 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodTaxo: Generating Food Taxonomies with Large Language Models
May 26, 2025We investigate the utility of Large Language Models for automated taxonomy generation and completion specifically applied to taxonomies from the food technology industry. We explore the extent to which taxonomies can be completed from a seed taxonomy or generated without a seed from a set of known concepts, in an iterative fashion using recent prompting techniques. Experiments on five taxonomies using an open-source LLM (Llama-3), while promising, point to the difficulty of correctly placing inner nodes.
No Gold Standard, No Problem: Reference-Free Evaluation of Taxonomies
May 16, 2025We introduce two reference-free metrics for quality evaluation of taxonomies. The first metric evaluates robustness by calculating the correlation between semantic and taxonomic similarity, covering a type of error not handled by existing metrics. The second uses Natural Language Inference to assess logical adequacy. Both metrics are tested on five taxonomies and are shown to correlate well with F1 against gold-standard taxonomies.
FarExStance: Explainable Stance Detection for Farsi
Dec 18, 2024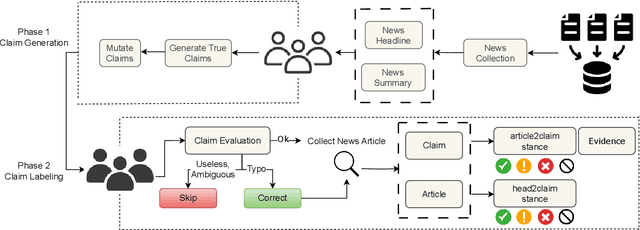
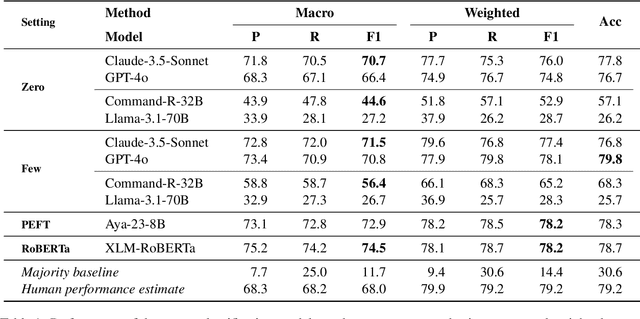

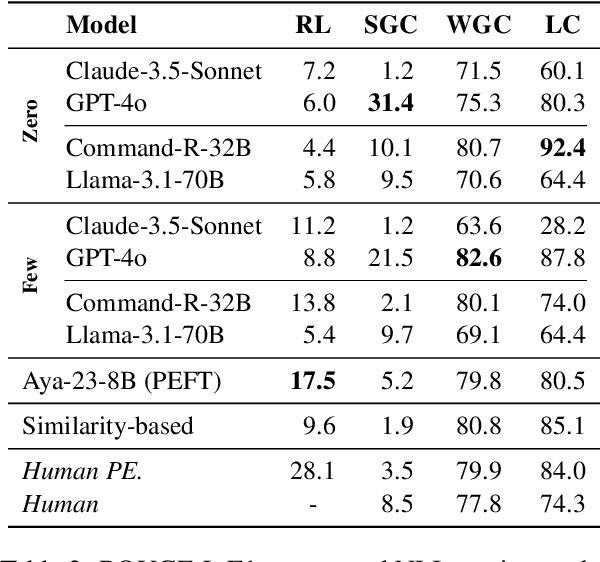
We introduce FarExStance, a new dataset for explainable stance detection in Farsi. Each instance in this dataset contains a claim, the stance of an article or social media post towards that claim, and an extractive explanation which provides evidence for the stance label. We compare the performance of a fine-tuned multilingual RoBERTa model to several large language models in zero-shot, few-shot, and parameter-efficient fine-tuned settings on our new dataset. On stance detection, the most accurate models are the fine-tuned RoBERTa model, the LLM Aya-23-8B which has been fine-tuned using parameter-efficient fine-tuning, and few-shot Claude-3.5-Sonnet. Regarding the quality of the explanations, our automatic evaluation metrics indicate that few-shot GPT-4o generates the most coherent explanations, while our human evaluation reveals that the best Overall Explanation Score (OES) belongs to few-shot Claude-3.5-Sonnet. The fine-tuned Aya-32-8B model produced explanations most closely aligned with the reference explanations.
Tell Me Why: Explainable Public Health Fact-Checking with Large Language Models
May 15, 2024



This paper presents a comprehensive analysis of explainable fact-checking through a series of experiments, focusing on the ability of large language models to verify public health claims and provide explanations or justifications for their veracity assessments. We examine the effectiveness of zero/few-shot prompting and parameter-efficient fine-tuning across various open and closed-source models, examining their performance in both isolated and joint tasks of veracity prediction and explanation generation. Importantly, we employ a dual evaluation approach comprising previously established automatic metrics and a novel set of criteria through human evaluation. Our automatic evaluation indicates that, within the zero-shot scenario, GPT-4 emerges as the standout performer, but in few-shot and parameter-efficient fine-tuning contexts, open-source models demonstrate their capacity to not only bridge the performance gap but, in some instances, surpass GPT-4. Human evaluation reveals yet more nuance as well as indicating potential problems with the gold explanations.
Do Stochastic Parrots have Feelings Too? Improving Neural Detection of Synthetic Text via Emotion Recognition
Oct 24, 2023



Recent developments in generative AI have shone a spotlight on high-performance synthetic text generation technologies. The now wide availability and ease of use of such models highlights the urgent need to provide equally powerful technologies capable of identifying synthetic text. With this in mind, we draw inspiration from psychological studies which suggest that people can be driven by emotion and encode emotion in the text they compose. We hypothesize that pretrained language models (PLMs) have an affective deficit because they lack such an emotional driver when generating text and consequently may generate synthetic text which has affective incoherence i.e. lacking the kind of emotional coherence present in human-authored text. We subsequently develop an emotionally aware detector by fine-tuning a PLM on emotion. Experiment results indicate that our emotionally-aware detector achieves improvements across a range of synthetic text generators, various sized models, datasets, and domains. Finally, we compare our emotionally-aware synthetic text detector to ChatGPT in the task of identification of its own output and show substantial gains, reinforcing the potential of emotion as a signal to identify synthetic text. Code, models, and datasets are available at https: //github.com/alanagiasi/emoPLMsynth
Out-of-Distribution Generalization in Text Classification: Past, Present, and Future
May 23, 2023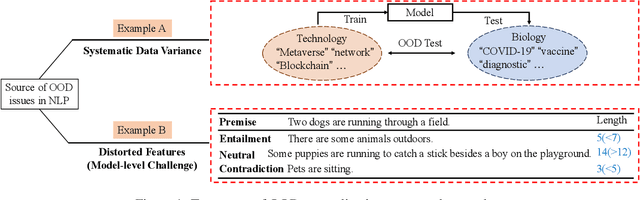
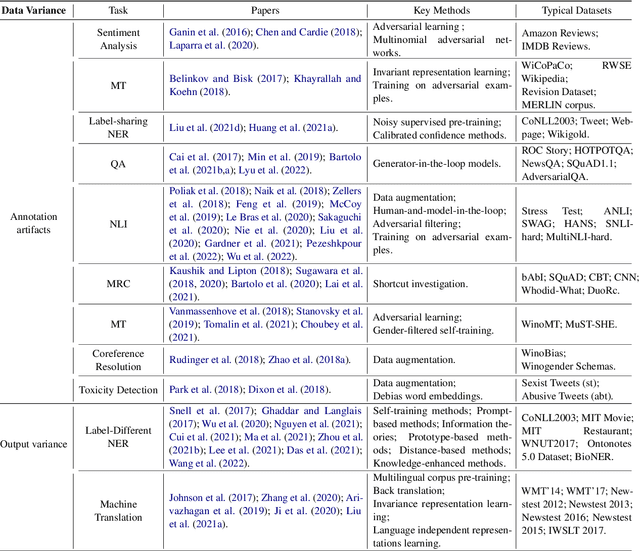
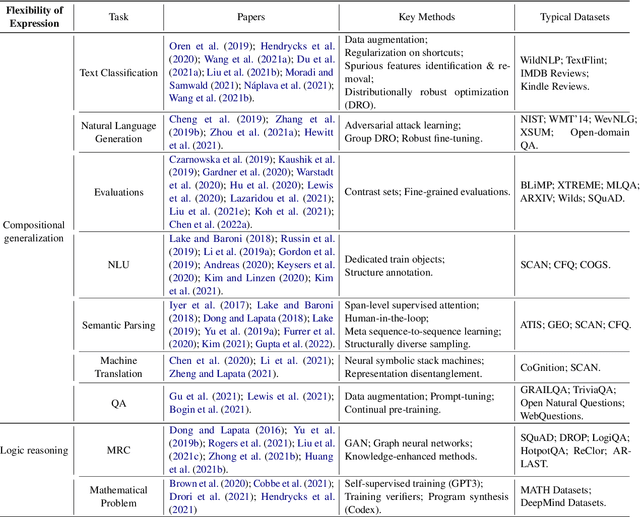
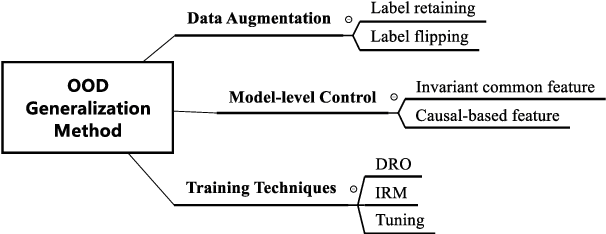
Machine learning (ML) systems in natural language processing (NLP) face significant challenges in generalizing to out-of-distribution (OOD) data, where the test distribution differs from the training data distribution. This poses important questions about the robustness of NLP models and their high accuracy, which may be artificially inflated due to their underlying sensitivity to systematic biases. Despite these challenges, there is a lack of comprehensive surveys on the generalization challenge from an OOD perspective in text classification. Therefore, this paper aims to fill this gap by presenting the first comprehensive review of recent progress, methods, and evaluations on this topic. We furth discuss the challenges involved and potential future research directions. By providing quick access to existing work, we hope this survey will encourage future research in this area.
Is a Video worth $n\times n$ Images? A Highly Efficient Approach to Transformer-based Video Question Answering
May 16, 2023



Conventional Transformer-based Video Question Answering (VideoQA) approaches generally encode frames independently through one or more image encoders followed by interaction between frames and question. However, such schema would incur significant memory use and inevitably slow down the training and inference speed. In this work, we present a highly efficient approach for VideoQA based on existing vision-language pre-trained models where we concatenate video frames to a $n\times n$ matrix and then convert it to one image. By doing so, we reduce the use of the image encoder from $n^{2}$ to $1$ while maintaining the temporal structure of the original video. Experimental results on MSRVTT and TrafficQA show that our proposed approach achieves state-of-the-art performance with nearly $4\times$ faster speed and only 30% memory use. We show that by integrating our approach into VideoQA systems we can achieve comparable, even superior, performance with a significant speed up for training and inference. We believe the proposed approach can facilitate VideoQA-related research by reducing the computational requirements for those who have limited access to budgets and resources. Our code will be made publicly available for research use.
Semantic-aware Dynamic Retrospective-Prospective Reasoning for Event-level Video Question Answering
May 14, 2023



Event-Level Video Question Answering (EVQA) requires complex reasoning across video events to obtain the visual information needed to provide optimal answers. However, despite significant progress in model performance, few studies have focused on using the explicit semantic connections between the question and visual information especially at the event level. There is need for using such semantic connections to facilitate complex reasoning across video frames. Therefore, we propose a semantic-aware dynamic retrospective-prospective reasoning approach for video-based question answering. Specifically, we explicitly use the Semantic Role Labeling (SRL) structure of the question in the dynamic reasoning process where we decide to move to the next frame based on which part of the SRL structure (agent, verb, patient, etc.) of the question is being focused on. We conduct experiments on a benchmark EVQA dataset - TrafficQA. Results show that our proposed approach achieves superior performance compared to previous state-of-the-art models. Our code will be made publicly available for research use.
Dialogue-to-Video Retrieval
Mar 23, 2023Recent years have witnessed an increasing amount of dialogue/conversation on the web especially on social media. That inspires the development of dialogue-based retrieval, in which retrieving videos based on dialogue is of increasing interest for recommendation systems. Different from other video retrieval tasks, dialogue-to-video retrieval uses structured queries in the form of user-generated dialogue as the search descriptor. We present a novel dialogue-to-video retrieval system, incorporating structured conversational information. Experiments conducted on the AVSD dataset show that our proposed approach using plain-text queries improves over the previous counterpart model by 15.8% on R@1. Furthermore, our approach using dialogue as a query, improves retrieval performance by 4.2%, 6.2%, 8.6% on R@1, R@5 and R@10 and outperforms the state-of-the-art model by 0.7%, 3.6% and 6.0% on R@1, R@5 and R@10 respectively.
Exploiting Rich Textual User-Product Context for Improving Sentiment Analysis
Dec 17, 2022



User and product information associated with a review is useful for sentiment polarity prediction. Typical approaches incorporating such information focus on modeling users and products as implicitly learned representation vectors. Most do not exploit the potential of historical reviews, or those that currently do require unnecessary modifications to model architecture or do not make full use of user/product associations. The contribution of this work is twofold: i) a method to explicitly employ historical reviews belonging to the same user/product to initialize representations, and ii) efficient incorporation of textual associations between users and products via a user-product cross-context module. Experiments on IMDb, Yelp-2013 and Yelp-2014 benchmarks show that our approach substantially outperforms previous state-of-the-art. Since we employ BERT-base as the encoder, we additionally provide experiments in which our approach performs well with Span-BERT and Longformer. Furthermore, experiments where the reviews of each user/product in the training data are downsampled demonstrate the effectiveness of our approach under a low-resource setting.