 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Decision Deferral under Budget Constraints
Sep 30, 2024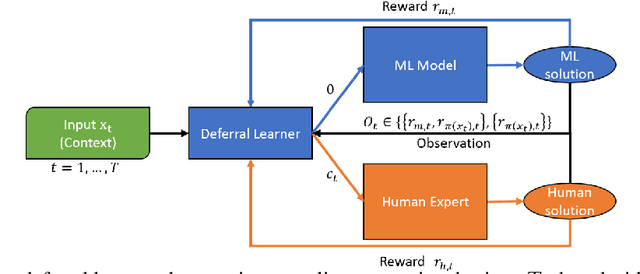
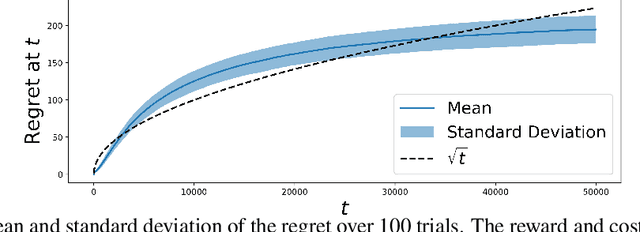
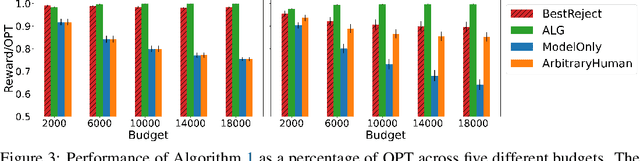
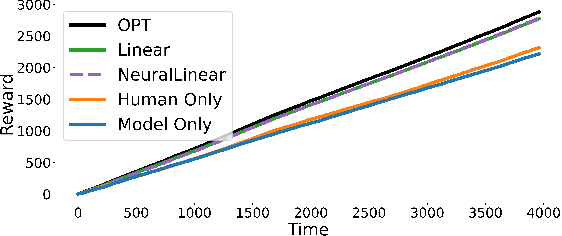
Machine Learning (ML) models are increasingly used to support or substitute decision making. In applications where skilled experts are a limited resource, it is crucial to reduce their burden and automate decisions when the performance of an ML model is at least of equal quality. However, models are often pre-trained and fixed, while tasks arrive sequentially and their distribution may shift. In that case, the respective performance of the decision makers may change, and the deferral algorithm must remain adaptive. We propose a contextual bandit model of this online decision making problem. Our framework includes budget constraints and different types of partial feedback models. Beyond the theoretical guarantees of our algorithm, we propose efficient extensions that achieve remarkable performance on real-world datasets.
A Dynamic Model of Performative Human-ML Collaboration: Theory and Empirical Evidence
May 22, 2024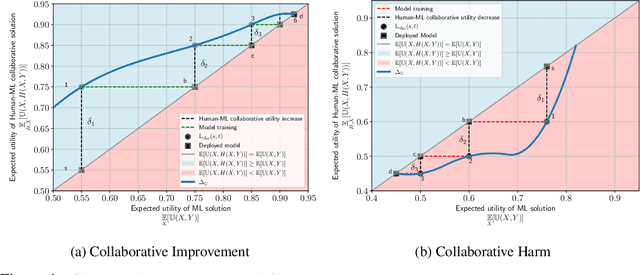
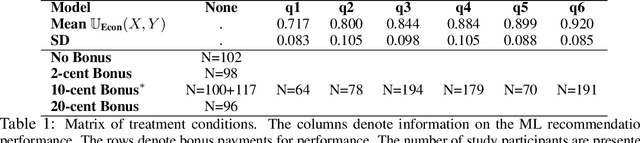
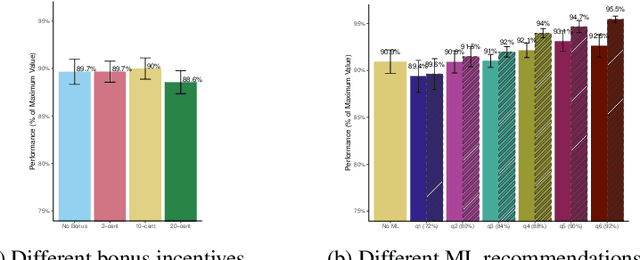
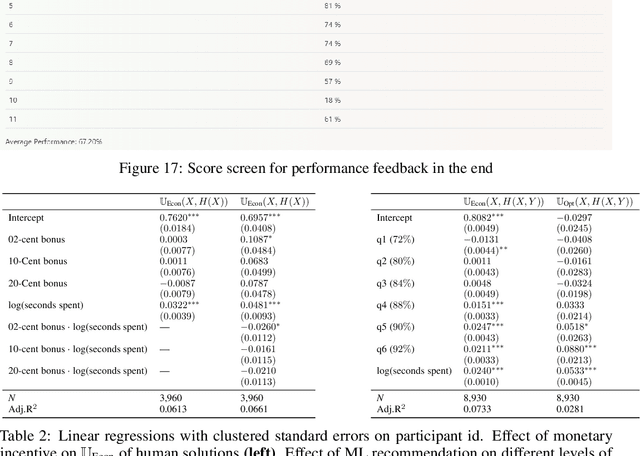
Machine learning (ML) models are increasingly used in various applications, from recommendation systems in e-commerce to diagnosis prediction in healthcare. In this paper, we present a novel dynamic framework for thinking about the deployment of ML models in a performative, human-ML collaborative system. In our framework, the introduction of ML recommendations changes the data generating process of human decisions, which are only a proxy to the ground truth and which are then used to train future versions of the model. We show that this dynamic process in principle can converge to different stable points, i.e. where the ML model and the Human+ML system have the same performance. Some of these stable points are suboptimal with respect to the actual ground truth. We conduct an empirical user study with 1,408 participants to showcase this process. In the study, humans solve instances of the knapsack problem with the help of machine learning predictions. This is an ideal setting because we can see how ML models learn to imitate human decisions and how this learning process converges to a stable point. We find that for many levels of ML performance, humans can improve the ML predictions to dynamically reach an equilibrium performance that is around 92% of the maximum knapsack value. We also find that the equilibrium performance could be even higher if humans rationally followed the ML recommendations. Finally, we test whether monetary incentives can increase the quality of human decisions, but we fail to find any positive effect. Our results have practical implications for the deployment of ML models in contexts where human decisions may deviate from the indisputable ground truth.
Do personality tests generalize to Large Language Models?
Nov 09, 2023With large language models (LLMs) appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate various properties of these models using tests originally designed for humans. While re-using existing tests is a resource-efficient way to evaluate LLMs, careful adjustments are usually required to ensure that test results are even valid across human sub-populations. Thus, it is not clear to what extent different tests' validity generalizes to LLMs. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from typical human responses, implying that these results cannot be interpreted in the same way as human test results. Concretely, reverse-coded items (e.g. "I am introverted" vs "I am extraverted") are often both answered affirmatively by LLMs. In addition, variation across different prompts designed to "steer" LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe it is important to pay more attention to tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' "personality".
A Note on the Significance Adjustment for FA*IR with Two Protected Groups
Dec 23, 2020
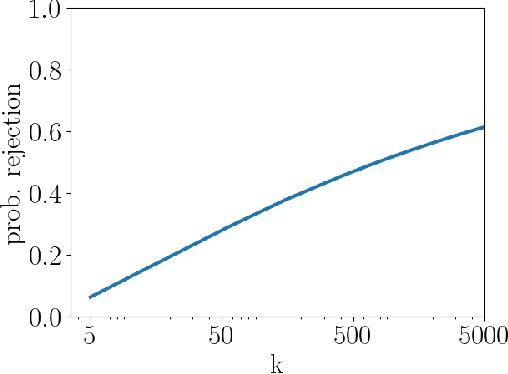
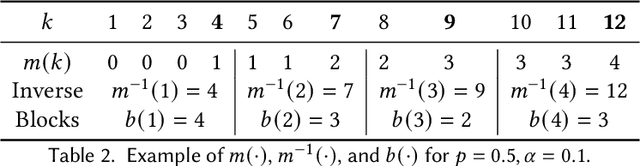

In this report we provide an improvement of the significance adjustment from the FA*IR algorithm of Zehlike et al., which did not work for very short rankings in combination with a low minimum proportion $p$ for the protected group. We show how the minimum number of protected candidates per ranking position can be calculated exactly and provide a mapping from the continuous space of significance levels ($\alpha$) to a discrete space of tables, which allows us to find $\alpha_c$ using a binary search heuristic.
Does Fair Ranking Improve Minority Outcomes? Understanding the Interplay of Human and Algorithmic Biases in Online Hiring
Dec 01, 2020
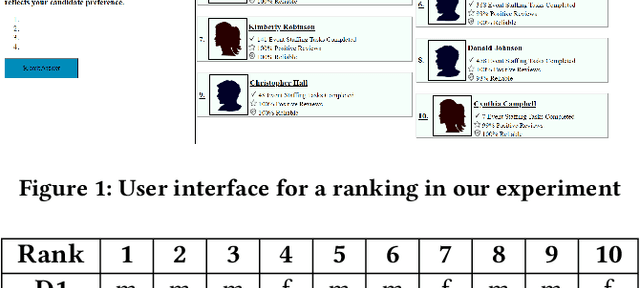
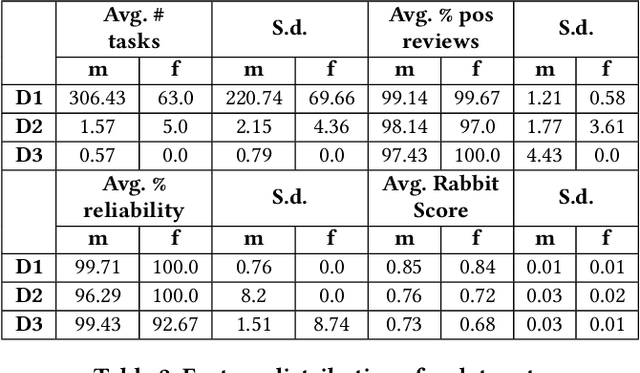
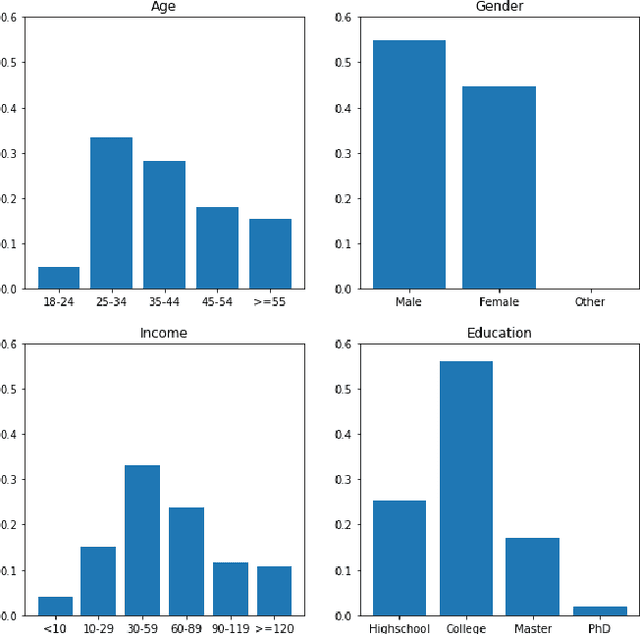
Ranking algorithms are being widely employed in various online hiring platforms including LinkedIn, TaskRabbit, and Fiverr. Since these platforms impact the livelihood of millions of people, it is important to ensure that the underlying algorithms are not adversely affecting minority groups. However, prior research has demonstrated that ranking algorithms employed by these platforms are prone to a variety of undesirable biases. To address this problem, fair ranking algorithms (e.g.,Det-Greedy) which increase exposure of underrepresented candidates have been proposed in recent literature. However, there is little to no work that explores if these proposed fair ranking algorithms actually improve real world outcomes (e.g., hiring decisions) for minority groups. Furthermore, there is no clear understanding as to how other factors (e.g., jobcontext, inherent biases of the employers) play a role in impacting the real world outcomes of minority groups. In this work, we study how gender biases manifest in online hiring platforms and how they impact real world hiring decisions. More specifically, we analyze various sources of gender biases including the nature of the ranking algorithm, the job context, and inherent biases of employers, and establish how these factors interact and affect real world hiring decisions. To this end, we experiment with three different ranking algorithms on three different job contexts using real world data from TaskRabbit. We simulate the hiring scenarios on TaskRabbit by carrying out a large-scale user study with Amazon Mechanical Turk. We then leverage the responses from this study to understand the effect of each of the aforementioned factors. Our results demonstrate that fair ranking algorithms can be an effective tool at increasing hiring of underrepresented gender candidates but induces inconsistent outcomes across candidate features and job contexts.