 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Multilingual Data Mixtures in Language Model Pretraining
Oct 29, 2025The impact of different multilingual data mixtures in pretraining large language models (LLMs) has been a topic of ongoing debate, often raising concerns about potential trade-offs between language coverage and model performance (i.e., the curse of multilinguality). In this work, we investigate these assumptions by training 1.1B and 3B parameter LLMs on diverse multilingual corpora, varying the number of languages from 25 to 400. Our study challenges common beliefs surrounding multilingual training. First, we find that combining English and multilingual data does not necessarily degrade the in-language performance of either group, provided that languages have a sufficient number of tokens included in the pretraining corpus. Second, we observe that using English as a pivot language (i.e., a high-resource language that serves as a catalyst for multilingual generalization) yields benefits across language families, and contrary to expectations, selecting a pivot language from within a specific family does not consistently improve performance for languages within that family. Lastly, we do not observe a significant "curse of multilinguality" as the number of training languages increases in models at this scale. Our findings suggest that multilingual data, when balanced appropriately, can enhance language model capabilities without compromising performance, even in low-resource settings
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization
Aug 06, 2025



Tokenization is the first -- and often least scrutinized -- step of most NLP pipelines. Standard algorithms for learning tokenizers rely on frequency-based objectives, which favor languages dominant in the training data and consequently leave lower-resource languages with tokenizations that are disproportionately longer, morphologically implausible, or even riddled with <UNK> placeholders. This phenomenon ultimately amplifies computational and financial inequalities between users from different language backgrounds. To remedy this, we introduce Parity-aware Byte Pair Encoding (BPE), a variant of the widely-used BPE algorithm. At every merge step, Parity-aware BPE maximizes the compression gain of the currently worst-compressed language, trading a small amount of global compression for cross-lingual parity. We find empirically that Parity-aware BPE leads to more equitable token counts across languages, with negligible impact on global compression rate and no substantial effect on language-model performance in downstream tasks.
FineWeb2: One Pipeline to Scale Them All -- Adapting Pre-Training Data Processing to Every Language
Jun 26, 2025Pre-training state-of-the-art large language models (LLMs) requires vast amounts of clean and diverse text data. While the open development of large high-quality English pre-training datasets has seen substantial recent progress, training performant multilingual LLMs remains a challenge, in large part due to the inherent difficulty of tailoring filtering and deduplication pipelines to a large number of languages. In this work, we introduce a new pre-training dataset curation pipeline based on FineWeb that can be automatically adapted to support any language. We extensively ablate our pipeline design choices on a set of nine diverse languages, guided by a set of meaningful and informative evaluation tasks that were chosen through a novel selection process based on measurable criteria. Ultimately, we show that our pipeline can be used to create non-English corpora that produce more performant models than prior datasets. We additionally introduce a straightforward and principled approach to rebalance datasets that takes into consideration both duplication count and quality, providing an additional performance uplift. Finally, we scale our pipeline to over 1000 languages using almost 100 Common Crawl snapshots to produce FineWeb2, a new 20 terabyte (5 billion document) multilingual dataset which we release along with our pipeline, training, and evaluation codebases.
ConLID: Supervised Contrastive Learning for Low-Resource Language Identification
Jun 18, 2025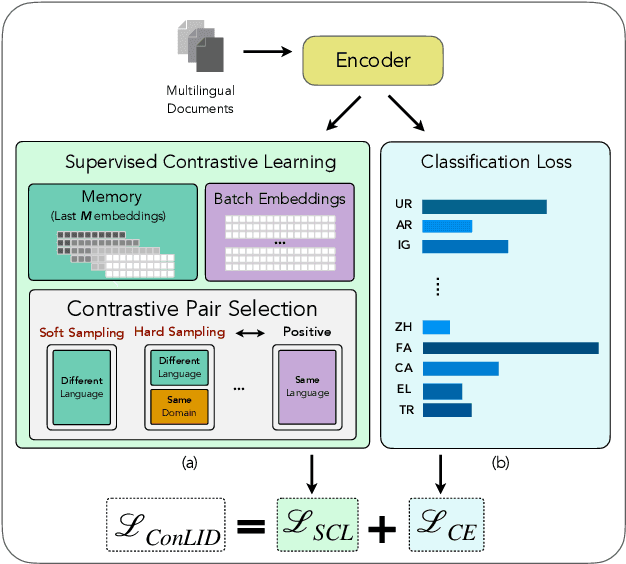
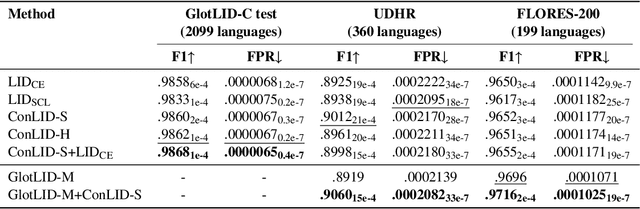

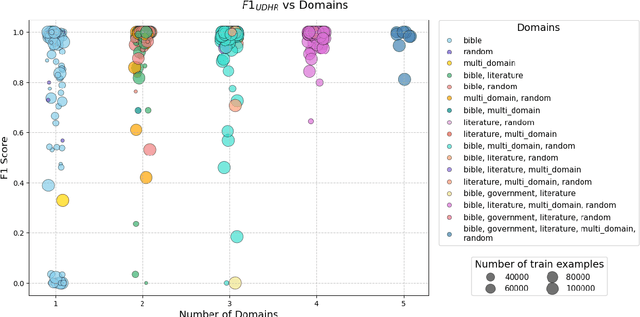
Language identification (LID) is a critical step in curating multilingual LLM pretraining corpora from web crawls. While many studies on LID model training focus on collecting diverse training data to improve performance, low-resource languages -- often limited to single-domain data, such as the Bible -- continue to perform poorly. To resolve these class imbalance and bias issues, we propose a novel supervised contrastive learning (SCL) approach to learn domain-invariant representations for low-resource languages. Through an extensive analysis, we show that our approach improves LID performance on out-of-domain data for low-resource languages by 3.2%, demonstrating its effectiveness in enhancing LID models.
WikiMixQA: A Multimodal Benchmark for Question Answering over Tables and Charts
Jun 18, 2025Documents are fundamental to preserving and disseminating information, often incorporating complex layouts, tables, and charts that pose significant challenges for automatic document understanding (DU). While vision-language large models (VLLMs) have demonstrated improvements across various tasks, their effectiveness in processing long-context vision inputs remains unclear. This paper introduces WikiMixQA, a benchmark comprising 1,000 multiple-choice questions (MCQs) designed to evaluate cross-modal reasoning over tables and charts extracted from 4,000 Wikipedia pages spanning seven distinct topics. Unlike existing benchmarks, WikiMixQA emphasizes complex reasoning by requiring models to synthesize information from multiple modalities. We evaluate 12 state-of-the-art vision-language models, revealing that while proprietary models achieve ~70% accuracy when provided with direct context, their performance deteriorates significantly when retrieval from long documents is required. Among these, GPT-4-o is the only model exceeding 50% accuracy in this setting, whereas open-source models perform considerably worse, with a maximum accuracy of 27%. These findings underscore the challenges of long-context, multi-modal reasoning and establish WikiMixQA as a crucial benchmark for advancing document understanding research.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
How Do Multilingual Models Remember? Investigating Multilingual Factual Recall Mechanisms
Oct 18, 2024Large Language Models (LLMs) store and retrieve vast amounts of factual knowledge acquired during pre-training. Prior research has localized and identified mechanisms behind knowledge recall; however, it has primarily focused on English monolingual models. The question of how these processes generalize to other languages and multilingual LLMs remains unexplored. In this paper, we address this gap by conducting a comprehensive analysis of two highly multilingual LLMs. We assess the extent to which previously identified components and mechanisms of factual recall in English apply to a multilingual context. Then, we examine when language plays a role in the recall process, uncovering evidence of language-independent and language-dependent mechanisms.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
Breaking the Language Barrier: Improving Cross-Lingual Reasoning with Structured Self-Attention
Oct 23, 2023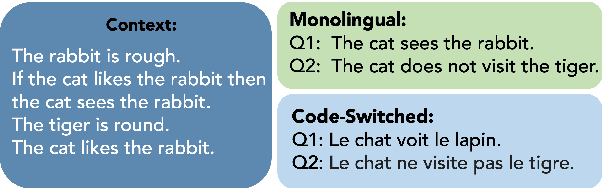
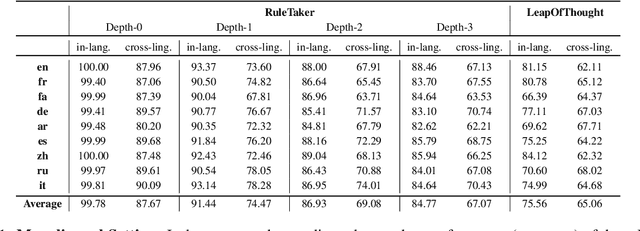
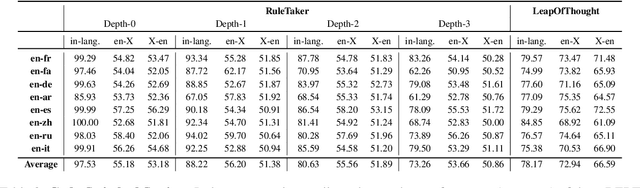

In this work, we study whether multilingual language models (MultiLMs) can transfer logical reasoning abilities to other languages when they are fine-tuned for reasoning in a different language. We evaluate the cross-lingual reasoning abilities of MultiLMs in two schemes: (1) where the language of the context and the question remain the same in the new languages that are tested (i.e., the reasoning is still monolingual, but the model must transfer the learned reasoning ability across languages), and (2) where the language of the context and the question is different (which we term code-switched reasoning). On two logical reasoning datasets, RuleTaker and LeapOfThought, we demonstrate that although MultiLMs can transfer reasoning ability across languages in a monolingual setting, they struggle to transfer reasoning abilities in a code-switched setting. Following this observation, we propose a novel attention mechanism that uses a dedicated set of parameters to encourage cross-lingual attention in code-switched sequences, which improves the reasoning performance by up to 14% and 4% on the RuleTaker and LeapOfThought datasets, respectively.