 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Language-neutral Sub-networks in Multilingual Language Models
May 25, 2022



Multilingual pre-trained language models perform remarkably well on cross-lingual transfer for downstream tasks. Despite their impressive performance, our understanding of their language neutrality (i.e., the extent to which they use shared representations to encode similar phenomena across languages) and its role in achieving such performance remain open questions. In this work, we conceptualize language neutrality of multilingual models as a function of the overlap between language-encoding sub-networks of these models. Using mBERT as a foundation, we employ the lottery ticket hypothesis to discover sub-networks that are individually optimized for various languages and tasks. Using three distinct tasks and eleven typologically-diverse languages in our evaluation, we show that the sub-networks found for different languages are in fact quite similar, supporting the idea that mBERT jointly encodes multiple languages in shared parameters. We conclude that mBERT is comprised of a language-neutral sub-network shared among many languages, along with multiple ancillary language-specific sub-networks, with the former playing a more prominent role in mBERT's impressive cross-lingual performance.
Aligning Multilingual Word Embeddings for Cross-Modal Retrieval Task
Oct 08, 2019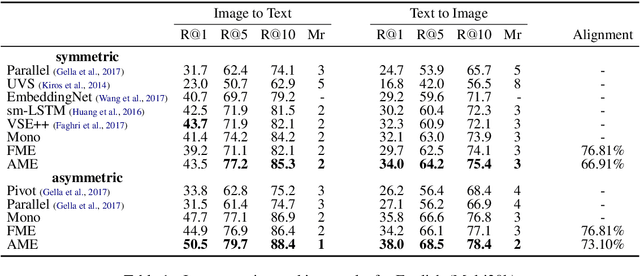
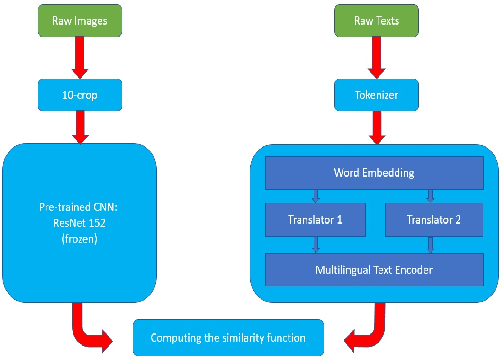
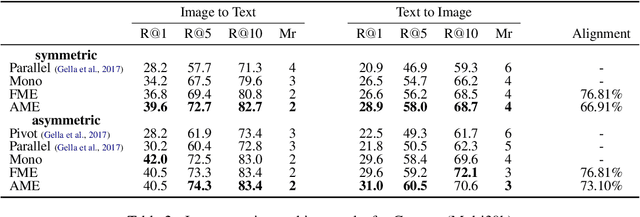
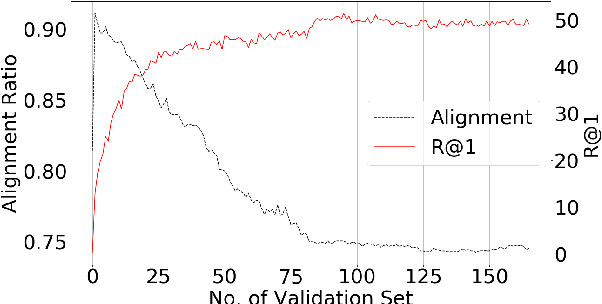
In this paper, we propose a new approach to learn multimodal multilingual embeddings for matching images and their relevant captions in two languages. We combine two existing objective functions to make images and captions close in a joint embedding space while adapting the alignment of word embeddings between existing languages in our model. We show that our approach enables better generalization, achieving state-of-the-art performance in text-to-image and image-to-text retrieval task, and caption-caption similarity task. Two multimodal multilingual datasets are used for evaluation: Multi30k with German and English captions and Microsoft-COCO with English and Japanese captions.
Multimodal Classification for Analysing Social Media
Aug 07, 2017
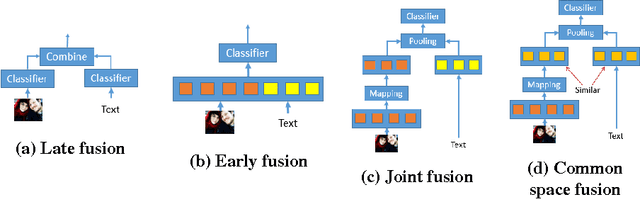
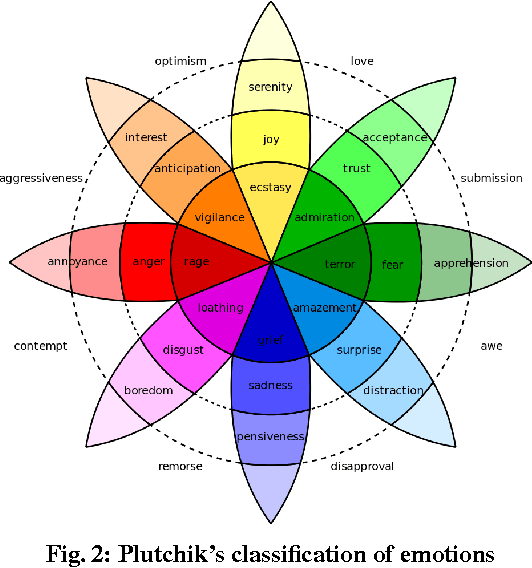
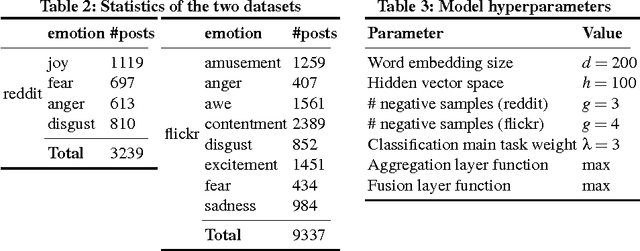
Classification of social media data is an important approach in understanding user behavior on the Web. Although information on social media can be of different modalities such as texts, images, audio or videos, traditional approaches in classification usually leverage only one prominent modality. Techniques that are able to leverage multiple modalities are often complex and susceptible to the absence of some modalities. In this paper, we present simple models that combine information from different modalities to classify social media content and are able to handle the above problems with existing techniques. Our models combine information from different modalities using a pooling layer and an auxiliary learning task is used to learn a common feature space. We demonstrate the performance of our models and their robustness to the missing of some modalities in the emotion classification domain. Our approaches, although being simple, can not only achieve significantly higher accuracies than traditional fusion approaches but also have comparable results when only one modality is available.
Neural Text Generation from Structured Data with Application to the Biography Domain
Sep 23, 2016



This paper introduces a neural model for concept-to-text generation that scales to large, rich domains. We experiment with a new dataset of biographies from Wikipedia that is an order of magnitude larger than existing resources with over 700k samples. The dataset is also vastly more diverse with a 400k vocabulary, compared to a few hundred words for Weathergov or Robocup. Our model builds upon recent work on conditional neural language model for text generation. To deal with the large vocabulary, we extend these models to mix a fixed vocabulary with copy actions that transfer sample-specific words from the input database to the generated output sentence. Our neural model significantly out-performs a classical Kneser-Ney language model adapted to this task by nearly 15 BLEU.
Simple Image Description Generator via a Linear Phrase-Based Approach
Apr 11, 2015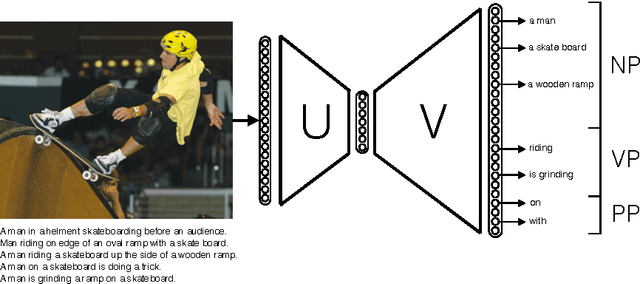
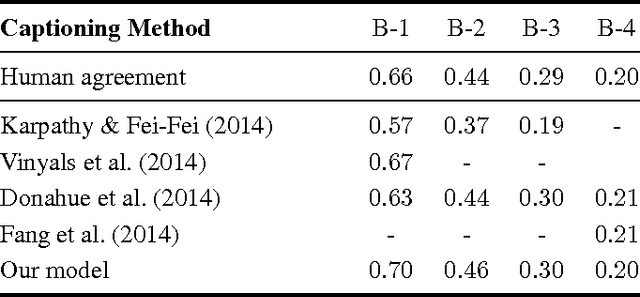
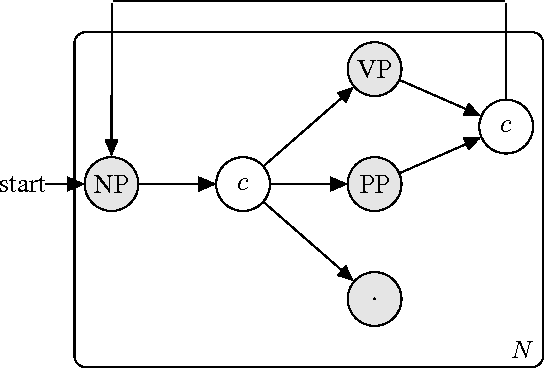
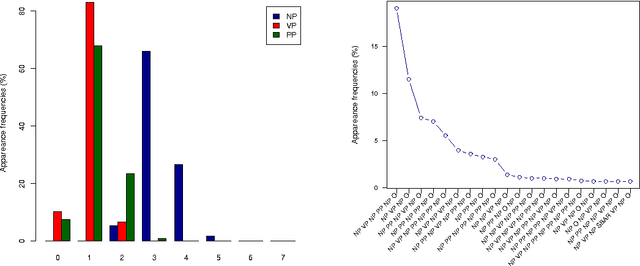
Generating a novel textual description of an image is an interesting problem that connects computer vision and natural language processing. In this paper, we present a simple model that is able to generate descriptive sentences given a sample image. This model has a strong focus on the syntax of the descriptions. We train a purely bilinear model that learns a metric between an image representation (generated from a previously trained Convolutional Neural Network) and phrases that are used to described them. The system is then able to infer phrases from a given image sample. Based on caption syntax statistics, we propose a simple language model that can produce relevant descriptions for a given test image using the phrases inferred. Our approach, which is considerably simpler than state-of-the-art models, achieves comparable results on the recently release Microsoft COCO dataset.