 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResources for Turkish Natural Language Processing: A critical survey
Apr 11, 2022

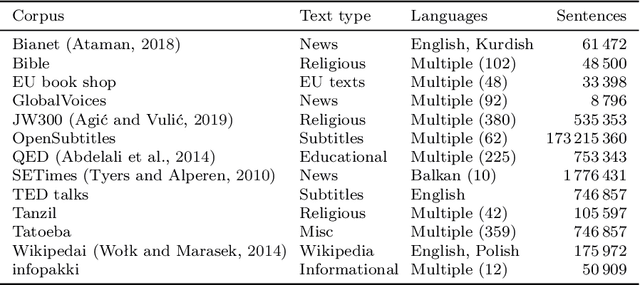

This paper presents a comprehensive survey of corpora and lexical resources available for Turkish. We review a broad range of resources, focusing on the ones that are publicly available. In addition to providing information about the available linguistic resources, we present a set of recommendations, and identify gaps in the data available for conducting research and building applications in Turkish Linguistics and Natural Language Processing.
Treebanking User-Generated Content: a UD Based Overview of Guidelines, Corpora and Unified Recommendations
Nov 03, 2020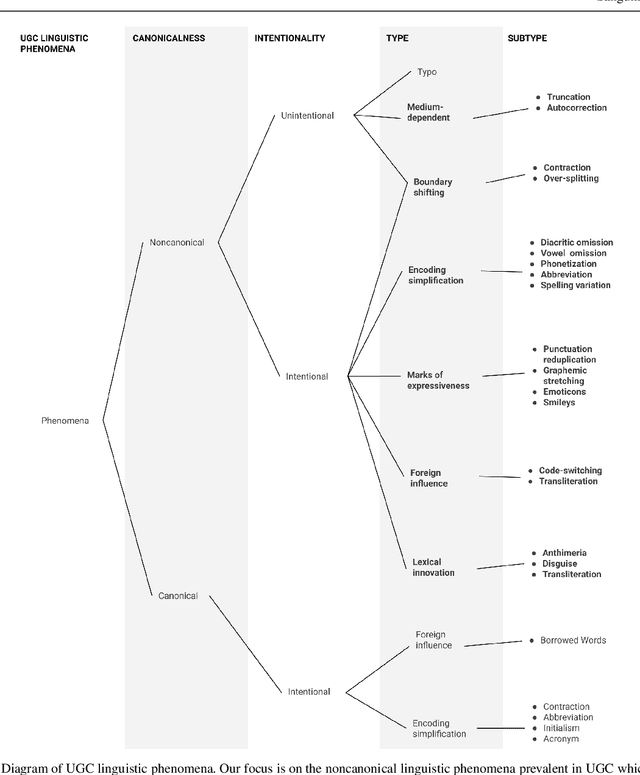
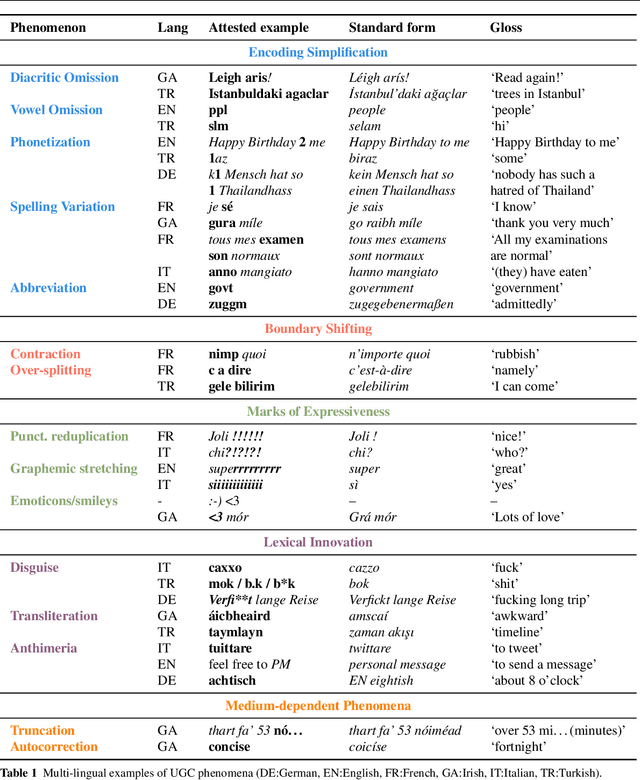
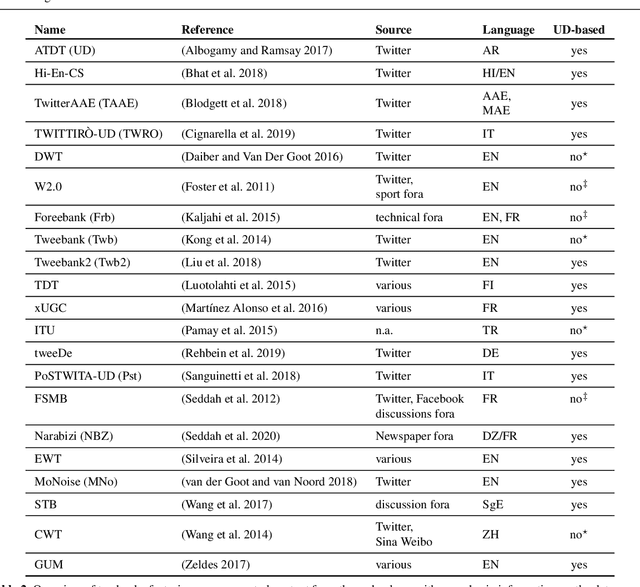
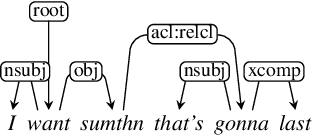
This article presents a discussion on the main linguistic phenomena which cause difficulties in the analysis of user-generated texts found on the web and in social media, and proposes a set of annotation guidelines for their treatment within the Universal Dependencies (UD) framework of syntactic analysis. Given on the one hand the increasing number of treebanks featuring user-generated content, and its somewhat inconsistent treatment in these resources on the other, the aim of this article is twofold: (1) to provide a condensed, though comprehensive, overview of such treebanks -- based on available literature -- along with their main features and a comparative analysis of their annotation criteria, and (2) to propose a set of tentative UD-based annotation guidelines, to promote consistent treatment of the particular phenomena found in these types of texts. The overarching goal of this article is to provide a common framework for researchers interested in developing similar resources in UD, thus promoting cross-linguistic consistency, which is a principle that has always been central to the spirit of UD.
Tackling the Low-resource Challenge for Canonical Segmentation
Oct 06, 2020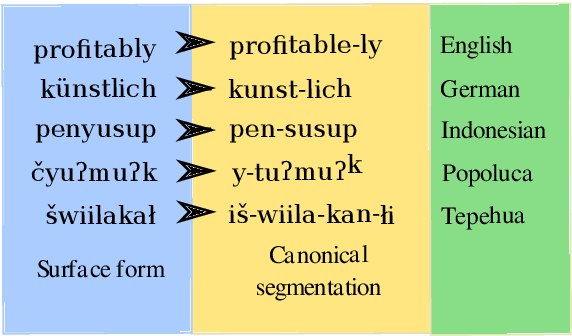
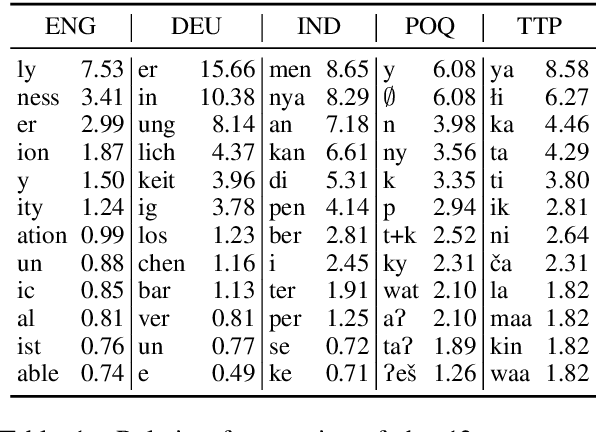
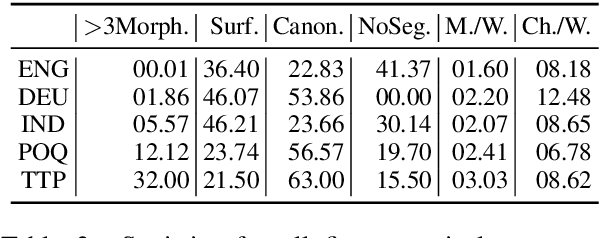
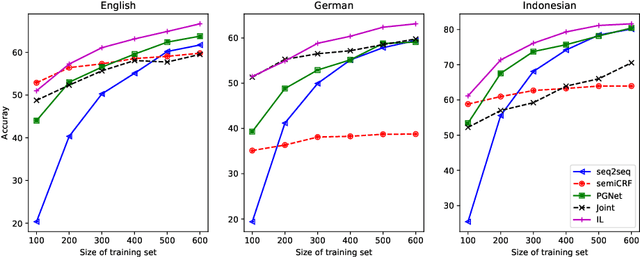
Canonical morphological segmentation consists of dividing words into their standardized morphemes. Here, we are interested in approaches for the task when training data is limited. We compare model performance in a simulated low-resource setting for the high-resource languages German, English, and Indonesian to experiments on new datasets for the truly low-resource languages Popoluca and Tepehua. We explore two new models for the task, borrowing from the closely related area of morphological generation: an LSTM pointer-generator and a sequence-to-sequence model with hard monotonic attention trained with imitation learning. We find that, in the low-resource setting, the novel approaches outperform existing ones on all languages by up to 11.4% accuracy. However, while accuracy in emulated low-resource scenarios is over 50% for all languages, for the truly low-resource languages Popoluca and Tepehua, our best model only obtains 37.4% and 28.4% accuracy, respectively. Thus, we conclude that canonical segmentation is still a challenging task for low-resource languages.
Lexical Normalization for Code-switched Data and its Effect on POS-tagging
Jun 01, 2020



Social media provides an unfiltered stream of user-generated input, leading to creative language use and many interesting linguistic phenomena, which were previously not available so abundantly. However, this language is harder to process automatically. One particularly challenging phenomenon is the use of multiple languages within one utterance, also called Code-Switching (CS). Whereas monolingual social media data already provides many problems for natural language processing, CS adds another challenging dimension. One solution that is commonly used to improve processing of social media data is to translate input texts to standard language first. This normalization has shown to improve performance of many natural language processing tasks. In this paper, we focus on normalization in the context of code-switching. We introduce a variety of models to perform normalization on CS data, and analyse the impact of word-level language identification on normalization. We show that the performance of the proposed normalization models is generally high, but language labels are only slightly informative. We also carry out POS tagging as extrinsic evaluation and show that automatic normalization of the input leads to 3.2% absolute performance increase, whereas gold normalization leads to an increase of 6.8%.
Subword-Level Language Identification for Intra-Word Code-Switching
Apr 03, 2019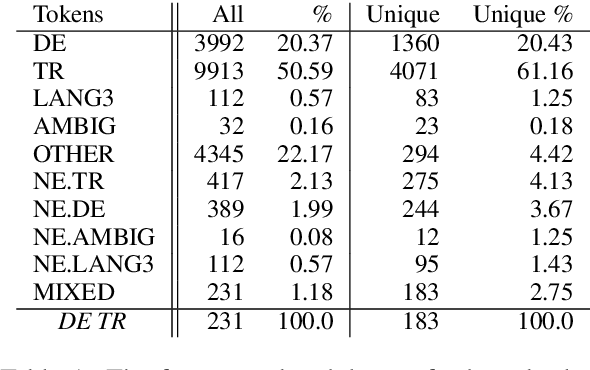

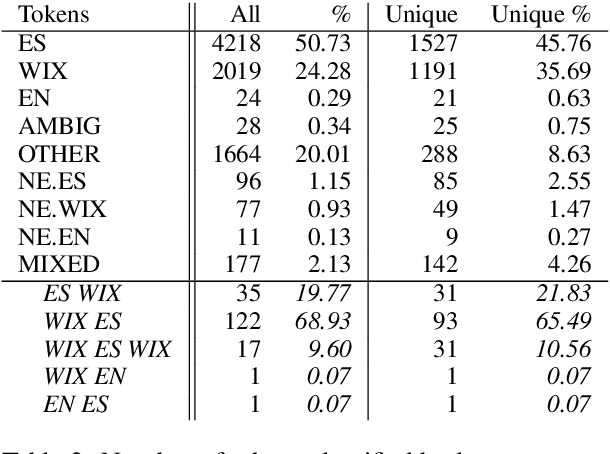
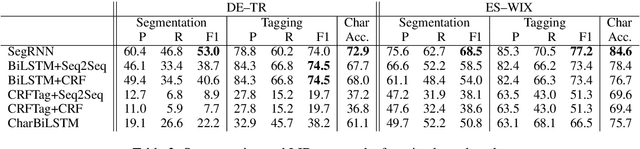
Language identification for code-switching (CS), the phenomenon of alternating between two or more languages in conversations, has traditionally been approached under the assumption of a single language per token. However, if at least one language is morphologically rich, a large number of words can be composed of morphemes from more than one language (intra-word CS). In this paper, we extend the language identification task to the subword-level, such that it includes splitting mixed words while tagging each part with a language ID. We further propose a model for this task, which is based on a segmental recurrent neural network. In experiments on a new Spanish--Wixarika dataset and on an adapted German--Turkish dataset, our proposed model performs slightly better than or roughly on par with our best baseline, respectively. Considering only mixed words, however, it strongly outperforms all baselines.
Challenges of Computational Processing of Code-Switching
Oct 07, 2016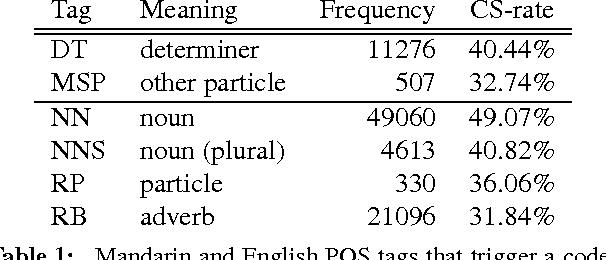
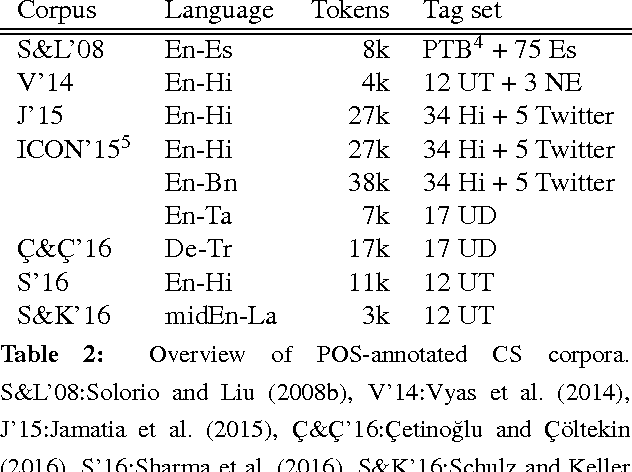
This paper addresses challenges of Natural Language Processing (NLP) on non-canonical multilingual data in which two or more languages are mixed. It refers to code-switching which has become more popular in our daily life and therefore obtains an increasing amount of attention from the research community. We report our experience that cov- ers not only core NLP tasks such as normalisation, language identification, language modelling, part-of-speech tagging and dependency parsing but also more downstream ones such as machine translation and automatic speech recognition. We highlight and discuss the key problems for each of the tasks with supporting examples from different language pairs and relevant previous work.