 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegotiationGym: Self-Optimizing Agents in a Multi-Agent Social Simulation Environment
Oct 05, 2025We design and implement NegotiationGym, an API and user interface for configuring and running multi-agent social simulations focused upon negotiation and cooperation. The NegotiationGym codebase offers a user-friendly, configuration-driven API that enables easy design and customization of simulation scenarios. Agent-level utility functions encode optimization criteria for each agent, and agents can self-optimize by conducting multiple interaction rounds with other agents, observing outcomes, and modifying their strategies for future rounds.
gaBERT -- an Irish Language Model
Jul 28, 2021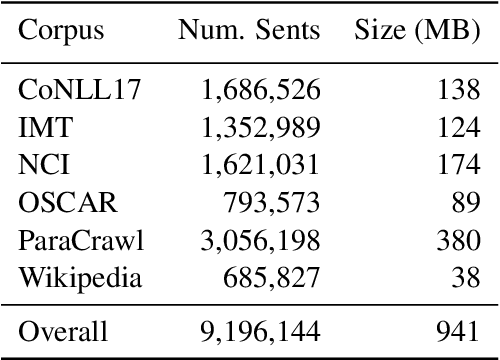
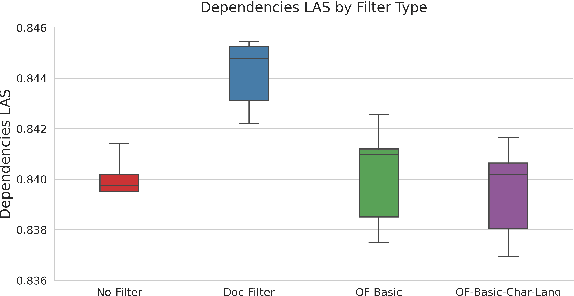
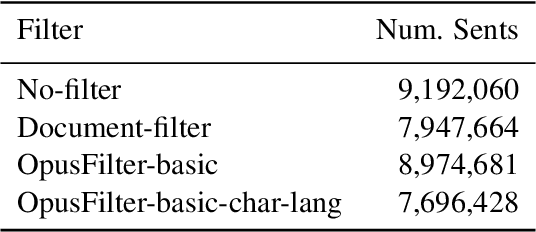
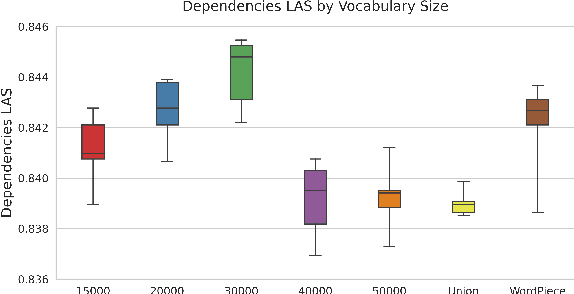
The BERT family of neural language models have become highly popular due to their ability to provide sequences of text with rich context-sensitive token encodings which are able to generalise well to many Natural Language Processing tasks. Over 120 monolingual BERT models covering over 50 languages have been released, as well as a multilingual model trained on 104 languages. We introduce, gaBERT, a monolingual BERT model for the Irish language. We compare our gaBERT model to multilingual BERT and show that gaBERT provides better representations for a downstream parsing task. We also show how different filtering criteria, vocabulary size and the choice of subword tokenisation model affect downstream performance. We release gaBERT and related code to the community.
Treebanking User-Generated Content: a UD Based Overview of Guidelines, Corpora and Unified Recommendations
Nov 03, 2020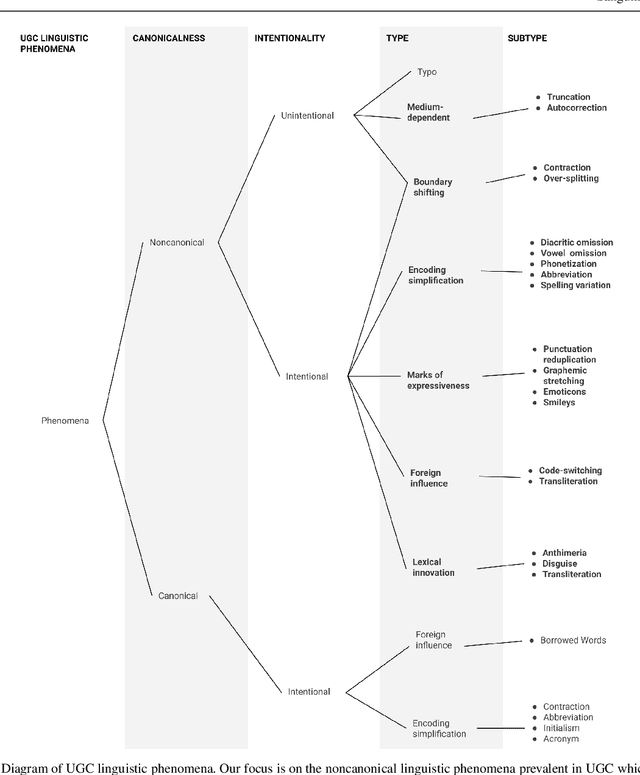
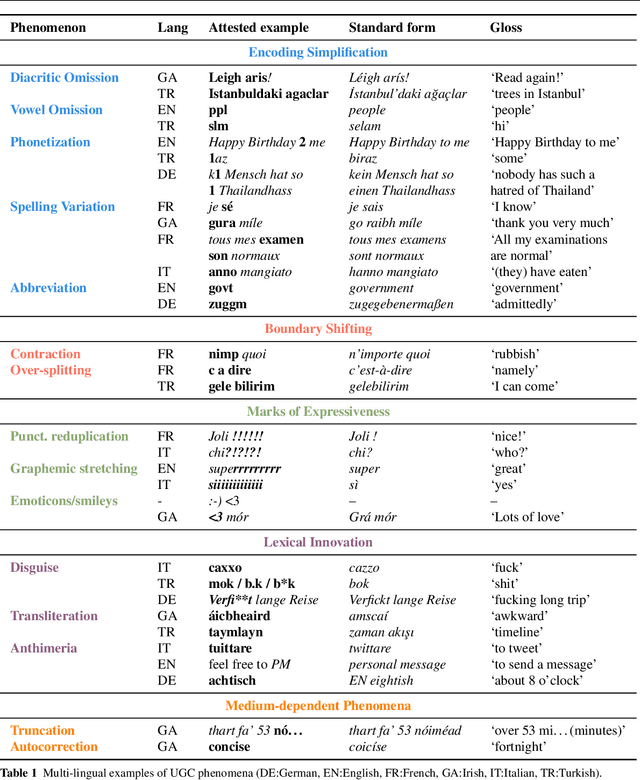
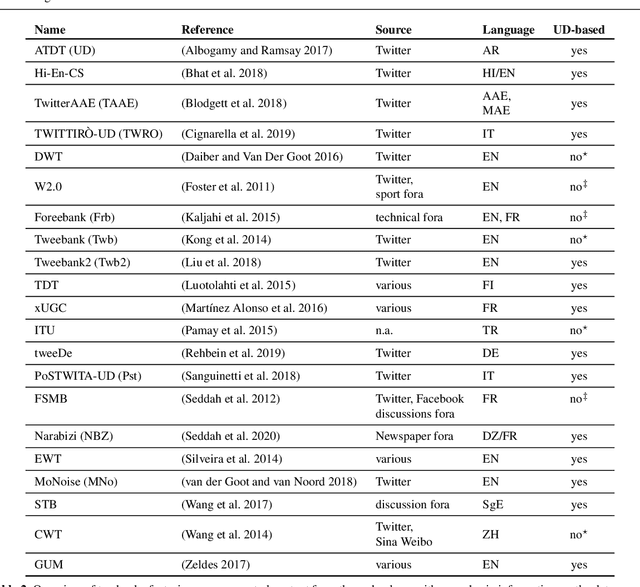
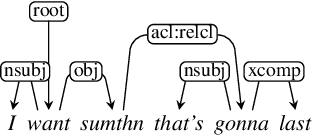
This article presents a discussion on the main linguistic phenomena which cause difficulties in the analysis of user-generated texts found on the web and in social media, and proposes a set of annotation guidelines for their treatment within the Universal Dependencies (UD) framework of syntactic analysis. Given on the one hand the increasing number of treebanks featuring user-generated content, and its somewhat inconsistent treatment in these resources on the other, the aim of this article is twofold: (1) to provide a condensed, though comprehensive, overview of such treebanks -- based on available literature -- along with their main features and a comparative analysis of their annotation criteria, and (2) to propose a set of tentative UD-based annotation guidelines, to promote consistent treatment of the particular phenomena found in these types of texts. The overarching goal of this article is to provide a common framework for researchers interested in developing similar resources in UD, thus promoting cross-linguistic consistency, which is a principle that has always been central to the spirit of UD.