 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerm-Centric Hierarchy Induction from Heterogeneous Corpora
Jun 25, 2026Organizing knowledge from diverse text sources into interpretable hierarchies is crucial for tasks such as policy analysis, innovation monitoring, and exploratory domain mapping. Existing taxonomy induction methods typically rely on document-level representations that capture entire documents rather than the specific domain concepts relevant for knowledge organization, limiting their ability to generalize across heterogeneous sources. We propose a term-centric framework for inducing hierarchical taxonomies from heterogeneous corpora that scales to massive document collections. Our approach maps documents from diverse sources into a shared representation space using automatic term extraction, enabling robust cross-source alignment. Based on these representations, we construct interpretable hierarchies that integrate domain priors with datadriven clustering. Experiments on a novel English and German multi-source benchmark of over one million documents demonstrate that our method improves cross-source coherence and hierarchy quality over text- and summarybased baselines. A case study on German regional innovation analysis further demonstrates its practical utility for technology landscape mapping.
Dataset Diversity Metrics and Impact on Classification Models
Mar 16, 2026The diversity of training datasets is usually perceived as an important aspect to obtain a robust model. However, the definition of diversity is often not defined or differs across papers, and while some metrics exist, the quantification of this diversity is often overlooked when developing new algorithms. In this work, we study the behaviour of multiple dataset diversity metrics for image, text and metadata using MorphoMNIST, a toy dataset with controlled perturbations, and PadChest, a publicly available chest X-ray dataset. We evaluate whether these metrics correlate with each other but also with the intuition of a clinical expert. We also assess whether they correlate with downstream-task performance and how they impact the training dynamic of the models. We find limited correlations between the AUC and image or metadata reference-free diversity metrics, but higher correlations with the FID and the semantic diversity metrics. Finally, the clinical expert indicates that scanners are the main source of diversity in practice. However, we find that the addition of another scanner to the training set leads to shortcut learning. The code used in this study is available at https://github.com/TheoSourget/dataset_diversity_evaluation
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Do Syntactic Categories Help in Developmentally Motivated Curriculum Learning for Language Models?
Nov 11, 2025We examine the syntactic properties of BabyLM corpus, and age-groups within CHILDES. While we find that CHILDES does not exhibit strong syntactic differentiation by age, we show that the syntactic knowledge about the training data can be helpful in interpreting model performance on linguistic tasks. For curriculum learning, we explore developmental and several alternative cognitively inspired curriculum approaches. We find that some curricula help with reading tasks, but the main performance improvement come from using the subset of syntactically categorizable data, rather than the full noisy corpus.
NLPnorth @ TalentCLEF 2025: Comparing Discriminative, Contrastive, and Prompt-Based Methods for Job Title and Skill Matching
Jun 23, 2025Matching job titles is a highly relevant task in the computational job market domain, as it improves e.g., automatic candidate matching, career path prediction, and job market analysis. Furthermore, aligning job titles to job skills can be considered an extension to this task, with similar relevance for the same downstream tasks. In this report, we outline NLPnorth's submission to TalentCLEF 2025, which includes both of these tasks: Multilingual Job Title Matching, and Job Title-Based Skill Prediction. For both tasks we compare (fine-tuned) classification-based, (fine-tuned) contrastive-based, and prompting methods. We observe that for Task A, our prompting approach performs best with an average of 0.492 mean average precision (MAP) on test data, averaged over English, Spanish, and German. For Task B, we obtain an MAP of 0.290 on test data with our fine-tuned classification-based approach. Additionally, we made use of extra data by pulling all the language-specific titles and corresponding \emph{descriptions} from ESCO for each job and skill. Overall, we find that the largest multilingual language models perform best for both tasks. Per the provisional results and only counting the unique teams, the ranking on Task A is 5$^{\text{th}}$/20 and for Task B 3$^{\text{rd}}$/14.
DaKultur: Evaluating the Cultural Awareness of Language Models for Danish with Native Speakers
Apr 03, 2025Large Language Models (LLMs) have seen widespread societal adoption. However, while they are able to interact with users in languages beyond English, they have been shown to lack cultural awareness, providing anglocentric or inappropriate responses for underrepresented language communities. To investigate this gap and disentangle linguistic versus cultural proficiency, we conduct the first cultural evaluation study for the mid-resource language of Danish, in which native speakers prompt different models to solve tasks requiring cultural awareness. Our analysis of the resulting 1,038 interactions from 63 demographically diverse participants highlights open challenges to cultural adaptation: Particularly, how currently employed automatically translated data are insufficient to train or measure cultural adaptation, and how training on native-speaker data can more than double response acceptance rates. We release our study data as DaKultur - the first native Danish cultural awareness dataset.
From Smør-re-brød to Subwords: Training LLMs on Danish, One Morpheme at a Time
Apr 02, 2025
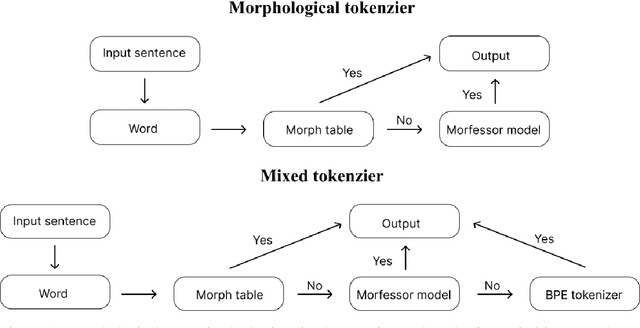

The best performing transformer-based language models use subword tokenization techniques, such as Byte-Pair-Encoding (BPE). However, these approaches often overlook linguistic principles, such as morphological segmentation, which we believe is fundamental for understanding language-specific word structure. In this study, we leverage an annotated Danish morphological dataset to train a semisupervised model for morphological segmentation, enabling the development of tokenizers optimized for Danish morphology. We evaluate four distinct tokenizers, including two custom morphological tokenizers, by analyzing their performance in morphologically segmenting Danish words. Additionally, we train two generative transformer models, \textit{CerebrasGPT-111M} and \textit{LLaMA-3.2 1B}, using these tokenizers and evaluate their downstream performance. Our findings reveal that our custom-developed tokenizers substantially enhance morphological segmentation, achieving an F1 score of 58.84, compared to 39.28 achieved by a Danish BPE tokenizer. In downstream tasks, models trained with our morphological tokenizers outperform those using BPE tokenizers across different evaluation metrics. These results highlight that incorporating Danish morphological segmentation strategies into tokenizers leads to improved performance in generative transformer models on Danish language
KARRIEREWEGE: A Large Scale Career Path Prediction Dataset
Dec 19, 2024Accurate career path prediction can support many stakeholders, like job seekers, recruiters, HR, and project managers. However, publicly available data and tools for career path prediction are scarce. In this work, we introduce KARRIEREWEGE, a comprehensive, publicly available dataset containing over 500k career paths, significantly surpassing the size of previously available datasets. We link the dataset to the ESCO taxonomy to offer a valuable resource for predicting career trajectories. To tackle the problem of free-text inputs typically found in resumes, we enhance it by synthesizing job titles and descriptions resulting in KARRIEREWEGE+. This allows for accurate predictions from unstructured data, closely aligning with real-world application challenges. We benchmark existing state-of-the-art (SOTA) models on our dataset and a prior benchmark and observe improved performance and robustness, particularly for free-text use cases, due to the synthesized data.
SnakModel: Lessons Learned from Training an Open Danish Large Language Model
Dec 17, 2024



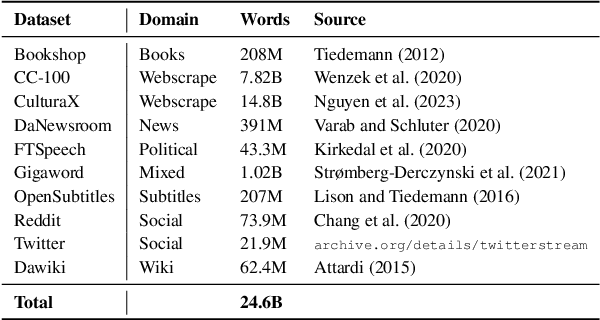
We present SnakModel, a Danish large language model (LLM) based on Llama2-7B, which we continuously pre-train on 13.6B Danish words, and further tune on 3.7M Danish instructions. As best practices for creating LLMs for smaller language communities have yet to be established, we examine the effects of early modeling and training decisions on downstream performance throughout the entire training pipeline, including (1) the creation of a strictly curated corpus of Danish text from diverse sources; (2) the language modeling and instruction-tuning training process itself, including the analysis of intermediate training dynamics, and ablations across different hyperparameters; (3) an evaluation on eight language and culturally-specific tasks. Across these experiments SnakModel achieves the highest overall performance, outperforming multiple contemporary Llama2-7B-based models. By making SnakModel, the majority of our pre-training corpus, and the associated code available under open licenses, we hope to foster further research and development in Danish Natural Language Processing, and establish training guidelines for languages with similar resource constraints.
data2lang2vec: Data Driven Typological Features Completion
Sep 25, 2024Language typology databases enhance multi-lingual Natural Language Processing (NLP) by improving model adaptability to diverse linguistic structures. The widely-used lang2vec toolkit integrates several such databases, but its coverage remains limited at 28.9\%. Previous work on automatically increasing coverage predicts missing values based on features from other languages or focuses on single features, we propose to use textual data for better-informed feature prediction. To this end, we introduce a multi-lingual Part-of-Speech (POS) tagger, achieving over 70\% accuracy across 1,749 languages, and experiment with external statistical features and a variety of machine learning algorithms. We also introduce a more realistic evaluation setup, focusing on likely to be missing typology features, and show that our approach outperforms previous work in both setups.