 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamic Model of Performative Human-ML Collaboration: Theory and Empirical Evidence
Paper and Code
May 22, 2024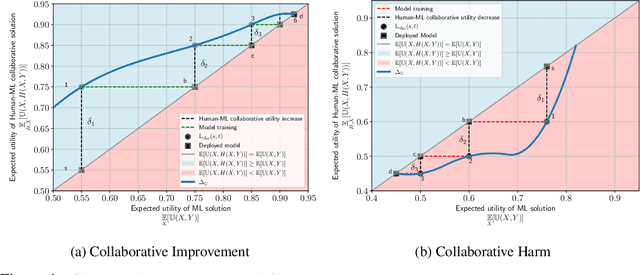
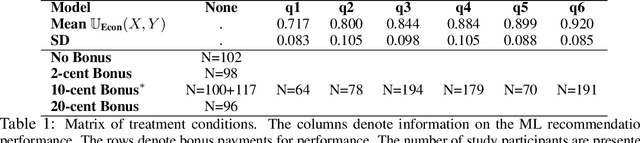
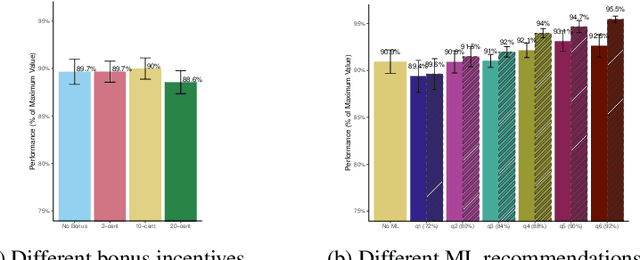
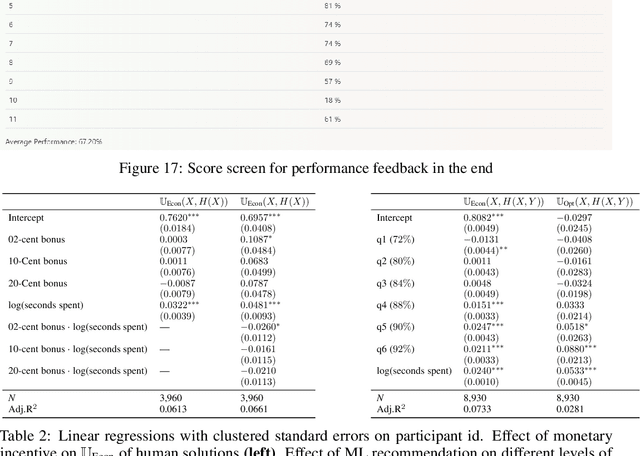
Machine learning (ML) models are increasingly used in various applications, from recommendation systems in e-commerce to diagnosis prediction in healthcare. In this paper, we present a novel dynamic framework for thinking about the deployment of ML models in a performative, human-ML collaborative system. In our framework, the introduction of ML recommendations changes the data generating process of human decisions, which are only a proxy to the ground truth and which are then used to train future versions of the model. We show that this dynamic process in principle can converge to different stable points, i.e. where the ML model and the Human+ML system have the same performance. Some of these stable points are suboptimal with respect to the actual ground truth. We conduct an empirical user study with 1,408 participants to showcase this process. In the study, humans solve instances of the knapsack problem with the help of machine learning predictions. This is an ideal setting because we can see how ML models learn to imitate human decisions and how this learning process converges to a stable point. We find that for many levels of ML performance, humans can improve the ML predictions to dynamically reach an equilibrium performance that is around 92% of the maximum knapsack value. We also find that the equilibrium performance could be even higher if humans rationally followed the ML recommendations. Finally, we test whether monetary incentives can increase the quality of human decisions, but we fail to find any positive effect. Our results have practical implications for the deployment of ML models in contexts where human decisions may deviate from the indisputable ground truth.