 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebUnc: Mitigating Hallucinations in Large Language Model Agent Communication with Uncertainty Estimations
Jul 08, 2024
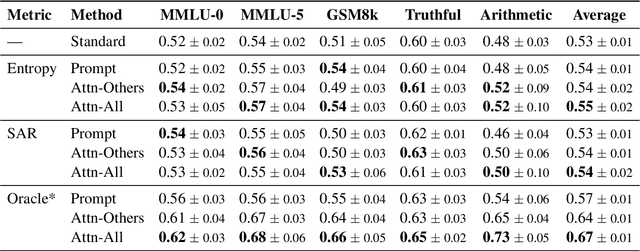
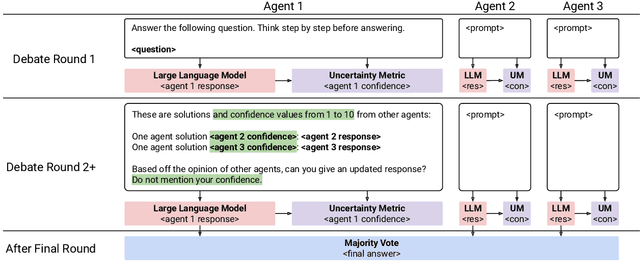
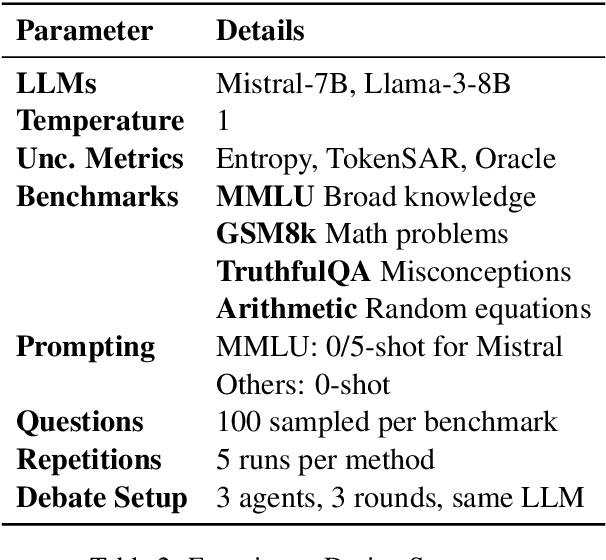
To enhance Large Language Model (LLM) capabilities, multi-agent debates have been introduced, where multiple LLMs discuss solutions to a problem over several rounds of debate. However, LLMs often produce incorrect responses that appear deceptively confident, which can mislead other agents. This is partly because agents do not express their confidence levels during standard debates. To address this, we introduce DebUnc, a multi-agent debate framework that uses uncertainty metrics to assess agent confidence levels. We adapted the LLM attention mechanism to adjust token weights based on confidence levels and also explored using textual prompts to convey confidence. Our evaluations across various benchmarks show that attention-based methods are particularly effective, and that as uncertainty metrics evolve, performance will continue to increase. The code is available at https://github.com/lukeyoffe/debunc
OCTO+: A Suite for Automatic Open-Vocabulary Object Placement in Mixed Reality
Jan 17, 2024



One key challenge in Augmented Reality is the placement of virtual content in natural locations. Most existing automated techniques can only work with a closed-vocabulary, fixed set of objects. In this paper, we introduce and evaluate several methods for automatic object placement using recent advances in open-vocabulary vision-language models. Through a multifaceted evaluation, we identify a new state-of-the-art method, OCTO+. We also introduce a benchmark for automatically evaluating the placement of virtual objects in augmented reality, alleviating the need for costly user studies. Through this, in addition to human evaluations, we find that OCTO+ places objects in a valid region over 70% of the time, outperforming other methods on a range of metrics.
OCTOPUS: Open-vocabulary Content Tracking and Object Placement Using Semantic Understanding in Mixed Reality
Dec 20, 2023

One key challenge in augmented reality is the placement of virtual content in natural locations. Existing automated techniques are only able to work with a closed-vocabulary, fixed set of objects. In this paper, we introduce a new open-vocabulary method for object placement. Our eight-stage pipeline leverages recent advances in segmentation models, vision-language models, and LLMs to place any virtual object in any AR camera frame or scene. In a preliminary user study, we show that our method performs at least as well as human experts 57% of the time.
FETA: A Benchmark for Few-Sample Task Transfer in Open-Domain Dialogue
May 12, 2022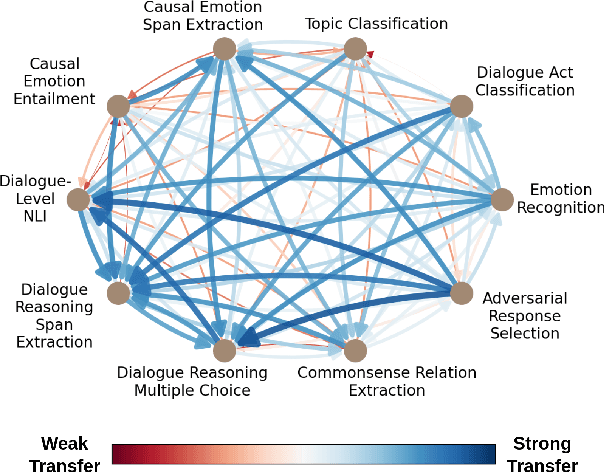
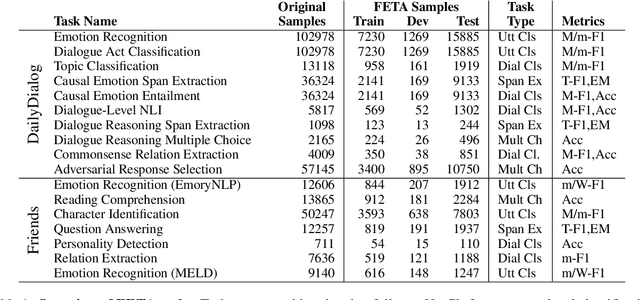
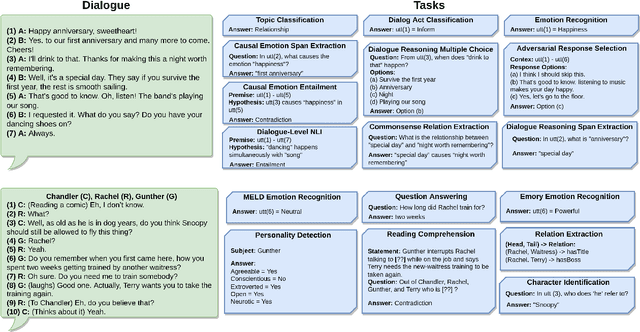
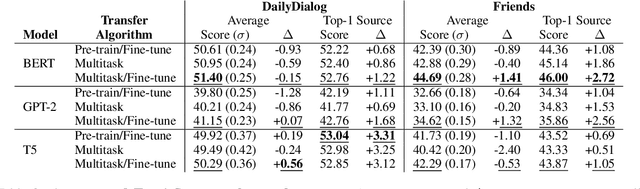
Task transfer, transferring knowledge contained in related tasks, holds the promise of reducing the quantity of labeled data required to fine-tune language models. Dialogue understanding encompasses many diverse tasks, yet task transfer has not been thoroughly studied in conversational AI. This work explores conversational task transfer by introducing FETA: a benchmark for few-sample task transfer in open-domain dialogue. FETA contains two underlying sets of conversations upon which there are 10 and 7 tasks annotated, enabling the study of intra-dataset task transfer; task transfer without domain adaptation. We utilize three popular language models and three learning algorithms to analyze the transferability between 132 source-target task pairs and create a baseline for future work. We run experiments in the single- and multi-source settings and report valuable findings, e.g., most performance trends are model-specific, and span extraction and multiple-choice tasks benefit the most from task transfer. In addition to task transfer, FETA can be a valuable resource for future research into the efficiency and generalizability of pre-training datasets and model architectures, as well as for learning settings such as continual and multitask learning.