 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodTaxo: Generating Food Taxonomies with Large Language Models
May 26, 2025We investigate the utility of Large Language Models for automated taxonomy generation and completion specifically applied to taxonomies from the food technology industry. We explore the extent to which taxonomies can be completed from a seed taxonomy or generated without a seed from a set of known concepts, in an iterative fashion using recent prompting techniques. Experiments on five taxonomies using an open-source LLM (Llama-3), while promising, point to the difficulty of correctly placing inner nodes.
No Gold Standard, No Problem: Reference-Free Evaluation of Taxonomies
May 16, 2025We introduce two reference-free metrics for quality evaluation of taxonomies. The first metric evaluates robustness by calculating the correlation between semantic and taxonomic similarity, covering a type of error not handled by existing metrics. The second uses Natural Language Inference to assess logical adequacy. Both metrics are tested on five taxonomies and are shown to correlate well with F1 against gold-standard taxonomies.
FarExStance: Explainable Stance Detection for Farsi
Dec 18, 2024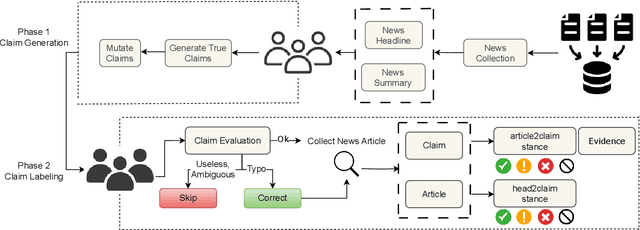
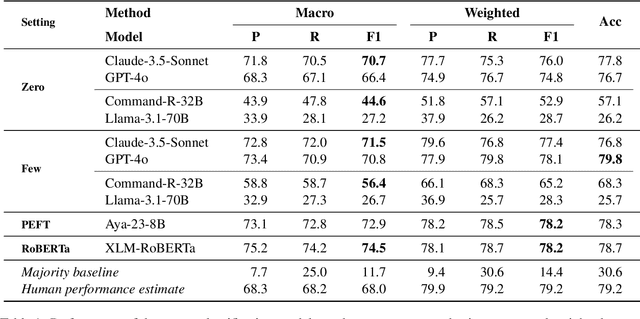

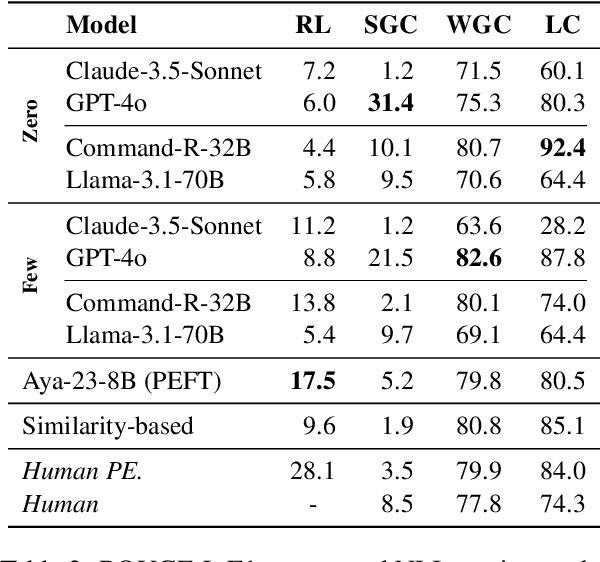
We introduce FarExStance, a new dataset for explainable stance detection in Farsi. Each instance in this dataset contains a claim, the stance of an article or social media post towards that claim, and an extractive explanation which provides evidence for the stance label. We compare the performance of a fine-tuned multilingual RoBERTa model to several large language models in zero-shot, few-shot, and parameter-efficient fine-tuned settings on our new dataset. On stance detection, the most accurate models are the fine-tuned RoBERTa model, the LLM Aya-23-8B which has been fine-tuned using parameter-efficient fine-tuning, and few-shot Claude-3.5-Sonnet. Regarding the quality of the explanations, our automatic evaluation metrics indicate that few-shot GPT-4o generates the most coherent explanations, while our human evaluation reveals that the best Overall Explanation Score (OES) belongs to few-shot Claude-3.5-Sonnet. The fine-tuned Aya-32-8B model produced explanations most closely aligned with the reference explanations.
Tell Me Why: Explainable Public Health Fact-Checking with Large Language Models
May 15, 2024



This paper presents a comprehensive analysis of explainable fact-checking through a series of experiments, focusing on the ability of large language models to verify public health claims and provide explanations or justifications for their veracity assessments. We examine the effectiveness of zero/few-shot prompting and parameter-efficient fine-tuning across various open and closed-source models, examining their performance in both isolated and joint tasks of veracity prediction and explanation generation. Importantly, we employ a dual evaluation approach comprising previously established automatic metrics and a novel set of criteria through human evaluation. Our automatic evaluation indicates that, within the zero-shot scenario, GPT-4 emerges as the standout performer, but in few-shot and parameter-efficient fine-tuning contexts, open-source models demonstrate their capacity to not only bridge the performance gap but, in some instances, surpass GPT-4. Human evaluation reveals yet more nuance as well as indicating potential problems with the gold explanations.