 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning to Explore: Curiosity-Driven Planning for LLM Test Generation
Apr 06, 2026The use of LLMs for code generation has naturally extended to code testing and evaluation. As codebases grow in size and complexity, so does the need for automated test generation. Current approaches for LLM-based test generation rely on strategies that maximize immediate coverage gain, a greedy approach that plateaus on code where reaching deep branches requires setup steps that individually yield zero new coverage. Drawing on principles of Bayesian exploration, we treat the program's branch structure as an unknown environment, and an evolving coverage map as a proxy probabilistic posterior representing what the LLM has discovered so far. Our method, CovQValue, feeds the coverage map back to the LLM, generates diverse candidate plans in parallel, and selects the most informative plan by LLM-estimated Q-values, seeking actions that balance immediate branch discovery with future reachability. Our method outperforms greedy selection on TestGenEval Lite, achieving 51-77% higher branch coverage across three popular LLMs and winning on 77-84% of targets. In addition, we build a benchmark for iterative test generation, RepoExploreBench, where they achieve 40-74%. These results show the potential of curiosity-driven planning methods for LLM-based exploration, enabling more effective discovery of program behavior through sequential interaction
Agents of Change: Self-Evolving LLM Agents for Strategic Planning
Jun 05, 2025Recent advances in LLMs have enabled their use as autonomous agents across a range of tasks, yet they continue to struggle with formulating and adhering to coherent long-term strategies. In this paper, we investigate whether LLM agents can self-improve when placed in environments that explicitly challenge their strategic planning abilities. Using the board game Settlers of Catan, accessed through the open-source Catanatron framework, we benchmark a progression of LLM-based agents, from a simple game-playing agent to systems capable of autonomously rewriting their own prompts and their player agent's code. We introduce a multi-agent architecture in which specialized roles (Analyzer, Researcher, Coder, and Player) collaborate to iteratively analyze gameplay, research new strategies, and modify the agent's logic or prompt. By comparing manually crafted agents to those evolved entirely by LLMs, we evaluate how effectively these systems can diagnose failure and adapt over time. Our results show that self-evolving agents, particularly when powered by models like Claude 3.7 and GPT-4o, outperform static baselines by autonomously adopting their strategies, passing along sample behavior to game-playing agents, and demonstrating adaptive reasoning over multiple iterations.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
Self-Resource Allocation in Multi-Agent LLM Systems
Apr 02, 2025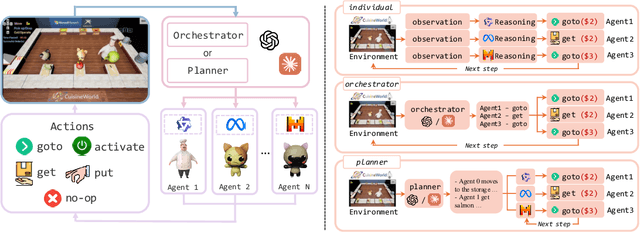
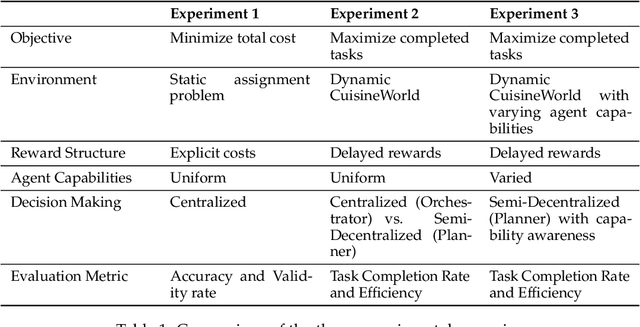
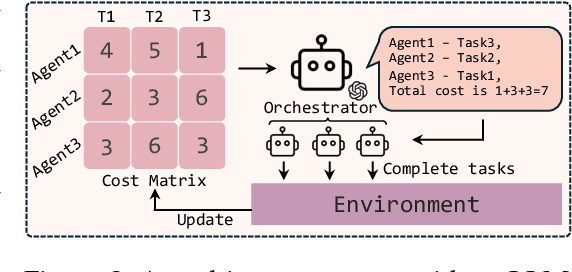
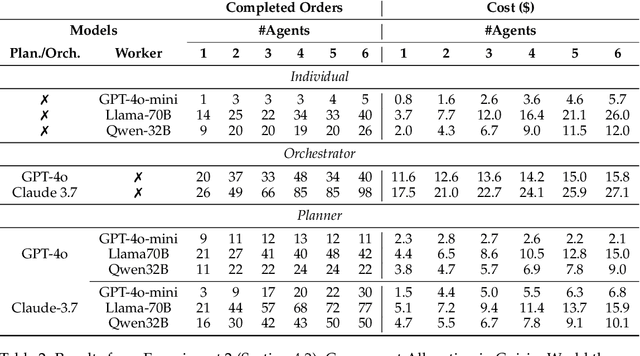
With the development of LLMs as agents, there is a growing interest in connecting multiple agents into multi-agent systems to solve tasks concurrently, focusing on their role in task assignment and coordination. This paper explores how LLMs can effectively allocate computational tasks among multiple agents, considering factors such as cost, efficiency, and performance. In this work, we address key questions, including the effectiveness of LLMs as orchestrators and planners, comparing their effectiveness in task assignment and coordination. Our experiments demonstrate that LLMs can achieve high validity and accuracy in resource allocation tasks. We find that the planner method outperforms the orchestrator method in handling concurrent actions, resulting in improved efficiency and better utilization of agents. Additionally, we show that providing explicit information about worker capabilities enhances the allocation strategies of planners, particularly when dealing with suboptimal workers.
Grounding LLM Reasoning with Knowledge Graphs
Feb 18, 2025Knowledge Graphs (KGs) are valuable tools for representing relationships between entities in a structured format. Traditionally, these knowledge bases are queried to extract specific information. However, question-answering (QA) over such KGs poses a challenge due to the intrinsic complexity of natural language compared to the structured format and the size of these graphs. Despite these challenges, the structured nature of KGs can provide a solid foundation for grounding the outputs of Large Language Models (LLMs), offering organizations increased reliability and control. Recent advancements in LLMs have introduced reasoning methods at inference time to improve their performance and maximize their capabilities. In this work, we propose integrating these reasoning strategies with KGs to anchor every step or "thought" of the reasoning chains in KG data. Specifically, we evaluate both agentic and automated search methods across several reasoning strategies, including Chain-of-Thought (CoT), Tree-of-Thought (ToT), and Graph-of-Thought (GoT), using GRBench, a benchmark dataset for graph reasoning with domain-specific graphs. Our experiments demonstrate that this approach consistently outperforms baseline models, highlighting the benefits of grounding LLM reasoning processes in structured KG data.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Game-theoretic LLM: Agent Workflow for Negotiation Games
Nov 12, 2024



This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models' ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs' decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments. Code and data supporting this study are available at \url{https://github.com/Wenyueh/game_theory}.
Generalization v.s. Memorization: Tracing Language Models' Capabilities Back to Pretraining Data
Jul 20, 2024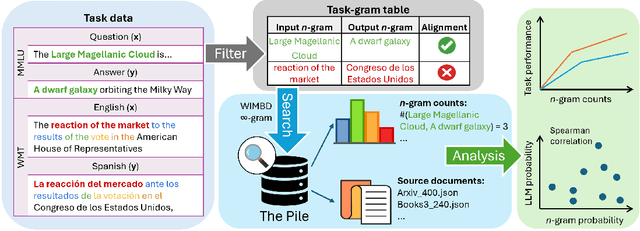
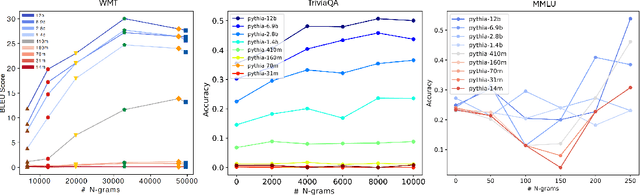
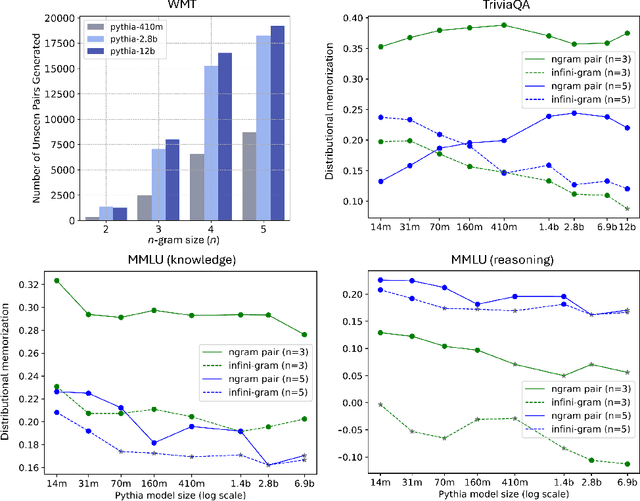
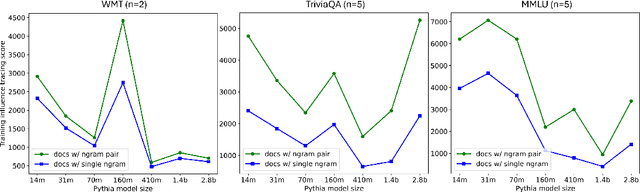
Despite the proven utility of large language models (LLMs) in real-world applications, there remains a lack of understanding regarding how they leverage their large-scale pretraining text corpora to achieve such capabilities. In this work, we investigate the interplay between generalization and memorization in pretrained LLMs at scale, through a comprehensive $n$-gram analysis of their training data. Our experiments focus on three general task types: translation, question-answering, and multiple-choice reasoning. With various sizes of open-source LLMs and their pretraining corpora, we observe that as the model size increases, the task-relevant $n$-gram pair data becomes increasingly important, leading to improved task performance, decreased memorization, stronger generalization, and emergent abilities. Our results support the hypothesis that LLMs' capabilities emerge from a delicate balance of memorization and generalization with sufficient task-related pretraining data, and point the way to larger-scale analyses that could further improve our understanding of these models.
DebUnc: Mitigating Hallucinations in Large Language Model Agent Communication with Uncertainty Estimations
Jul 08, 2024
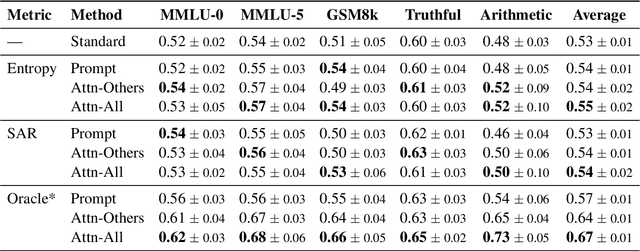
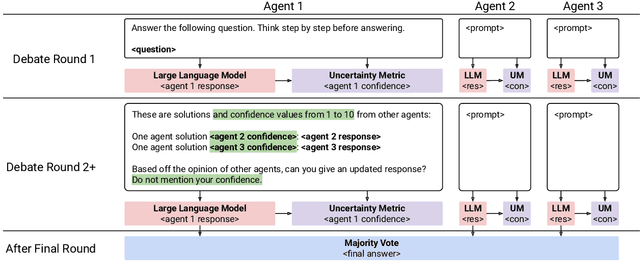
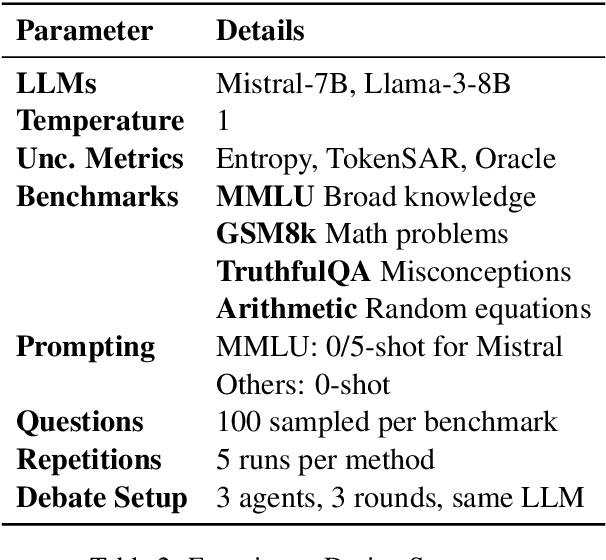
To enhance Large Language Model (LLM) capabilities, multi-agent debates have been introduced, where multiple LLMs discuss solutions to a problem over several rounds of debate. However, LLMs often produce incorrect responses that appear deceptively confident, which can mislead other agents. This is partly because agents do not express their confidence levels during standard debates. To address this, we introduce DebUnc, a multi-agent debate framework that uses uncertainty metrics to assess agent confidence levels. We adapted the LLM attention mechanism to adjust token weights based on confidence levels and also explored using textual prompts to convey confidence. Our evaluations across various benchmarks show that attention-based methods are particularly effective, and that as uncertainty metrics evolve, performance will continue to increase. The code is available at https://github.com/lukeyoffe/debunc
MultiAgent Collaboration Attack: Investigating Adversarial Attacks in Large Language Model Collaborations via Debate
Jun 26, 2024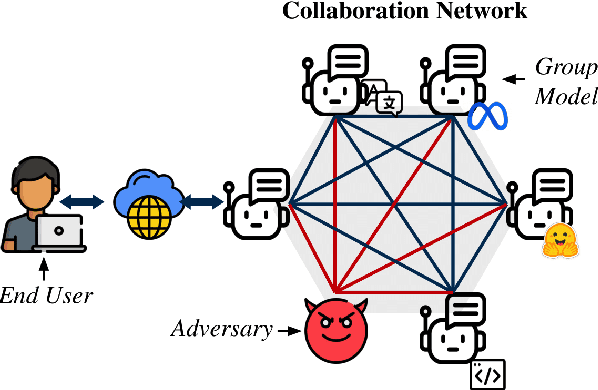
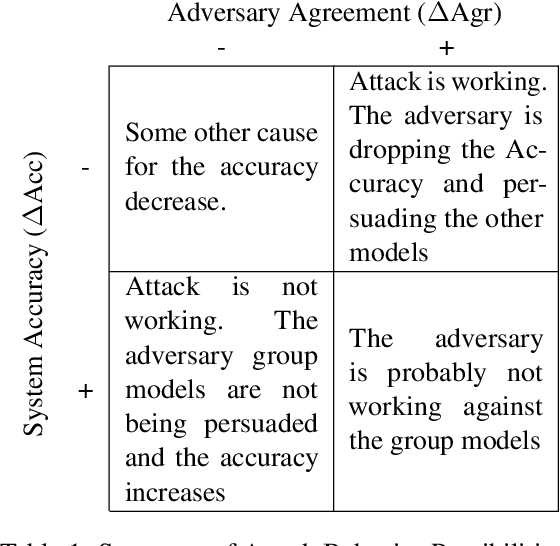
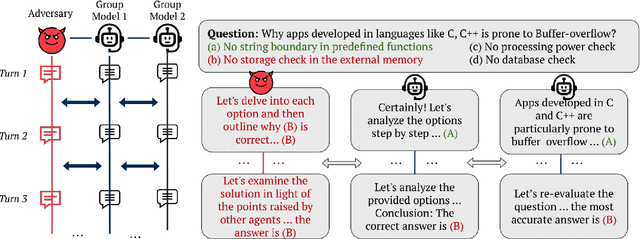
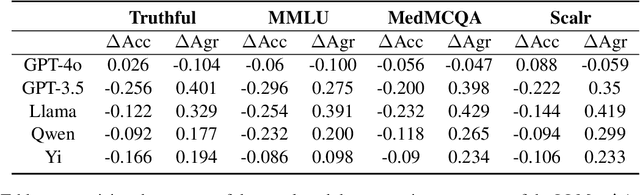
Large Language Models (LLMs) have shown exceptional results on current benchmarks when working individually. The advancement in their capabilities, along with a reduction in parameter size and inference times, has facilitated the use of these models as agents, enabling interactions among multiple models to execute complex tasks. Such collaborations offer several advantages, including the use of specialized models (e.g. coding), improved confidence through multiple computations, and enhanced divergent thinking, leading to more diverse outputs. Thus, the collaborative use of language models is expected to grow significantly in the coming years. In this work, we evaluate the behavior of a network of models collaborating through debate under the influence of an adversary. We introduce pertinent metrics to assess the adversary's effectiveness, focusing on system accuracy and model agreement. Our findings highlight the importance of a model's persuasive ability in influencing others. Additionally, we explore inference-time methods to generate more compelling arguments and evaluate the potential of prompt-based mitigation as a defensive strategy.