 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord2winners at SemEval-2025 Task 7: Multilingual and Crosslingual Fact-Checked Claim Retrieval
Mar 12, 2025



This paper describes our system for SemEval 2025 Task 7: Previously Fact-Checked Claim Retrieval. The task requires retrieving relevant fact-checks for a given input claim from the extensive, multilingual MultiClaim dataset, which comprises social media posts and fact-checks in several languages. To address this challenge, we first evaluated zero-shot performance using state-of-the-art English and multilingual retrieval models and then fine-tuned the most promising systems, leveraging machine translation to enhance crosslingual retrieval. Our best model achieved an accuracy of 85% on crosslingual data and 92% on monolingual data.
FarExStance: Explainable Stance Detection for Farsi
Dec 18, 2024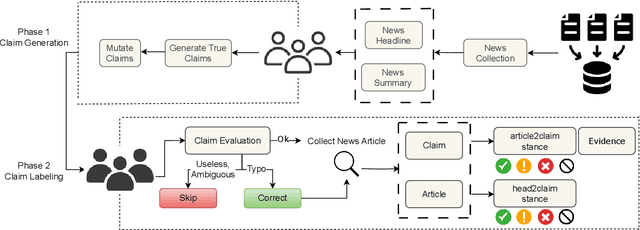
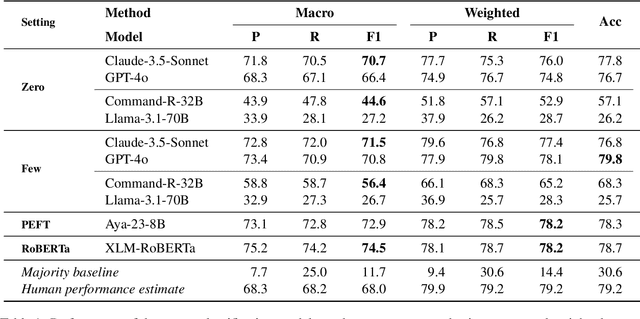

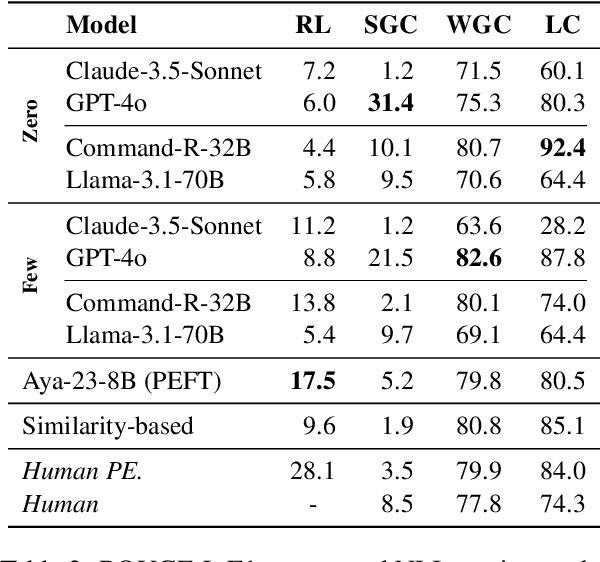
We introduce FarExStance, a new dataset for explainable stance detection in Farsi. Each instance in this dataset contains a claim, the stance of an article or social media post towards that claim, and an extractive explanation which provides evidence for the stance label. We compare the performance of a fine-tuned multilingual RoBERTa model to several large language models in zero-shot, few-shot, and parameter-efficient fine-tuned settings on our new dataset. On stance detection, the most accurate models are the fine-tuned RoBERTa model, the LLM Aya-23-8B which has been fine-tuned using parameter-efficient fine-tuning, and few-shot Claude-3.5-Sonnet. Regarding the quality of the explanations, our automatic evaluation metrics indicate that few-shot GPT-4o generates the most coherent explanations, while our human evaluation reveals that the best Overall Explanation Score (OES) belongs to few-shot Claude-3.5-Sonnet. The fine-tuned Aya-32-8B model produced explanations most closely aligned with the reference explanations.
Illusory VQA: Benchmarking and Enhancing Multimodal Models on Visual Illusions
Dec 11, 2024



In recent years, Visual Question Answering (VQA) has made significant strides, particularly with the advent of multimodal models that integrate vision and language understanding. However, existing VQA datasets often overlook the complexities introduced by image illusions, which pose unique challenges for both human perception and model interpretation. In this study, we introduce a novel task called Illusory VQA, along with four specialized datasets: IllusionMNIST, IllusionFashionMNIST, IllusionAnimals, and IllusionChar. These datasets are designed to evaluate the performance of state-of-the-art multimodal models in recognizing and interpreting visual illusions. We assess the zero-shot performance of various models, fine-tune selected models on our datasets, and propose a simple yet effective solution for illusion detection using Gaussian and blur low-pass filters. We show that this method increases the performance of models significantly and in the case of BLIP-2 on IllusionAnimals without any fine-tuning, it outperforms humans. Our findings highlight the disparity between human and model perception of illusions and demonstrate that fine-tuning and specific preprocessing techniques can significantly enhance model robustness. This work contributes to the development of more human-like visual understanding in multimodal models and suggests future directions for adapting filters using learnable parameters.
eagerlearners at SemEval2024 Task 5: The Legal Argument Reasoning Task in Civil Procedure
Jun 24, 2024



This study investigates the performance of the zero-shot method in classifying data using three large language models, alongside two models with large input token sizes and the two pre-trained models on legal data. Our main dataset comes from the domain of U.S. civil procedure. It includes summaries of legal cases, specific questions, potential answers, and detailed explanations for why each solution is relevant, all sourced from a book aimed at law students. By comparing different methods, we aimed to understand how effectively they handle the complexities found in legal datasets. Our findings show how well the zero-shot method of large language models can understand complicated data. We achieved our highest F1 score of 64% in these experiments.
BAMO at SemEval-2024 Task 9: BRAINTEASER: A Novel Task Defying Common Sense
Jun 07, 2024



This paper outlines our approach to SemEval 2024 Task 9, BRAINTEASER: A Novel Task Defying Common Sense. The task aims to evaluate the ability of language models to think creatively. The dataset comprises multi-choice questions that challenge models to think "outside of the box". We fine-tune 2 models, BERT and RoBERTa Large. Next, we employ a Chain of Thought (CoT) zero-shot prompting approach with 6 large language models, such as GPT-3.5, Mixtral, and Llama2. Finally, we utilize ReConcile, a technique that employs a "round table conference" approach with multiple agents for zero-shot learning, to generate consensus answers among 3 selected language models. Our best method achieves an overall accuracy of 85 percent on the sentence puzzles subtask.
Zero-Shot Stance Detection using Contextual Data Generation with LLMs
May 19, 2024Stance detection, the classification of attitudes expressed in a text towards a specific topic, is vital for applications like fake news detection and opinion mining. However, the scarcity of labeled data remains a challenge for this task. To address this problem, we propose Dynamic Model Adaptation with Contextual Data Generation (DyMoAdapt) that combines Few-Shot Learning and Large Language Models. In this approach, we aim to fine-tune an existing model at test time. We achieve this by generating new topic-specific data using GPT-3. This method could enhance performance by allowing the adaptation of the model to new topics. However, the results did not increase as we expected. Furthermore, we introduce the Multi Generated Topic VAST (MGT-VAST) dataset, which extends VAST using GPT-3. In this dataset, each context is associated with multiple topics, allowing the model to understand the relationship between contexts and various potential topics
* 5 pages, AAAI-2024 Workshop on Public Sector LLMs
StackOverflowVQA: Stack Overflow Visual Question Answering Dataset
May 17, 2024In recent years, people have increasingly used AI to help them with their problems by asking questions on different topics. One of these topics can be software-related and programming questions. In this work, we focus on the questions which need the understanding of images in addition to the question itself. We introduce the StackOverflowVQA dataset, which includes questions from StackOverflow that have one or more accompanying images. This is the first VQA dataset that focuses on software-related questions and contains multiple human-generated full-sentence answers. Additionally, we provide a baseline for answering the questions with respect to images in the introduced dataset using the GIT model. All versions of the dataset are available at https://huggingface.co/mirzaei2114.
LXMERT Model Compression for Visual Question Answering
Oct 23, 2023Large-scale pretrained models such as LXMERT are becoming popular for learning cross-modal representations on text-image pairs for vision-language tasks. According to the lottery ticket hypothesis, NLP and computer vision models contain smaller subnetworks capable of being trained in isolation to full performance. In this paper, we combine these observations to evaluate whether such trainable subnetworks exist in LXMERT when fine-tuned on the VQA task. In addition, we perform a model size cost-benefit analysis by investigating how much pruning can be done without significant loss in accuracy. Our experiment results demonstrate that LXMERT can be effectively pruned by 40%-60% in size with 3% loss in accuracy.
Using Two Losses and Two Datasets Simultaneously to Improve TempoWiC Accuracy
Dec 15, 2022
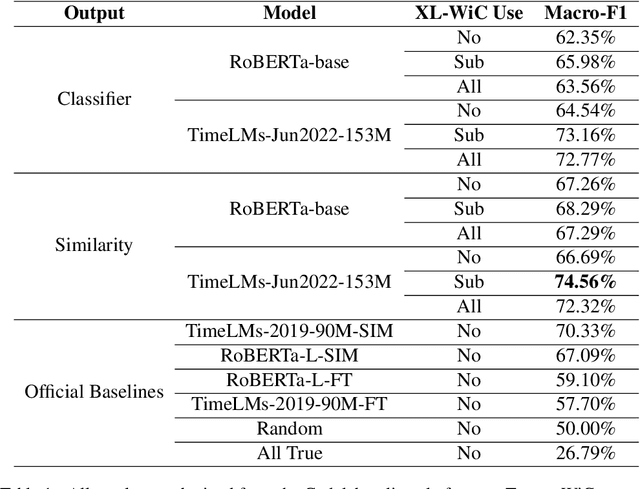
WSD (Word Sense Disambiguation) is the task of identifying which sense of a word is meant in a sentence or other segment of text. Researchers have worked on this task (e.g. Pustejovsky, 2002) for years but it's still a challenging one even for SOTA (state-of-the-art) LMs (language models). The new dataset, TempoWiC introduced by Loureiro et al. (2022b) focuses on the fact that words change over time. Their best baseline achieves 70.33% macro-F1. In this work, we use two different losses simultaneously to train RoBERTa-based classification models. We also improve our model by using another similar dataset to generalize better. Our best configuration beats their best baseline by 4.23% and reaches 74.56% macroF1.
Personality Trait Detection Using Bagged SVM over BERT Word Embedding Ensembles
Oct 03, 2020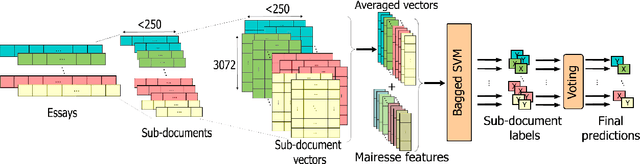
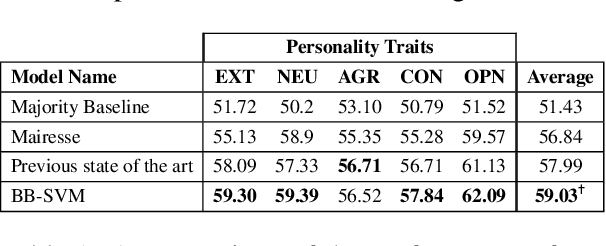
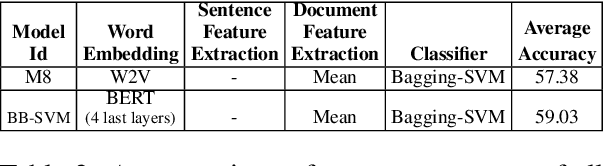
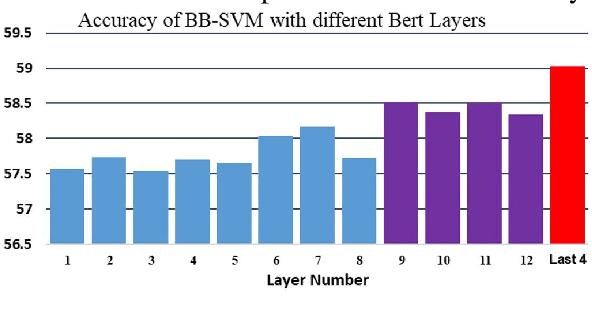
Recently, the automatic prediction of personality traits has received increasing attention and has emerged as a hot topic within the field of affective computing. In this work, we present a novel deep learning-based approach for automated personality detection from text. We leverage state of the art advances in natural language understanding, namely the BERT language model to extract contextualized word embeddings from textual data for automated author personality detection. Our primary goal is to develop a computationally efficient, high-performance personality prediction model which can be easily used by a large number of people without access to huge computation resources. Our extensive experiments with this ideology in mind, led us to develop a novel model which feeds contextualized embeddings along with psycholinguistic features toa Bagged-SVM classifier for personality trait prediction. Our model outperforms the previous state of the art by 1.04% and, at the same time is significantly more computationally efficient to train. We report our results on the famous gold standard Essays dataset for personality detection.