 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic vs. Gold: The Role of LLM-Generated Labels and Data in Cyberbullying Detection
Feb 21, 2025



This study investigates the role of LLM-generated synthetic data in cyberbullying detection. We conduct a series of experiments where we replace some or all of the authentic data with synthetic data, or augment the authentic data with synthetic data. We find that synthetic cyberbullying data can be the basis for training a classifier for harm detection that reaches performance close to that of a classifier trained with authentic data. Combining authentic with synthetic data shows improvements over the baseline of training on authentic data alone for the test data for all three LLMs tried. These results highlight the viability of synthetic data as a scalable, ethically viable alternative in cyberbullying detection while emphasizing the critical impact of LLM selection on performance outcomes.
Revisiting Tri-training of Dependency Parsers
Sep 16, 2021



We compare two orthogonal semi-supervised learning techniques, namely tri-training and pretrained word embeddings, in the task of dependency parsing. We explore language-specific FastText and ELMo embeddings and multilingual BERT embeddings. We focus on a low resource scenario as semi-supervised learning can be expected to have the most impact here. Based on treebank size and available ELMo models, we select Hungarian, Uyghur (a zero-shot language for mBERT) and Vietnamese. Furthermore, we include English in a simulated low-resource setting. We find that pretrained word embeddings make more effective use of unlabelled data than tri-training but that the two approaches can be successfully combined.
gaBERT -- an Irish Language Model
Jul 28, 2021
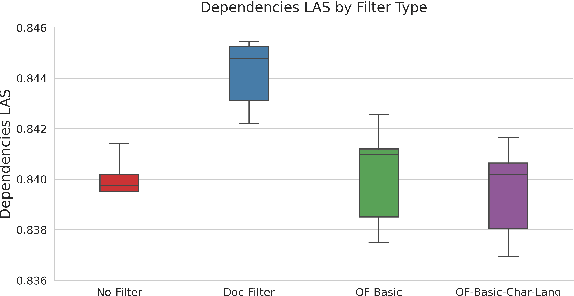
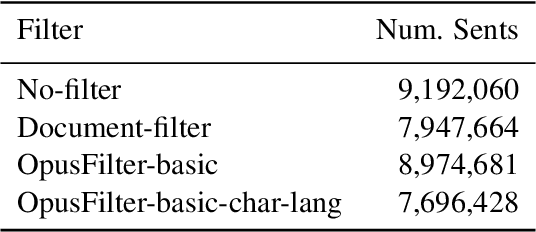
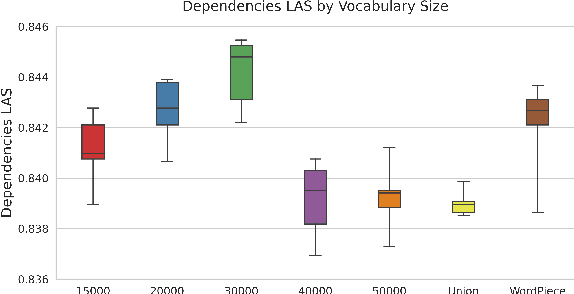
The BERT family of neural language models have become highly popular due to their ability to provide sequences of text with rich context-sensitive token encodings which are able to generalise well to many Natural Language Processing tasks. Over 120 monolingual BERT models covering over 50 languages have been released, as well as a multilingual model trained on 104 languages. We introduce, gaBERT, a monolingual BERT model for the Irish language. We compare our gaBERT model to multilingual BERT and show that gaBERT provides better representations for a downstream parsing task. We also show how different filtering criteria, vocabulary size and the choice of subword tokenisation model affect downstream performance. We release gaBERT and related code to the community.
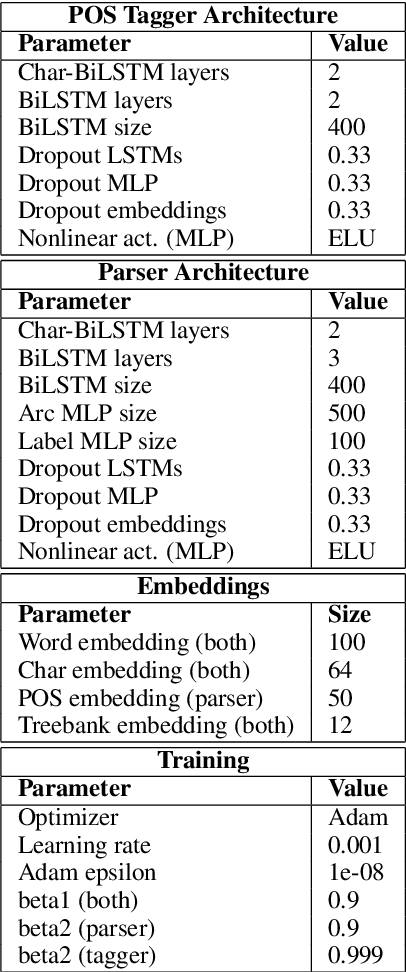
The DCU-EPFL Enhanced Dependency Parser at the IWPT 2021 Shared Task
Jul 05, 2021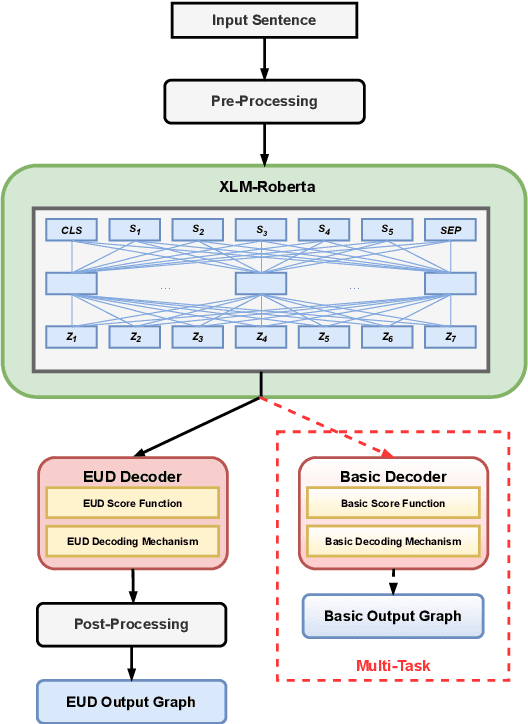
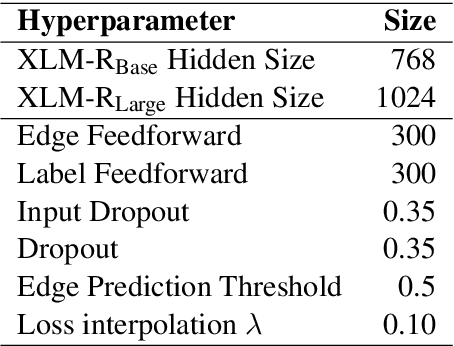

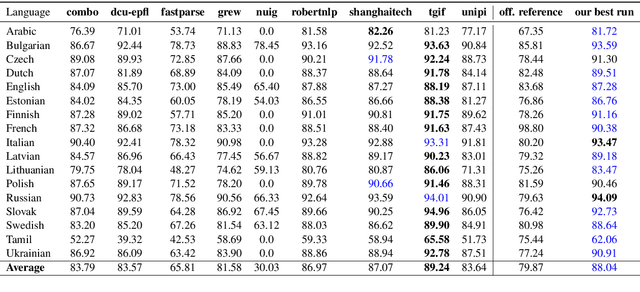
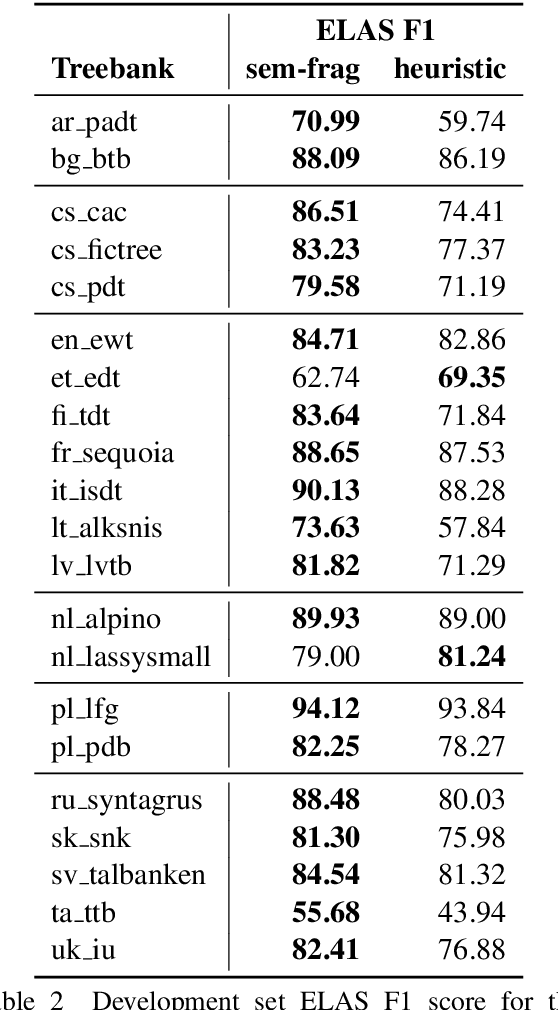
We describe the DCU-EPFL submission to the IWPT 2021 Shared Task on Parsing into Enhanced Universal Dependencies. The task involves parsing Enhanced UD graphs, which are an extension of the basic dependency trees designed to be more facilitative towards representing semantic structure. Evaluation is carried out on 29 treebanks in 17 languages and participants are required to parse the data from each language starting from raw strings. Our approach uses the Stanza pipeline to preprocess the text files, XLMRoBERTa to obtain contextualized token representations, and an edge-scoring and labeling model to predict the enhanced graph. Finally, we run a post-processing script to ensure all of our outputs are valid Enhanced UD graphs. Our system places 6th out of 9 participants with a coarse Enhanced Labeled Attachment Score (ELAS) of 83.57. We carry out additional post-deadline experiments which include using Trankit for pre-processing, XLM-RoBERTa-LARGE, treebank concatenation, and multitask learning between a basic and an enhanced dependency parser. All of these modifications improve our initial score and our final system has a coarse ELAS of 88.04.
The ADAPT Enhanced Dependency Parser at the IWPT 2020 Shared Task
Sep 03, 2020


We describe the ADAPT system for the 2020 IWPT Shared Task on parsing enhanced Universal Dependencies in 17 languages. We implement a pipeline approach using UDPipe and UDPipe-future to provide initial levels of annotation. The enhanced dependency graph is either produced by a graph-based semantic dependency parser or is built from the basic tree using a small set of heuristics. Our results show that, for the majority of languages, a semantic dependency parser can be successfully applied to the task of parsing enhanced dependencies. Unfortunately, we did not ensure a connected graph as part of our pipeline approach and our competition submission relied on a last-minute fix to pass the validation script which harmed our official evaluation scores significantly. Our submission ranked eighth in the official evaluation with a macro-averaged coarse ELAS F1 of 67.23 and a treebank average of 67.49. We later implemented our own graph-connecting fix which resulted in a score of 79.53 (language average) or 79.76 (treebank average), which would have placed fourth in the competition evaluation.
* Submitted to the 2020 IWPT shared task on parsing Enhanced Universal Dependencies
Treebank Embedding Vectors for Out-of-domain Dependency Parsing
May 02, 2020


A recent advance in monolingual dependency parsing is the idea of a treebank embedding vector, which allows all treebanks for a particular language to be used as training data while at the same time allowing the model to prefer training data from one treebank over others and to select the preferred treebank at test time. We build on this idea by 1) introducing a method to predict a treebank vector for sentences that do not come from a treebank used in training, and 2) exploring what happens when we move away from predefined treebank embedding vectors during test time and instead devise tailored interpolations. We show that 1) there are interpolated vectors that are superior to the predefined ones, and 2) treebank vectors can be predicted with sufficient accuracy, for nine out of ten test languages, to match the performance of an oracle approach that knows the most suitable predefined treebank embedding for the test set.
Cross-lingual Parsing with Polyglot Training and Multi-treebank Learning: A Faroese Case Study
Oct 17, 2019


Cross-lingual dependency parsing involves transferring syntactic knowledge from one language to another. It is a crucial component for inducing dependency parsers in low-resource scenarios where no training data for a language exists. Using Faroese as the target language, we compare two approaches using annotation projection: first, projecting from multiple monolingual source models; second, projecting from a single polyglot model which is trained on the combination of all source languages. Furthermore, we reproduce multi-source projection (Tyers et al., 2018), in which dependency trees of multiple sources are combined. Finally, we apply multi-treebank modelling to the projected treebanks, in addition to or alternatively to polyglot modelling on the source side. We find that polyglot training on the source languages produces an overall trend of better results on the target language but the single best result for the target language is obtained by projecting from monolingual source parsing models and then training multi-treebank POS tagging and parsing models on the target side.