 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAPSO: A Knowledge-grounded framework for Autonomous Program Synthesis and Optimization
Jan 29, 2026We introduce KAPSO, a modular framework for autonomous program synthesis and optimization. Given a natural language goal and an evaluation method, KAPSO iteratively performs ideation, code synthesis and editing, execution, evaluation, and learning to improve a runnable artifact toward measurable objectives. Rather than treating synthesis as the endpoint, KAPSO uses synthesis as an operator within a long-horizon optimization loop, where progress is defined by evaluator outcomes. KAPSO targets long-horizon failures common in coding agents, including lost experimental state, brittle debugging, and weak reuse of domain expertise, by integrating three tightly coupled components. First, a git-native experimentation engine isolates each attempt as a branch, producing reproducible artifacts and preserving provenance across iterations. Second, a knowledge system ingests heterogeneous sources, including repositories, internal playbooks, and curated external resources such as documentation, scientific papers, and web search results, and organizes them into a structured representation that supports retrieval over workflows, implementations, and environment constraints. Third, a cognitive memory layer coordinates retrieval and maintains an episodic store of reusable lessons distilled from experiment traces (run logs, diffs, and evaluator feedback), reducing repeated error modes and accelerating convergence. We evaluated KAPSO on MLE-Bench (Kaggle-style ML competitions) and ALE-Bench (AtCoder heuristic optimization), and report end-to-end performance. Code Available at: https://github.com/Leeroo-AI/kapso
Leeroo Orchestrator: Elevating LLMs Performance Through Model Integration
Jan 25, 2024



In this paper, we propose an architecture to harness the collective knowledge of multiple trained LLMs to create a new state-of-the-art. At the core of this framework is a LLM-based orchestrator that is adept at picking the right underlying LLM experts for optimal task execution. Inspired by self-play in reinforcement learning, we created a loop of query generation, orchestration, and evaluation to generate training data for the orchestrator. Our evaluation focused on the MMLU benchmark, employing models with 7B, 13B, and 34B parameters available on Hugging Face. The results demonstrate new state-of-the-art open-source models: Our Leeroo orchestrator achieves performance on par with the Mixtral model while incurring only two-thirds of its cost. Moreover, increasing the allowed cost surpasses Mixtral's accuracy by over 5% at the same cost level, reaching an accuracy of 75.9%. Further enhancements were observed when integrating GPT4 into the underlying model pool. The Leeroo orchestrator nearly matches GPT4's performance at half the cost and even exceeds GPT4's results with a 25% cost reduction. These findings illustrate the potential of our architecture in creating state-of-the-art and cost-effective LLMs by optimizing the synergy between multiple LLMs to achieve superior performance outcomes.
Investigating Multi-Pivot Ensembling with Massively Multilingual Machine Translation Models
Nov 14, 2023
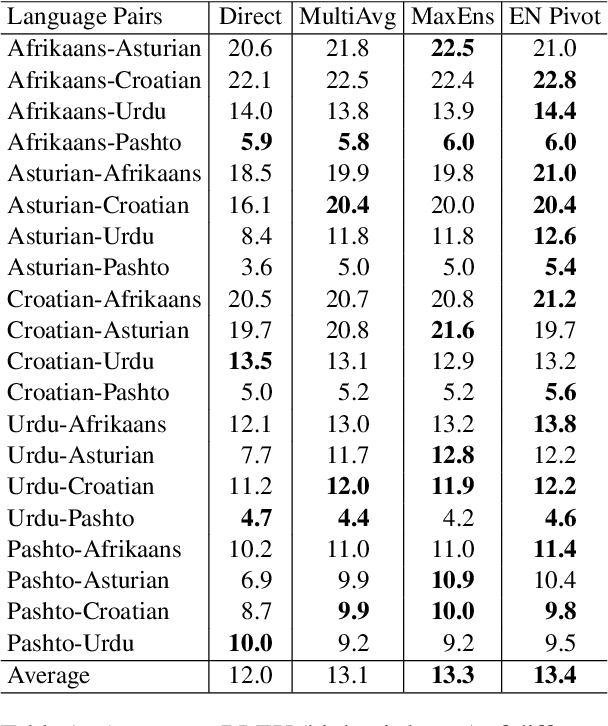


Massively multilingual machine translation models allow for the translation of a large number of languages with a single model, but have limited performance on low- and very-low-resource translation directions. Pivoting via high-resource languages remains a strong strategy for low-resource directions, and in this paper we revisit ways of pivoting through multiple languages. Previous work has used a simple averaging of probability distributions from multiple paths, but we find that this performs worse than using a single pivot, and exacerbates the hallucination problem because the same hallucinations can be probable across different paths. As an alternative, we propose MaxEns, a combination strategy that is biased towards the most confident predictions, hypothesising that confident predictions are less prone to be hallucinations. We evaluate different strategies on the FLORES benchmark for 20 low-resource language directions, demonstrating that MaxEns improves translation quality for low-resource languages while reducing hallucination in translations, compared to both direct translation and an averaging approach. On average, multi-pivot strategies still lag behind using English as a single pivot language, raising the question of how to identify the best pivoting strategy for a given translation direction.
Transformers as Graph-to-Graph Models
Oct 27, 2023We argue that Transformers are essentially graph-to-graph models, with sequences just being a special case. Attention weights are functionally equivalent to graph edges. Our Graph-to-Graph Transformer architecture makes this ability explicit, by inputting graph edges into the attention weight computations and predicting graph edges with attention-like functions, thereby integrating explicit graphs into the latent graphs learned by pretrained Transformers. Adding iterative graph refinement provides a joint embedding of input, output, and latent graphs, allowing non-autoregressive graph prediction to optimise the complete graph without any bespoke pipeline or decoding strategy. Empirical results show that this architecture achieves state-of-the-art accuracies for modelling a variety of linguistic structures, integrating very effectively with the latent linguistic representations learned by pretraining.
Mitigating Hallucinations and Off-target Machine Translation with Source-Contrastive and Language-Contrastive Decoding
Sep 13, 2023

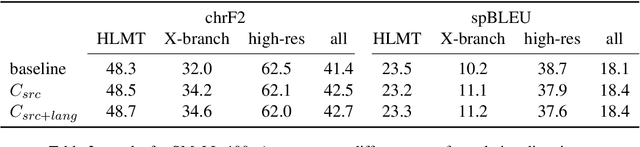

Hallucinations and off-target translation remain unsolved problems in machine translation, especially for low-resource languages and massively multilingual models. In this paper, we introduce methods to mitigate both failure cases with a modified decoding objective, without requiring retraining or external models. In source-contrastive decoding, we search for a translation that is probable given the correct input, but improbable given a random input segment, hypothesising that hallucinations will be similarly probable given either. In language-contrastive decoding, we search for a translation that is probable, but improbable given the wrong language indicator token. In experiments on M2M-100 (418M) and SMaLL-100, we find that these methods effectively suppress hallucinations and off-target translations, improving chrF2 by 1.7 and 1.4 points on average across 57 tested translation directions. In a proof of concept on English--German, we also show that we can suppress off-target translations with the Llama 2 chat models, demonstrating the applicability of the method to machine translation with LLMs. We release our source code at https://github.com/ZurichNLP/ContraDecode.
RQUGE: Reference-Free Metric for Evaluating Question Generation by Answering the Question
Nov 09, 2022Existing metrics for evaluating the quality of automatically generated questions such as BLEU, ROUGE, BERTScore, and BLEURT compare the reference and predicted questions, providing a high score when there is a considerable lexical overlap or semantic similarity between the candidate and the reference questions. This approach has two major shortcomings. First, we need expensive human-provided reference questions. Second, it penalises valid questions that may not have high lexical or semantic similarity to the reference questions. In this paper, we propose a new metric, RQUGE, based on the answerability of the candidate question given the context. The metric consists of a question-answering and a span scorer module, in which we use pre-trained models from the existing literature, and therefore, our metric can be used without further training. We show that RQUGE has a higher correlation with human judgment without relying on the reference question. RQUGE is shown to be significantly more robust to several adversarial corruptions. Additionally, we illustrate that we can significantly improve the performance of QA models on out-of-domain datasets by fine-tuning on the synthetic data generated by a question generation model and re-ranked by RQUGE.
Multilingual Extraction and Categorization of Lexical Collocations with Graph-aware Transformers
May 23, 2022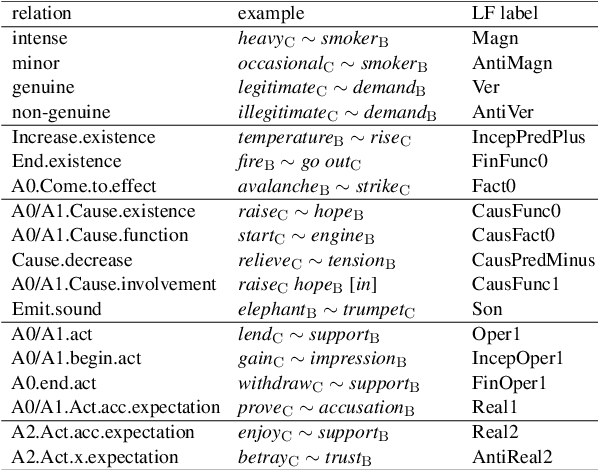
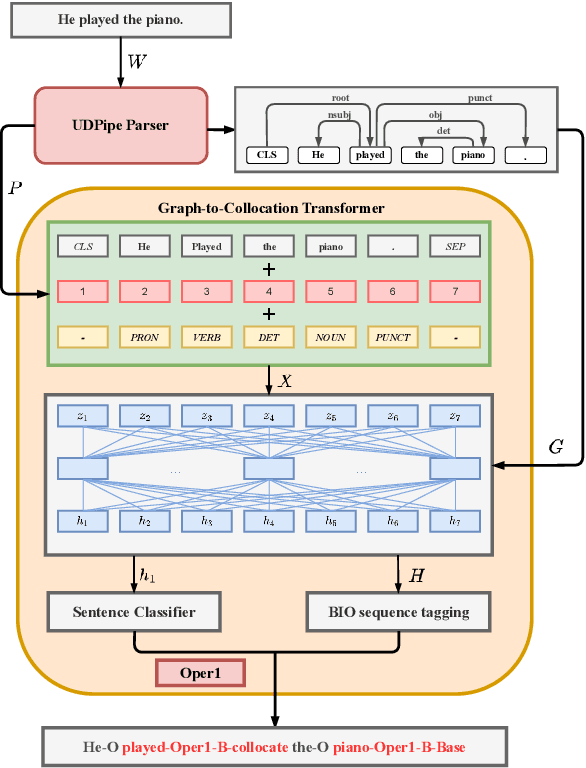
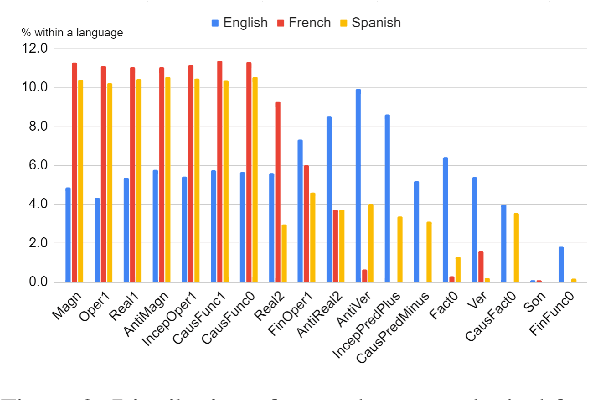
Recognizing and categorizing lexical collocations in context is useful for language learning, dictionary compilation and downstream NLP. However, it is a challenging task due to the varying degrees of frozenness lexical collocations exhibit. In this paper, we put forward a sequence tagging BERT-based model enhanced with a graph-aware transformer architecture, which we evaluate on the task of collocation recognition in context. Our results suggest that explicitly encoding syntactic dependencies in the model architecture is helpful, and provide insights on differences in collocation typification in English, Spanish and French.
What Do Compressed Multilingual Machine Translation Models Forget?
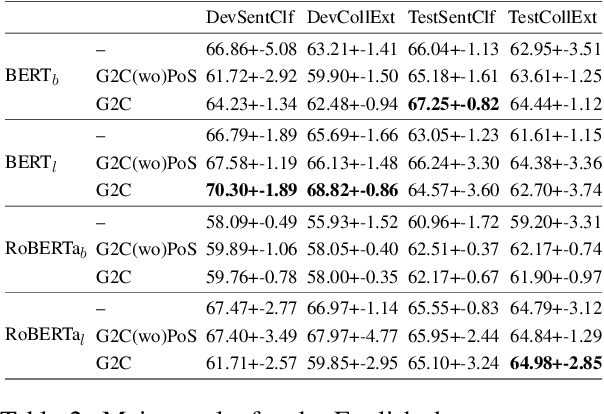
May 22, 2022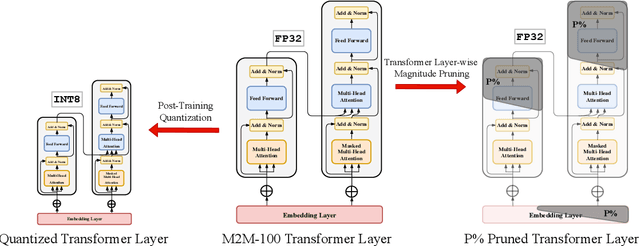

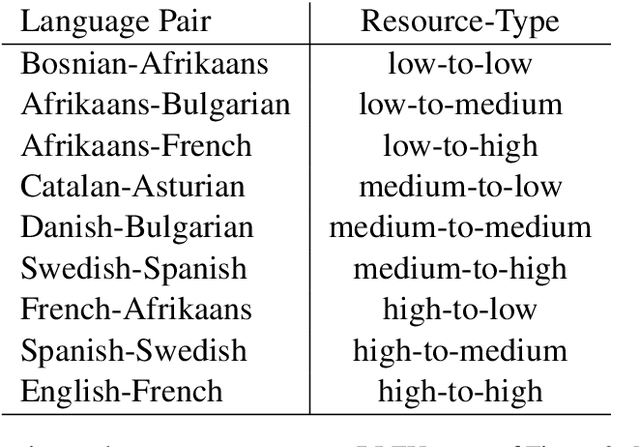
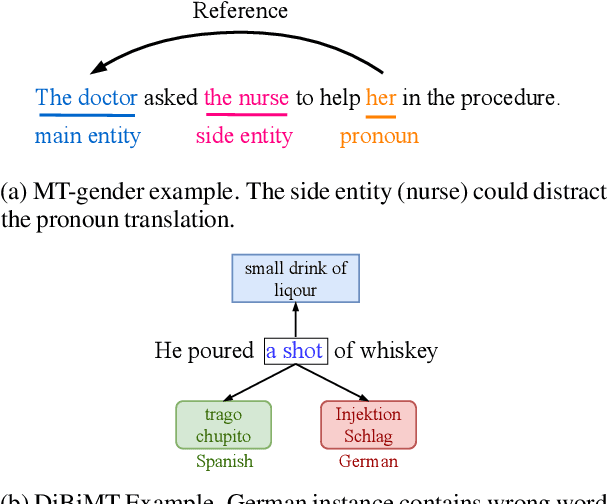
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.
The DCU-EPFL Enhanced Dependency Parser at the IWPT 2021 Shared Task
Jul 05, 2021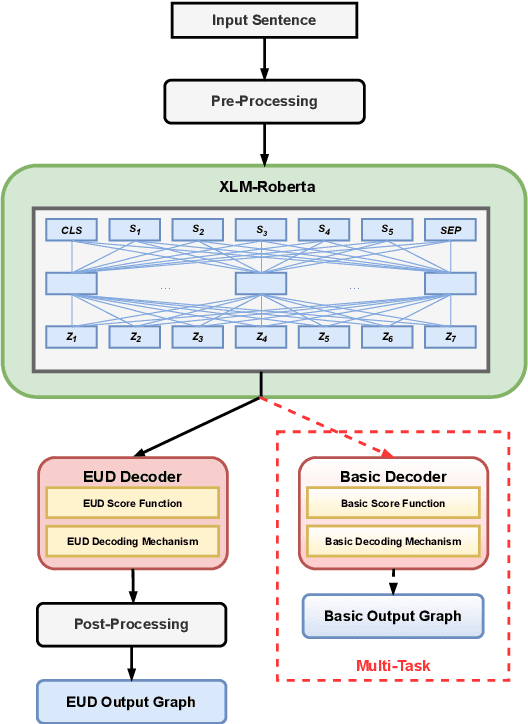
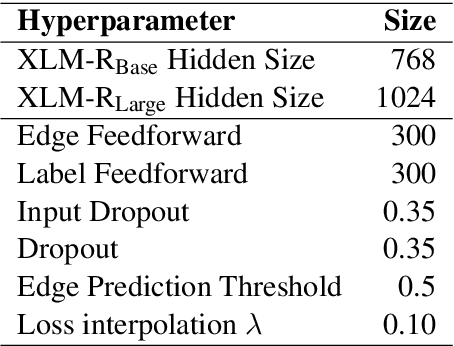

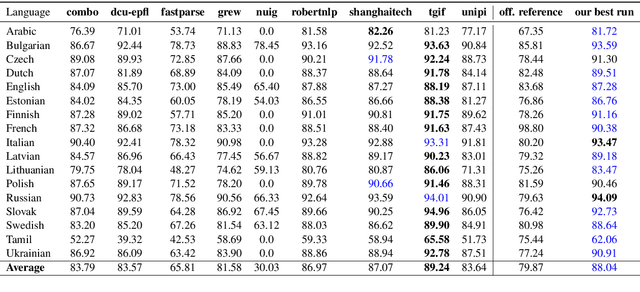
We describe the DCU-EPFL submission to the IWPT 2021 Shared Task on Parsing into Enhanced Universal Dependencies. The task involves parsing Enhanced UD graphs, which are an extension of the basic dependency trees designed to be more facilitative towards representing semantic structure. Evaluation is carried out on 29 treebanks in 17 languages and participants are required to parse the data from each language starting from raw strings. Our approach uses the Stanza pipeline to preprocess the text files, XLMRoBERTa to obtain contextualized token representations, and an edge-scoring and labeling model to predict the enhanced graph. Finally, we run a post-processing script to ensure all of our outputs are valid Enhanced UD graphs. Our system places 6th out of 9 participants with a coarse Enhanced Labeled Attachment Score (ELAS) of 83.57. We carry out additional post-deadline experiments which include using Trankit for pre-processing, XLM-RoBERTa-LARGE, treebank concatenation, and multitask learning between a basic and an enhanced dependency parser. All of these modifications improve our initial score and our final system has a coarse ELAS of 88.04.
Syntax-Aware Graph-to-Graph Transformer for Semantic Role Labelling
Apr 15, 2021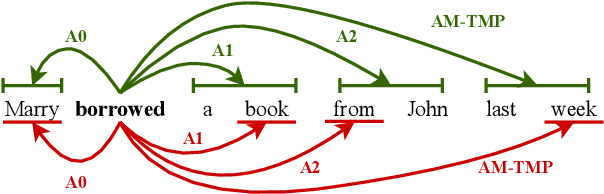


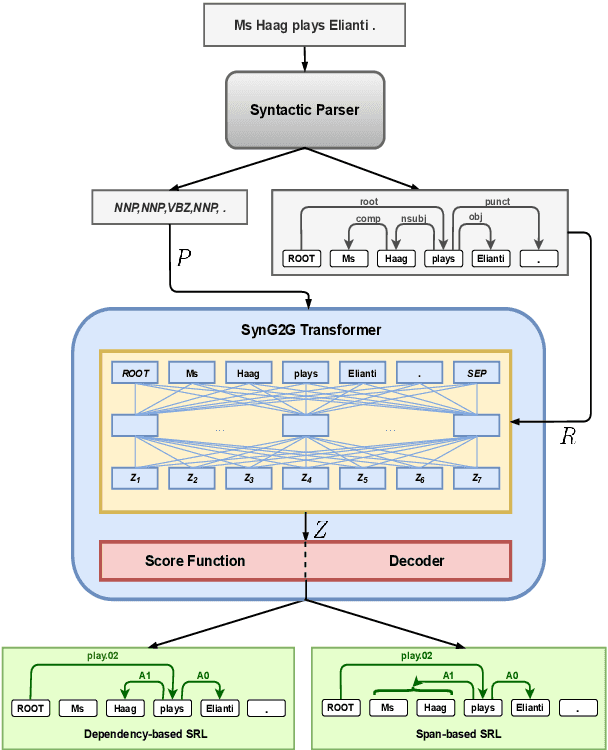
The goal of semantic role labelling (SRL) is to recognise the predicate-argument structure of a sentence. Recent models have shown that syntactic information can enhance the SRL performance, but other syntax-agnostic approaches achieved reasonable performance. The best way to encode syntactic information for the SRL task is still an open question. In this paper, we propose the Syntax-aware Graph-to-Graph Transformer (SynG2G-Tr) architecture, which encodes the syntactic structure with a novel way to input graph relations as embeddings directly into the self-attention mechanism of Transformer. This approach adds a soft bias towards attention patterns that follow the syntactic structure but also allows the model to use this information to learn alternative patterns. We evaluate our model on both dependency-based and span-based SRL datasets, and outperform all previous syntax-aware and syntax-agnostic models in both in-domain and out-of-domain settings, on the CoNLL 2005 and CoNLL 2009 datasets. Our architecture is general and can be applied to encode any graph information for a desired downstream task.