Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Two Losses and Two Datasets Simultaneously to Improve TempoWiC Accuracy
Paper and Code
Dec 15, 2022
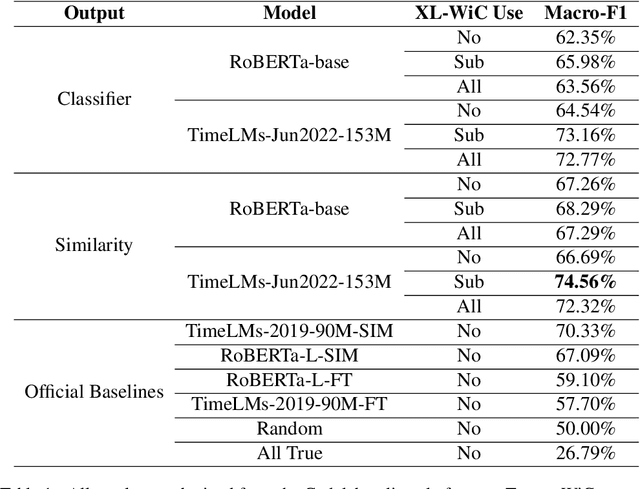
WSD (Word Sense Disambiguation) is the task of identifying which sense of a word is meant in a sentence or other segment of text. Researchers have worked on this task (e.g. Pustejovsky, 2002) for years but it's still a challenging one even for SOTA (state-of-the-art) LMs (language models). The new dataset, TempoWiC introduced by Loureiro et al. (2022b) focuses on the fact that words change over time. Their best baseline achieves 70.33% macro-F1. In this work, we use two different losses simultaneously to train RoBERTa-based classification models. We also improve our model by using another similar dataset to generalize better. Our best configuration beats their best baseline by 4.23% and reaches 74.56% macroF1.
View paper on