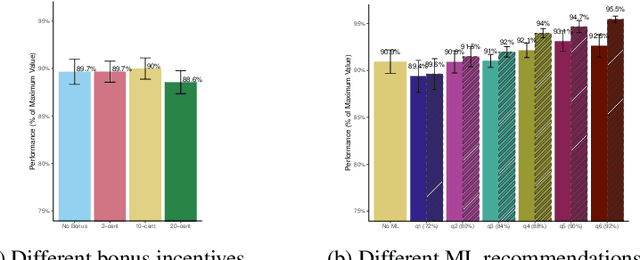
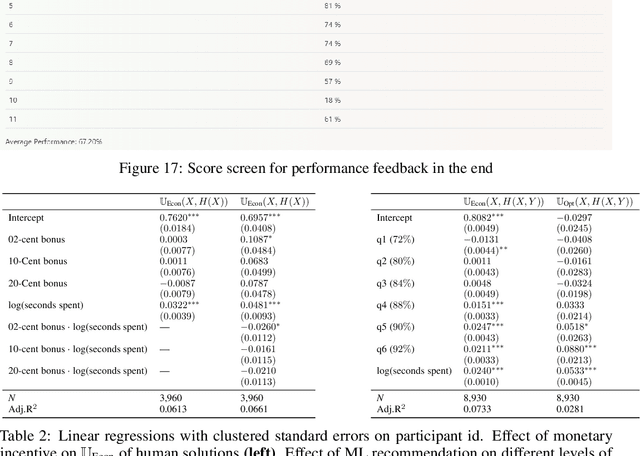
Machine learning (ML) models are increasingly used in various applications, from recommendation systems in e-commerce to diagnosis prediction in healthcare. In this paper, we present a novel dynamic framework for thinking about the deployment of ML models in a performative, human-ML collaborative system. In our framework, the introduction of ML recommendations changes the data generating process of human decisions, which are only a proxy to the ground truth and which are then used to train future versions of the model. We show that this dynamic process in principle can converge to different stable points, i.e. where the ML model and the Human+ML system have the same performance. Some of these stable points are suboptimal with respect to the actual ground truth. We conduct an empirical user study with 1,408 participants to showcase this process. In the study, humans solve instances of the knapsack problem with the help of machine learning predictions. This is an ideal setting because we can see how ML models learn to imitate human decisions and how this learning process converges to a stable point. We find that for many levels of ML performance, humans can improve the ML predictions to dynamically reach an equilibrium performance that is around 92% of the maximum knapsack value. We also find that the equilibrium performance could be even higher if humans rationally followed the ML recommendations. Finally, we test whether monetary incentives can increase the quality of human decisions, but we fail to find any positive effect. Our results have practical implications for the deployment of ML models in contexts where human decisions may deviate from the indisputable ground truth.
The Role of Learning Algorithms in Collective Action
May 10, 2024Collective action in Machine Learning is the study of the control that a coordinated group can have over machine learning algorithms. While previous research has concentrated on assessing the impact of collectives against Bayes optimal classifiers, this perspective is limited, given that in reality, classifiers seldom achieve Bayes optimality and are influenced by the choice of learning algorithms along with their inherent inductive biases. In this work, we initiate the study of how the choice of the learning algorithm plays a role in the success of a collective in practical settings. Specifically, we focus on distributionally robust algorithms (DRO), popular for improving a worst group error, and on the popular stochastic gradient descent (SGD), due to its inductive bias for "simpler" functions. Our empirical results, supported by a theoretical foundation, show that the effective size and success of the collective are highly dependent on properties of the learning algorithm. This highlights the necessity of taking the learning algorithm into account when studying the impact of collective action in Machine learning.
Collective Counterfactual Explanations via Optimal Transport
Feb 07, 2024Counterfactual explanations provide individuals with cost-optimal actions that can alter their labels to desired classes. However, if substantial instances seek state modification, such individual-centric methods can lead to new competitions and unanticipated costs. Furthermore, these recommendations, disregarding the underlying data distribution, may suggest actions that users perceive as outliers. To address these issues, our work proposes a collective approach for formulating counterfactual explanations, with an emphasis on utilizing the current density of the individuals to inform the recommended actions. Our problem naturally casts as an optimal transport problem. Leveraging the extensive literature on optimal transport, we illustrate how this collective method improves upon the desiderata of classical counterfactual explanations. We support our proposal with numerical simulations, illustrating the effectiveness of the proposed approach and its relation to classic methods.
Do personality tests generalize to Large Language Models?
Nov 09, 2023With large language models (LLMs) appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate various properties of these models using tests originally designed for humans. While re-using existing tests is a resource-efficient way to evaluate LLMs, careful adjustments are usually required to ensure that test results are even valid across human sub-populations. Thus, it is not clear to what extent different tests' validity generalizes to LLMs. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from typical human responses, implying that these results cannot be interpreted in the same way as human test results. Concretely, reverse-coded items (e.g. "I am introverted" vs "I am extraverted") are often both answered affirmatively by LLMs. In addition, variation across different prompts designed to "steer" LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe it is important to pay more attention to tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' "personality".
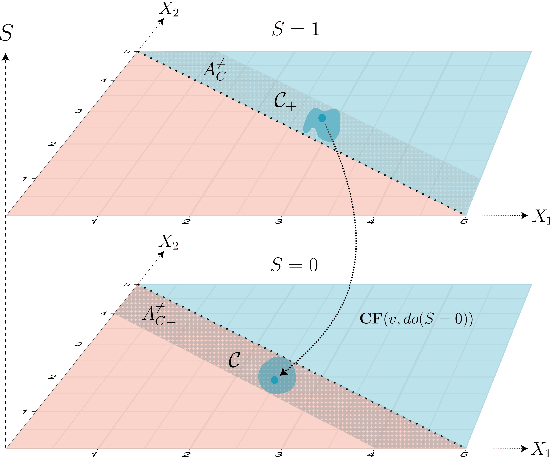
Causal Fair Metric: Bridging Causality, Individual Fairness, and Adversarial Robustness
Oct 30, 2023Adversarial perturbation is used to expose vulnerabilities in machine learning models, while the concept of individual fairness aims to ensure equitable treatment regardless of sensitive attributes. Despite their initial differences, both concepts rely on metrics to generate similar input data instances. These metrics should be designed to align with the data's characteristics, especially when it is derived from causal structure and should reflect counterfactuals proximity. Previous attempts to define such metrics often lack general assumptions about data or structural causal models. In this research, we introduce a causal fair metric formulated based on causal structures that encompass sensitive attributes. For robustness analysis, the concept of protected causal perturbation is presented. Additionally, we delve into metric learning, proposing a method for metric estimation and deployment in real-world problems. The introduced metric has applications in the fields adversarial training, fair learning, algorithmic recourse, and causal reinforcement learning.
Causal Adversarial Perturbations for Individual Fairness and Robustness in Heterogeneous Data Spaces
Aug 17, 2023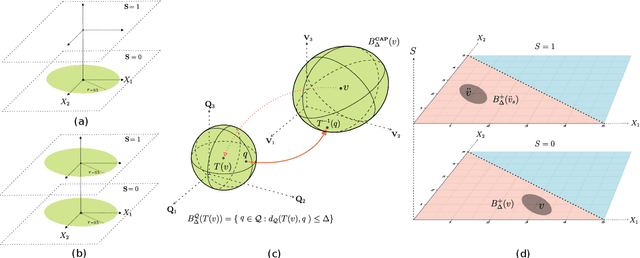

As responsible AI gains importance in machine learning algorithms, properties such as fairness, adversarial robustness, and causality have received considerable attention in recent years. However, despite their individual significance, there remains a critical gap in simultaneously exploring and integrating these properties. In this paper, we propose a novel approach that examines the relationship between individual fairness, adversarial robustness, and structural causal models in heterogeneous data spaces, particularly when dealing with discrete sensitive attributes. We use causal structural models and sensitive attributes to create a fair metric and apply it to measure semantic similarity among individuals. By introducing a novel causal adversarial perturbation and applying adversarial training, we create a new regularizer that combines individual fairness, causality, and robustness in the classifier. Our method is evaluated on both real-world and synthetic datasets, demonstrating its effectiveness in achieving an accurate classifier that simultaneously exhibits fairness, adversarial robustness, and causal awareness.
Sample Efficient Learning of Predictors that Complement Humans
Jul 19, 2022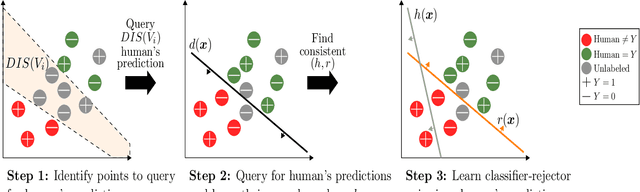
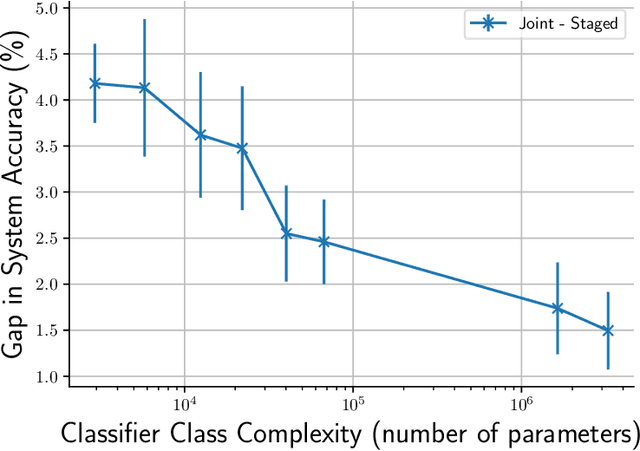
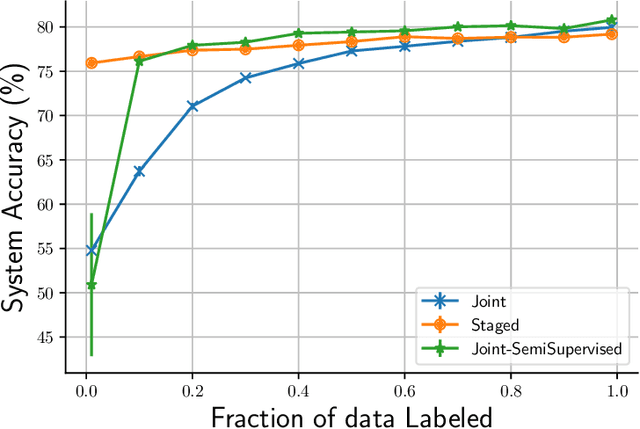
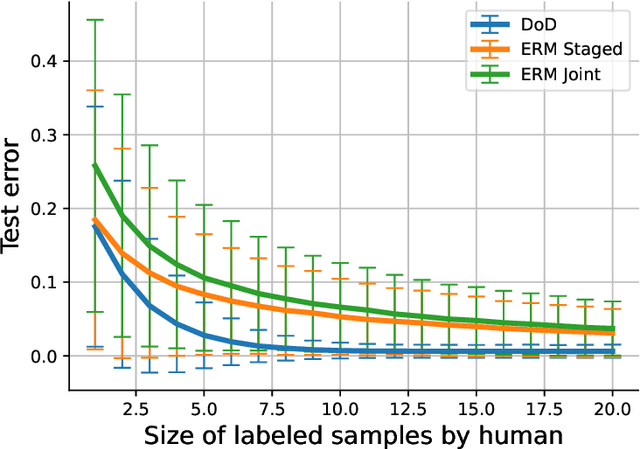
One of the goals of learning algorithms is to complement and reduce the burden on human decision makers. The expert deferral setting wherein an algorithm can either predict on its own or defer the decision to a downstream expert helps accomplish this goal. A fundamental aspect of this setting is the need to learn complementary predictors that improve on the human's weaknesses rather than learning predictors optimized for average error. In this work, we provide the first theoretical analysis of the benefit of learning complementary predictors in expert deferral. To enable efficiently learning such predictors, we consider a family of consistent surrogate loss functions for expert deferral and analyze their theoretical properties. Finally, we design active learning schemes that require minimal amount of data of human expert predictions in order to learn accurate deferral systems.