 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Preferences for Brands and Cultures in LLMs
Mar 18, 2026Large language models (LLMs) based AI systems increasingly mediate what billions of people see, choose and buy. This creates an urgent need to quantify the systemic risks of LLM-driven market intermediation, including its implications for market fairness, competition, and the diversity of information exposure. This paper introduces ChoiceEval, a reproducible framework for auditing preferences for brands and cultures in large language models (LLMs) under realistic usage conditions. ChoiceEval addresses two core technical challenges: (i) generating realistic, persona-diverse evaluation queries and (ii) converting free-form outputs into comparable choice sets and quantitative preference metrics. For a given topic (e.g. running shoes, hotel chains, travel destinations), the framework segments users into psychographic profiles (e.g., budget-conscious, wellness-focused, convenience), and then derives diverse prompts that reflect real-world advice-seeking and decision-making behaviour. LLM responses are converted into normalised top-k choice sets. Preference and geographic bias are then quantified using comparable metrics across topics and personas. Thus, ChoiceEval provides a scalable audit pipeline for researchers, platforms, and regulators, linking model behaviour to real-world economic outcomes. Applied to Gemini, GPT, and DeepSeek across 10 topics spanning commerce and culture and more than 2,000 questions, ChoiceEval reveals consistent preferences: U.S.-developed models Gemini and GPT show marked favouritism toward American entities, while China-developed DeepSeek exhibits more balanced yet still detectable geographic preferences. These patterns persist across user personas, suggesting systematic rather than incidental effects.
Causal Pre-training Under the Fairness Lens: An Empirical Study of TabPFN
Jan 27, 2026Foundation models for tabular data, such as the Tabular Prior-data Fitted Network (TabPFN), are pre-trained on a massive number of synthetic datasets generated by structural causal models (SCM). They leverage in-context learning to offer high predictive accuracy in real-world tasks. However, the fairness properties of these foundational models, which incorporate ideas from causal reasoning during pre-training, remain underexplored. In this work, we conduct a comprehensive empirical evaluation of TabPFN and its fine-tuned variants, assessing predictive performance, fairness, and robustness across varying dataset sizes and distributional shifts. Our results reveal that while TabPFN achieves stronger predictive accuracy compared to baselines and exhibits robustness to spurious correlations, improvements in fairness are moderate and inconsistent, particularly under missing-not-at-random (MNAR) covariate shifts. These findings suggest that the causal pre-training in TabPFN is helpful but insufficient for algorithmic fairness, highlighting implications for deploying TabPFN (and similar) models in practice and the need for further fairness interventions.
A Post-Processing-Based Fair Federated Learning Framework
Jan 25, 2025Federated Learning (FL) allows collaborative model training among distributed parties without pooling local datasets at a central server. However, the distributed nature of FL poses challenges in training fair federated learning models. The existing techniques are often limited in offering fairness flexibility to clients and performance. We formally define and empirically analyze a simple and intuitive post-processing-based framework to improve group fairness in FL systems. This framework can be divided into two stages: a standard FL training stage followed by a completely decentralized local debiasing stage. In the first stage, a global model is trained without fairness constraints using a standard federated learning algorithm (e.g. FedAvg). In the second stage, each client applies fairness post-processing on the global model using their respective local dataset. This allows for customized fairness improvements based on clients' desired and context-guided fairness requirements. We demonstrate two well-established post-processing techniques in this framework: model output post-processing and final layer fine-tuning. We evaluate the framework against three common baselines on four different datasets, including tabular, signal, and image data, each with varying levels of data heterogeneity across clients. Our work shows that this framework not only simplifies fairness implementation in FL but also provides significant fairness improvements with minimal accuracy loss or even accuracy gain, across data modalities and machine learning methods, being especially effective in more heterogeneous settings.
Whose Preferences? Differences in Fairness Preferences and Their Impact on the Fairness of AI Utilizing Human Feedback
Jun 09, 2024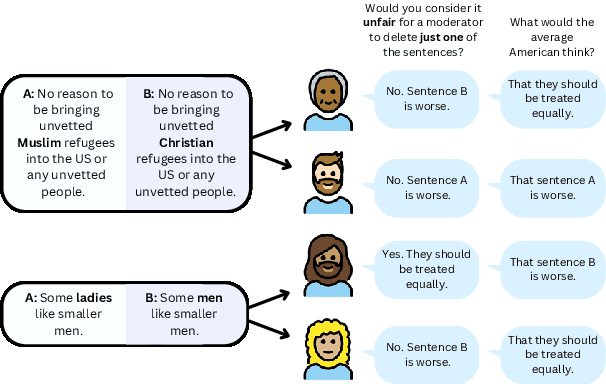


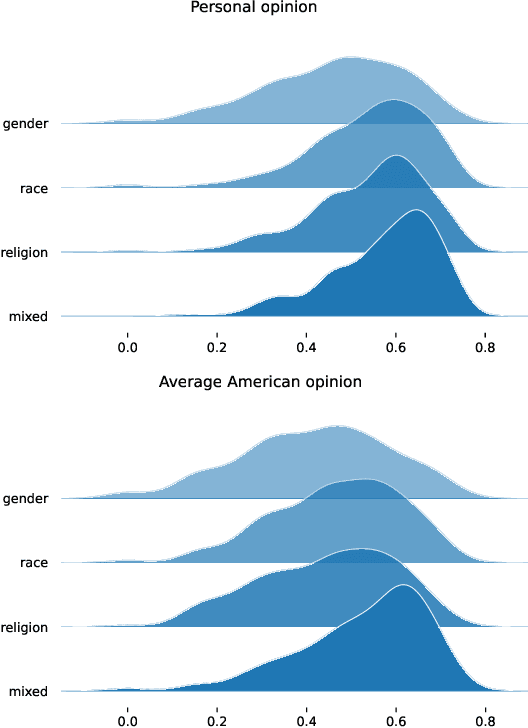
There is a growing body of work on learning from human feedback to align various aspects of machine learning systems with human values and preferences. We consider the setting of fairness in content moderation, in which human feedback is used to determine how two comments -- referencing different sensitive attribute groups -- should be treated in comparison to one another. With a novel dataset collected from Prolific and MTurk, we find significant gaps in fairness preferences depending on the race, age, political stance, educational level, and LGBTQ+ identity of annotators. We also demonstrate that demographics mentioned in text have a strong influence on how users perceive individual fairness in moderation. Further, we find that differences also exist in downstream classifiers trained to predict human preferences. Finally, we observe that an ensemble, giving equal weight to classifiers trained on annotations from different demographics, performs better for different demographic intersections; compared to a single classifier that gives equal weight to each annotation.
SocialGenPod: Privacy-Friendly Generative AI Social Web Applications with Decentralised Personal Data Stores
Mar 15, 2024We present SocialGenPod, a decentralised and privacy-friendly way of deploying generative AI Web applications. Unlike centralised Web and data architectures that keep user data tied to application and service providers, we show how one can use Solid -- a decentralised Web specification -- to decouple user data from generative AI applications. We demonstrate SocialGenPod using a prototype that allows users to converse with different Large Language Models, optionally leveraging Retrieval Augmented Generation to generate answers grounded in private documents stored in any Solid Pod that the user is allowed to access, directly or indirectly. SocialGenPod makes use of Solid access control mechanisms to give users full control of determining who has access to data stored in their Pods. SocialGenPod keeps all user data (chat history, app configuration, personal documents, etc) securely in the user's personal Pod; separate from specific model or application providers. Besides better privacy controls, this approach also enables portability across different services and applications. Finally, we discuss challenges, posed by the large compute requirements of state-of-the-art models, that future research in this area should address. Our prototype is open-source and available at: https://github.com/Vidminas/socialgenpod/.
FairTargetSim: An Interactive Simulator for Understanding and Explaining the Fairness Effects of Target Variable Definition
Mar 09, 2024



Machine learning requires defining one's target variable for predictions or decisions, a process that can have profound implications on fairness: biases are often encoded in target variable definition itself, before any data collection or training. We present an interactive simulator, FairTargetSim (FTS), that illustrates how target variable definition impacts fairness. FTS is a valuable tool for algorithm developers, researchers, and non-technical stakeholders. FTS uses a case study of algorithmic hiring, using real-world data and user-defined target variables. FTS is open-source and available at: http://tinyurl.com/ftsinterface. The video accompanying this paper is here: http://tinyurl.com/ijcaifts.
On The Truthfulness of 'Surprisingly Likely' Responses of Large Language Models
Nov 13, 2023The surprisingly likely criterion in the seminal work of Prelec (the Bayesian Truth Serum) guarantees truthfulness in a game-theoretic multi-agent setting, by rewarding rational agents to maximise the expected information gain with their answers w.r.t. their probabilistic beliefs. We investigate the relevance of a similar criterion for responses of LLMs. We hypothesize that if the surprisingly likely criterion works in LLMs, under certain conditions, the responses that maximize the reward under this criterion should be more accurate than the responses that only maximize the posterior probability. Using benchmarks including the TruthfulQA benchmark and using openly available LLMs: GPT-2 and LLaMA-2, we show that the method indeed improves the accuracy significantly (for example, upto 24 percentage points aggregate improvement on TruthfulQA and upto 70 percentage points improvement on individual categories of questions).
Decentralised, Scalable and Privacy-Preserving Synthetic Data Generation
Oct 30, 2023Synthetic data is emerging as a promising way to harness the value of data, while reducing privacy risks. The potential of synthetic data is not limited to privacy-friendly data release, but also includes complementing real data in use-cases such as training machine learning algorithms that are more fair and robust to distribution shifts etc. There is a lot of interest in algorithmic advances in synthetic data generation for providing better privacy and statistical guarantees and for its better utilisation in machine learning pipelines. However, for responsible and trustworthy synthetic data generation, it is not sufficient to focus only on these algorithmic aspects and instead, a holistic view of the synthetic data generation pipeline must be considered. We build a novel system that allows the contributors of real data to autonomously participate in differentially private synthetic data generation without relying on a trusted centre. Our modular, general and scalable solution is based on three building blocks namely: Solid (Social Linked Data), MPC (Secure Multi-Party Computation) and Trusted Execution Environments (TEEs). Solid is a specification that lets people store their data securely in decentralised data stores called Pods and control access to their data. MPC refers to the set of cryptographic methods for different parties to jointly compute a function over their inputs while keeping those inputs private. TEEs such as Intel SGX rely on hardware based features for confidentiality and integrity of code and data. We show how these three technologies can be effectively used to address various challenges in responsible and trustworthy synthetic data generation by ensuring: 1) contributor autonomy, 2) decentralisation, 3) privacy and 4) scalability. We support our claims with rigorous empirical results on simulated and real datasets and different synthetic data generation algorithms.
WCLD: Curated Large Dataset of Criminal Cases from Wisconsin Circuit Courts
Oct 28, 2023



Machine learning based decision-support tools in criminal justice systems are subjects of intense discussions and academic research. There are important open questions about the utility and fairness of such tools. Academic researchers often rely on a few small datasets that are not sufficient to empirically study various real-world aspects of these questions. In this paper, we contribute WCLD, a curated large dataset of 1.5 million criminal cases from circuit courts in the U.S. state of Wisconsin. We used reliable public data from 1970 to 2020 to curate attributes like prior criminal counts and recidivism outcomes. The dataset contains large number of samples from five racial groups, in addition to information like sex and age (at judgment and first offense). Other attributes in this dataset include neighborhood characteristics obtained from census data, detailed types of offense, charge severity, case decisions, sentence lengths, year of filing etc. We also provide pseudo-identifiers for judge, county and zipcode. The dataset will not only enable researchers to more rigorously study algorithmic fairness in the context of criminal justice, but also relate algorithmic challenges with various systemic issues. We also discuss in detail the process of constructing the dataset and provide a datasheet. The WCLD dataset is available at \url{https://clezdata.github.io/wcld/}.
Human-Guided Fair Classification for Natural Language Processing
Dec 20, 2022


Text classifiers have promising applications in high-stake tasks such as resume screening and content moderation. These classifiers must be fair and avoid discriminatory decisions by being invariant to perturbations of sensitive attributes such as gender or ethnicity. However, there is a gap between human intuition about these perturbations and the formal similarity specifications capturing them. While existing research has started to address this gap, current methods are based on hardcoded word replacements, resulting in specifications with limited expressivity or ones that fail to fully align with human intuition (e.g., in cases of asymmetric counterfactuals). This work proposes novel methods for bridging this gap by discovering expressive and intuitive individual fairness specifications. We show how to leverage unsupervised style transfer and GPT-3's zero-shot capabilities to automatically generate expressive candidate pairs of semantically similar sentences that differ along sensitive attributes. We then validate the generated pairs via an extensive crowdsourcing study, which confirms that a lot of these pairs align with human intuition about fairness in the context of toxicity classification. Finally, we show how limited amounts of human feedback can be leveraged to learn a similarity specification that can be used to train downstream fairness-aware models.