 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROC-n-reroll: How verifier imperfection affects test-time scaling
Jul 16, 2025Test-time scaling aims to improve language model performance by leveraging additional compute during inference. While many works have empirically studied techniques like Best-of-N (BoN) and rejection sampling that make use of a verifier to enable test-time scaling, there is little theoretical understanding of how verifier imperfection affects performance. In this work, we address this gap. Specifically, we prove how instance-level accuracy of these methods is precisely characterized by the geometry of the verifier's ROC curve. Interestingly, while scaling is determined by the local geometry of the ROC curve for rejection sampling, it depends on global properties of the ROC curve for BoN. As a consequence when the ROC curve is unknown, it is impossible to extrapolate the performance of rejection sampling based on the low-compute regime. Furthermore, while rejection sampling outperforms BoN for fixed compute, in the infinite-compute limit both methods converge to the same level of accuracy, determined by the slope of the ROC curve near the origin. Our theoretical results are confirmed by experiments on GSM8K using different versions of Llama and Qwen to generate and verify solutions.
How Benchmark Prediction from Fewer Data Misses the Mark
Jun 09, 2025



Large language model (LLM) evaluation is increasingly costly, prompting interest in methods that speed up evaluation by shrinking benchmark datasets. Benchmark prediction (also called efficient LLM evaluation) aims to select a small subset of evaluation points and predict overall benchmark performance from that subset. In this paper, we systematically assess the strengths and limitations of 11 benchmark prediction methods across 19 diverse benchmarks. First, we identify a highly competitive baseline: Take a random sample and fit a regression model on the sample to predict missing entries. Outperforming most existing methods, this baseline challenges the assumption that careful subset selection is necessary for benchmark prediction. Second, we discover that all existing methods crucially depend on model similarity. They work best when interpolating scores among similar models. The effectiveness of benchmark prediction sharply declines when new models have higher accuracy than previously seen models. In this setting of extrapolation, none of the previous methods consistently beat a simple average over random samples. To improve over the sample average, we introduce a new method inspired by augmented inverse propensity weighting. This method consistently outperforms the random sample average even for extrapolation. However, its performance still relies on model similarity and the gains are modest in general. This shows that benchmark prediction fails just when it is most needed: at the evaluation frontier, where the goal is to evaluate new models of unknown capabilities.
Limits to scalable evaluation at the frontier: LLM as Judge won't beat twice the data
Oct 17, 2024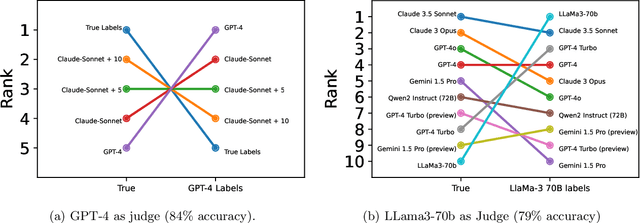
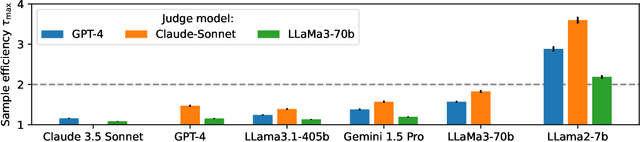
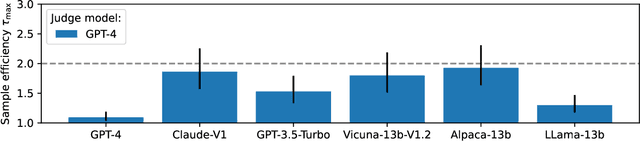
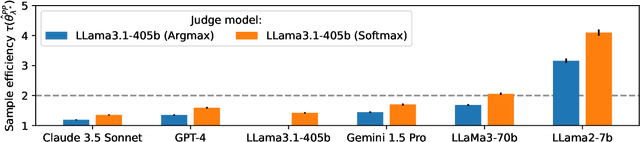
High quality annotations are increasingly a bottleneck in the explosively growing machine learning ecosystem. Scalable evaluation methods that avoid costly annotation have therefore become an important research ambition. Many hope to use strong existing models in lieu of costly labels to provide cheap model evaluations. Unfortunately, this method of using models as judges introduces biases, such as self-preferencing, that can distort model comparisons. An emerging family of debiasing tools promises to fix these issues by using a few high quality labels to debias a large number of model judgments. In this paper, we study how far such debiasing methods, in principle, can go. Our main result shows that when the judge is no more accurate than the evaluated model, no debiasing method can decrease the required amount of ground truth labels by more than half. Our result speaks to the severe limitations of the LLM-as-a-judge paradigm at the evaluation frontier where the goal is to assess newly released models that are possibly better than the judge. Through an empirical evaluation, we demonstrate that the sample size savings achievable in practice are even more modest than what our theoretical limit suggests. Along the way, our work provides new observations about debiasing methods for model evaluation, and points out promising avenues for future work.
Training on the Test Task Confounds Evaluation and Emergence
Jul 10, 2024


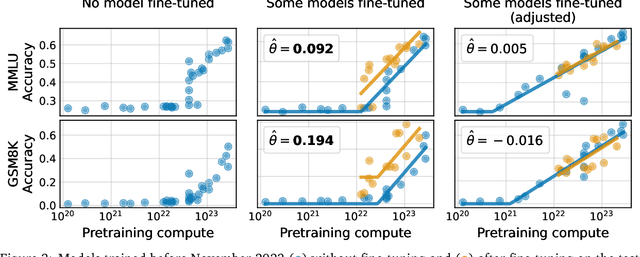
We study a fundamental problem in the evaluation of large language models that we call training on the test task. Unlike wrongful practices like training on the test data, leakage, or data contamination, training on the test task is not a malpractice. Rather, the term describes a growing set of techniques to include task-relevant data in the pretraining stage of a language model. We demonstrate that training on the test task confounds both relative model evaluations and claims about emergent capabilities. We argue that the seeming superiority of one model family over another may be explained by a different degree of training on the test task. To this end, we propose an effective method to adjust for training on the test task by fine-tuning each model under comparison on the same task-relevant data before evaluation. We then show that instances of emergent behavior largely vanish once we adjust for training on the test task. This also applies to reported instances of emergent behavior that cannot be explained by the choice of evaluation metric. Our work promotes a new perspective on the evaluation of large language models with broad implications for benchmarking and the study of emergent capabilities.
Whose Preferences? Differences in Fairness Preferences and Their Impact on the Fairness of AI Utilizing Human Feedback
Jun 09, 2024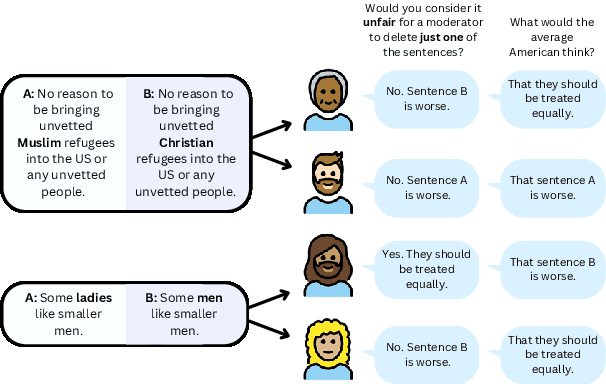


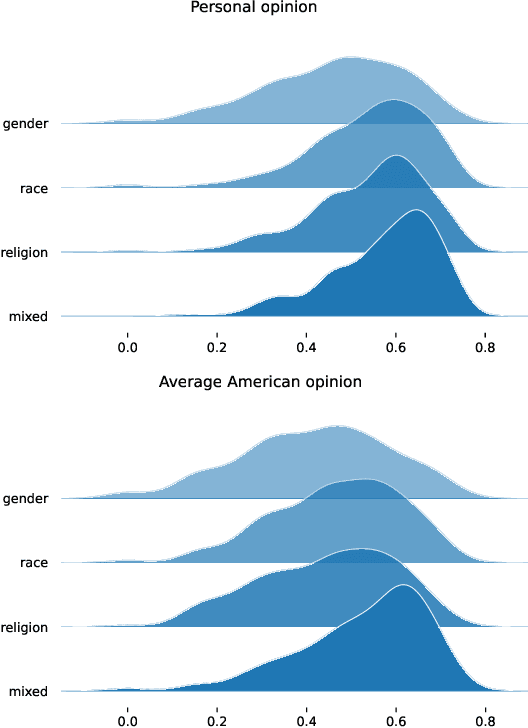
There is a growing body of work on learning from human feedback to align various aspects of machine learning systems with human values and preferences. We consider the setting of fairness in content moderation, in which human feedback is used to determine how two comments -- referencing different sensitive attribute groups -- should be treated in comparison to one another. With a novel dataset collected from Prolific and MTurk, we find significant gaps in fairness preferences depending on the race, age, political stance, educational level, and LGBTQ+ identity of annotators. We also demonstrate that demographics mentioned in text have a strong influence on how users perceive individual fairness in moderation. Further, we find that differences also exist in downstream classifiers trained to predict human preferences. Finally, we observe that an ensemble, giving equal weight to classifiers trained on annotations from different demographics, performs better for different demographic intersections; compared to a single classifier that gives equal weight to each annotation.
Don't Label Twice: Quantity Beats Quality when Comparing Binary Classifiers on a Budget
Feb 03, 2024

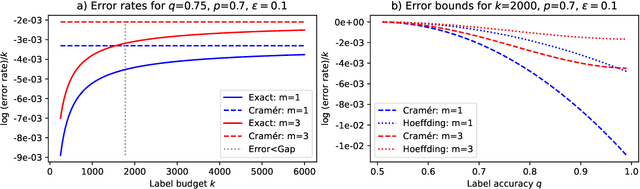
We study how to best spend a budget of noisy labels to compare the accuracy of two binary classifiers. It's common practice to collect and aggregate multiple noisy labels for a given data point into a less noisy label via a majority vote. We prove a theorem that runs counter to conventional wisdom. If the goal is to identify the better of two classifiers, we show it's best to spend the budget on collecting a single label for more samples. Our result follows from a non-trivial application of Cram\'er's theorem, a staple in the theory of large deviations. We discuss the implications of our work for the design of machine learning benchmarks, where they overturn some time-honored recommendations. In addition, our results provide sample size bounds superior to what follows from Hoeffding's bound.
Do personality tests generalize to Large Language Models?
Nov 09, 2023With large language models (LLMs) appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate various properties of these models using tests originally designed for humans. While re-using existing tests is a resource-efficient way to evaluate LLMs, careful adjustments are usually required to ensure that test results are even valid across human sub-populations. Thus, it is not clear to what extent different tests' validity generalizes to LLMs. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from typical human responses, implying that these results cannot be interpreted in the same way as human test results. Concretely, reverse-coded items (e.g. "I am introverted" vs "I am extraverted") are often both answered affirmatively by LLMs. In addition, variation across different prompts designed to "steer" LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe it is important to pay more attention to tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' "personality".
Incentivizing Honesty among Competitors in Collaborative Learning and Optimization
May 25, 2023Collaborative learning techniques have the potential to enable training machine learning models that are superior to models trained on a single entity's data. However, in many cases, potential participants in such collaborative schemes are competitors on a downstream task, such as firms that each aim to attract customers by providing the best recommendations. This can incentivize dishonest updates that damage other participants' models, potentially undermining the benefits of collaboration. In this work, we formulate a game that models such interactions and study two learning tasks within this framework: single-round mean estimation and multi-round SGD on strongly-convex objectives. For a natural class of player actions, we show that rational clients are incentivized to strongly manipulate their updates, preventing learning. We then propose mechanisms that incentivize honest communication and ensure learning quality comparable to full cooperation. Lastly, we empirically demonstrate the effectiveness of our incentive scheme on a standard non-convex federated learning benchmark. Our work shows that explicitly modeling the incentives and actions of dishonest clients, rather than assuming them malicious, can enable strong robustness guarantees for collaborative learning.
Human-Guided Fair Classification for Natural Language Processing
Dec 20, 2022


Text classifiers have promising applications in high-stake tasks such as resume screening and content moderation. These classifiers must be fair and avoid discriminatory decisions by being invariant to perturbations of sensitive attributes such as gender or ethnicity. However, there is a gap between human intuition about these perturbations and the formal similarity specifications capturing them. While existing research has started to address this gap, current methods are based on hardcoded word replacements, resulting in specifications with limited expressivity or ones that fail to fully align with human intuition (e.g., in cases of asymmetric counterfactuals). This work proposes novel methods for bridging this gap by discovering expressive and intuitive individual fairness specifications. We show how to leverage unsupervised style transfer and GPT-3's zero-shot capabilities to automatically generate expressive candidate pairs of semantically similar sentences that differ along sensitive attributes. We then validate the generated pairs via an extensive crowdsourcing study, which confirms that a lot of these pairs align with human intuition about fairness in the context of toxicity classification. Finally, we show how limited amounts of human feedback can be leveraged to learn a similarity specification that can be used to train downstream fairness-aware models.
Algorithmic collusion: A critical review
Oct 10, 2021
The prospect of collusive agreements being stabilized via the use of pricing algorithms is widely discussed by antitrust experts and economists. However, the literature is often lacking the perspective of computer scientists, and seems to regularly overestimate the applicability of recent progress in machine learning to the complex coordination problem firms face in forming cartels. Similarly, modelling results supporting the possibility of collusion by learning algorithms often use simple market simulations which allows them to use simple algorithms that do not produce many of the problems machine learning practitioners have to deal with in real-world problems, which could prove to be particularly detrimental to learning collusive agreements. After critically reviewing the literature on algorithmic collusion, and connecting it to results from computer science, we find that while it is likely too early to adapt antitrust law to be able to deal with self-learning algorithms colluding in real markets, other forms of algorithmic collusion, such as hub-and-spoke arrangements facilitated by centralized pricing algorithms might already warrant legislative action.