 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaelEval: Benchmarking LLM Performance for Scottish Gaelic
Apr 02, 2026Multilingual large language models (LLMs) often exhibit emergent 'shadow' capabilities in languages without official support, yet their performance on these languages remains uneven and under-measured. This is particularly acute for morphosyntactically rich minority languages such as Scottish Gaelic, where translation benchmarks fail to capture structural competence. We introduce GaelEval, the first multi-dimensional benchmark for Gaelic, comprising: (i) an expert-authored morphosyntactic MCQA task; (ii) a culturally grounded translation benchmark and (iii) a large-scale cultural knowledge Q&A task. Evaluating 19 LLMs against a fluent-speaker human baseline ($n=30$), we find that Gemini 3 Pro Preview achieves $83.3\%$ accuracy on the linguistic task, surpassing the human baseline ($78.1\%$). Proprietary models consistently outperform open-weight systems, and in-language (Gaelic) prompting yields a small but stable advantage (+$2.4\%$). On the cultural task, leading models exceed $90\%$ accuracy, though most systems perform worse under Gaelic prompting and absolute scores are inflated relative to the manual benchmark. Overall, GaelEval reveals that frontier models achieve above-human performance on several dimensions of Gaelic grammar, demonstrates the effect of Gaelic prompting and shows a consistent performance gap favouring proprietary over open-weight models.
gaBERT -- an Irish Language Model
Jul 28, 2021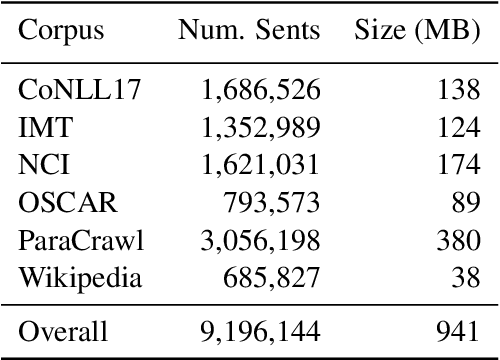
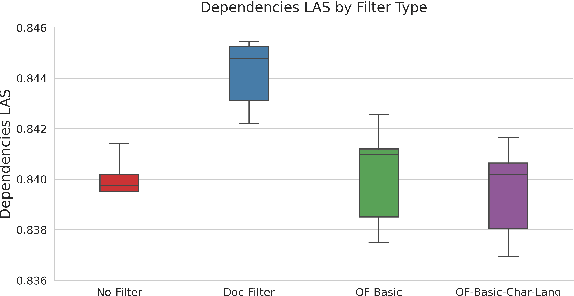
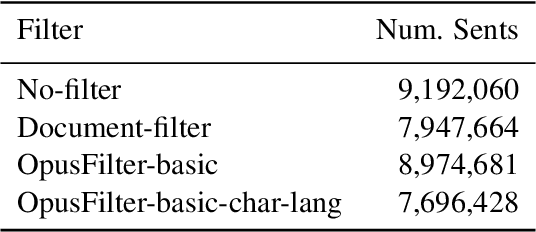
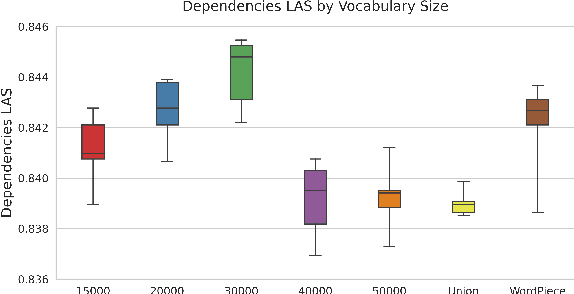
The BERT family of neural language models have become highly popular due to their ability to provide sequences of text with rich context-sensitive token encodings which are able to generalise well to many Natural Language Processing tasks. Over 120 monolingual BERT models covering over 50 languages have been released, as well as a multilingual model trained on 104 languages. We introduce, gaBERT, a monolingual BERT model for the Irish language. We compare our gaBERT model to multilingual BERT and show that gaBERT provides better representations for a downstream parsing task. We also show how different filtering criteria, vocabulary size and the choice of subword tokenisation model affect downstream performance. We release gaBERT and related code to the community.