 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZEST: Zero-shot Embodied Skill Transfer for Athletic Robot Control
Jan 30, 2026Achieving robust, human-like whole-body control on humanoid robots for agile, contact-rich behaviors remains a central challenge, demanding heavy per-skill engineering and a brittle process of tuning controllers. We introduce ZEST (Zero-shot Embodied Skill Transfer), a streamlined motion-imitation framework that trains policies via reinforcement learning from diverse sources -- high-fidelity motion capture, noisy monocular video, and non-physics-constrained animation -- and deploys them to hardware zero-shot. ZEST generalizes across behaviors and platforms while avoiding contact labels, reference or observation windows, state estimators, and extensive reward shaping. Its training pipeline combines adaptive sampling, which focuses training on difficult motion segments, and an automatic curriculum using a model-based assistive wrench, together enabling dynamic, long-horizon maneuvers. We further provide a procedure for selecting joint-level gains from approximate analytical armature values for closed-chain actuators, along with a refined model of actuators. Trained entirely in simulation with moderate domain randomization, ZEST demonstrates remarkable generality. On Boston Dynamics' Atlas humanoid, ZEST learns dynamic, multi-contact skills (e.g., army crawl, breakdancing) from motion capture. It transfers expressive dance and scene-interaction skills, such as box-climbing, directly from videos to Atlas and the Unitree G1. Furthermore, it extends across morphologies to the Spot quadruped, enabling acrobatics, such as a continuous backflip, through animation. Together, these results demonstrate robust zero-shot deployment across heterogeneous data sources and embodiments, establishing ZEST as a scalable interface between biological movements and their robotic counterparts.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
NLPnorth @ TalentCLEF 2025: Comparing Discriminative, Contrastive, and Prompt-Based Methods for Job Title and Skill Matching
Jun 23, 2025Matching job titles is a highly relevant task in the computational job market domain, as it improves e.g., automatic candidate matching, career path prediction, and job market analysis. Furthermore, aligning job titles to job skills can be considered an extension to this task, with similar relevance for the same downstream tasks. In this report, we outline NLPnorth's submission to TalentCLEF 2025, which includes both of these tasks: Multilingual Job Title Matching, and Job Title-Based Skill Prediction. For both tasks we compare (fine-tuned) classification-based, (fine-tuned) contrastive-based, and prompting methods. We observe that for Task A, our prompting approach performs best with an average of 0.492 mean average precision (MAP) on test data, averaged over English, Spanish, and German. For Task B, we obtain an MAP of 0.290 on test data with our fine-tuned classification-based approach. Additionally, we made use of extra data by pulling all the language-specific titles and corresponding \emph{descriptions} from ESCO for each job and skill. Overall, we find that the largest multilingual language models perform best for both tasks. Per the provisional results and only counting the unique teams, the ranking on Task A is 5$^{\text{th}}$/20 and for Task B 3$^{\text{rd}}$/14.
Scaling Reasoning can Improve Factuality in Large Language Models
May 16, 2025Recent studies on large language model (LLM) reasoning capabilities have demonstrated promising improvements in model performance by leveraging a lengthy thinking process and additional computational resources during inference, primarily in tasks involving mathematical reasoning (Muennighoff et al., 2025). However, it remains uncertain if longer reasoning chains inherently enhance factual accuracy, particularly beyond mathematical contexts. In this work, we thoroughly examine LLM reasoning within complex open-domain question-answering (QA) scenarios. We initially distill reasoning traces from advanced, large-scale reasoning models (QwQ-32B and DeepSeek-R1-671B), then fine-tune a variety of models ranging from smaller, instruction-tuned variants to larger architectures based on Qwen2.5. To enrich reasoning traces, we introduce factual information from knowledge graphs in the form of paths into our reasoning traces. Our experimental setup includes four baseline approaches and six different instruction-tuned models evaluated across a benchmark of six datasets, encompassing over 22.6K questions. Overall, we carry out 168 experimental runs and analyze approximately 1.7 million reasoning traces. Our findings indicate that, within a single run, smaller reasoning models achieve noticeable improvements in factual accuracy compared to their original instruction-tuned counterparts. Moreover, our analysis demonstrates that adding test-time compute and token budgets factual accuracy consistently improves by 2-8%, further confirming the effectiveness of test-time scaling for enhancing performance and consequently improving reasoning accuracy in open-domain QA tasks. We release all the experimental artifacts for further research.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
DaKultur: Evaluating the Cultural Awareness of Language Models for Danish with Native Speakers
Apr 03, 2025Large Language Models (LLMs) have seen widespread societal adoption. However, while they are able to interact with users in languages beyond English, they have been shown to lack cultural awareness, providing anglocentric or inappropriate responses for underrepresented language communities. To investigate this gap and disentangle linguistic versus cultural proficiency, we conduct the first cultural evaluation study for the mid-resource language of Danish, in which native speakers prompt different models to solve tasks requiring cultural awareness. Our analysis of the resulting 1,038 interactions from 63 demographically diverse participants highlights open challenges to cultural adaptation: Particularly, how currently employed automatically translated data are insufficient to train or measure cultural adaptation, and how training on native-speaker data can more than double response acceptance rates. We release our study data as DaKultur - the first native Danish cultural awareness dataset.
How Do Hackathons Foster Creativity? Towards AI Collaborative Evaluation of Creativity at Scale
Mar 06, 2025Hackathons have become popular collaborative events for accelerating the development of creative ideas and prototypes. There are several case studies showcasing creative outcomes across domains such as industry, education, and research. However, there are no large-scale studies on creativity in hackathons which can advance theory on how hackathon formats lead to creative outcomes. We conducted a computational analysis of 193,353 hackathon projects. By operationalizing creativity through usefulness and novelty, we refined our dataset to 10,363 projects, allowing us to analyze how participant characteristics, collaboration patterns, and hackathon setups influence the development of creative projects. The contribution of our paper is twofold: We identified means for organizers to foster creativity in hackathons. We also explore the use of large language models (LLMs) to augment the evaluation of creative outcomes and discuss challenges and opportunities of doing this, which has implications for creativity research at large.
HiFi-KPI: A Dataset for Hierarchical KPI Extraction from Earnings Filings
Feb 21, 2025The U.S. Securities and Exchange Commission (SEC) requires that public companies file financial reports tagging numbers with the machine readable inline eXtensible Business Reporting Language (iXBRL) standard. However, the highly complex and highly granular taxonomy defined by iXBRL limits label transferability across domains. In this paper, we introduce the Hierarchical Financial Key Performance Indicator (HiFi-KPI) dataset, designed to facilitate numerical KPI extraction at specified levels of granularity from unstructured financial text. Our approach organizes a 218,126-label hierarchy using a taxonomy based grouping method, investigating which taxonomy layer provides the most meaningful structure. HiFi-KPI comprises ~1.8M paragraphs and ~5M entities, each linked to a label in the iXBRL-specific calculation and presentation taxonomies. We provide baselines using encoder-based approaches and structured extraction using Large Language Models (LLMs). To simplify LLM inference and evaluation, we additionally release HiFi-KPI Lite, a manually curated subset with four expert-mapped labels. We publicly release all artifacts
Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLMs
Feb 18, 2025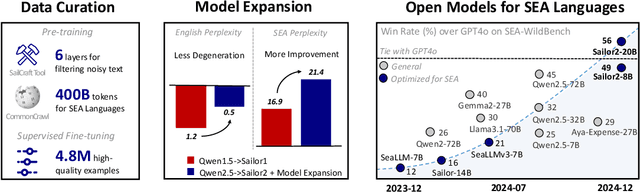
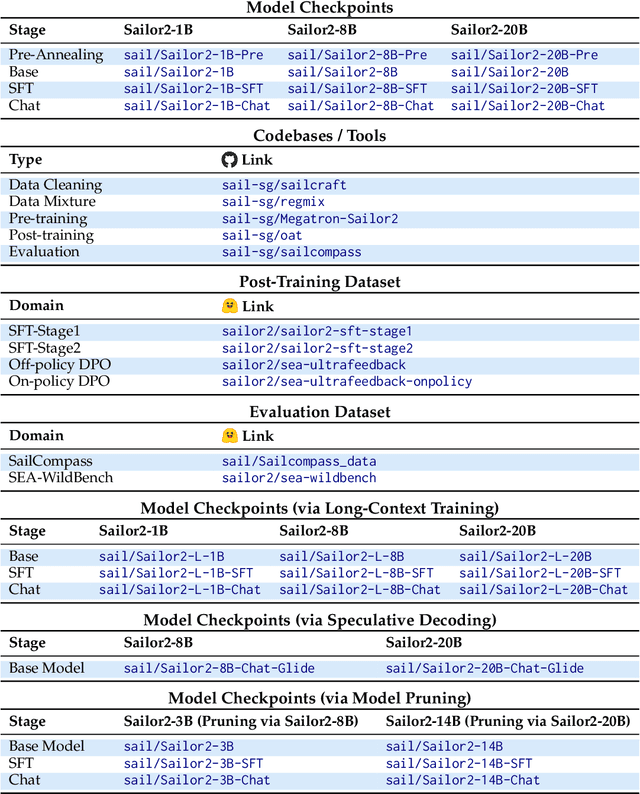

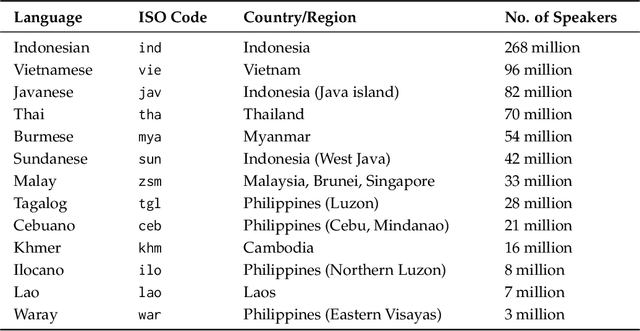
Sailor2 is a family of cutting-edge multilingual language models for South-East Asian (SEA) languages, available in 1B, 8B, and 20B sizes to suit diverse applications. Building on Qwen2.5, Sailor2 undergoes continuous pre-training on 500B tokens (400B SEA-specific and 100B replay tokens) to support 13 SEA languages while retaining proficiency in Chinese and English. Sailor2-20B model achieves a 50-50 win rate against GPT-4o across SEA languages. We also deliver a comprehensive cookbook on how to develop the multilingual model in an efficient manner, including five key aspects: data curation, pre-training, post-training, model customization and evaluation. We hope that Sailor2 model (Apache 2.0 license) will drive language development in the SEA region, and Sailor2 cookbook will inspire researchers to build more inclusive LLMs for other under-served languages.
SEFL: Harnessing Large Language Model Agents to Improve Educational Feedback Systems
Feb 18, 2025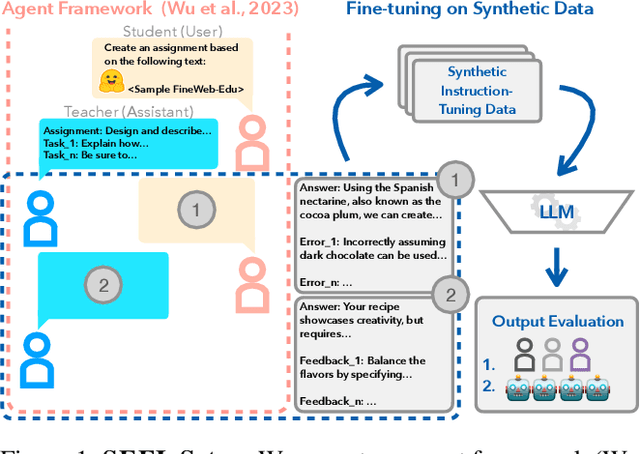

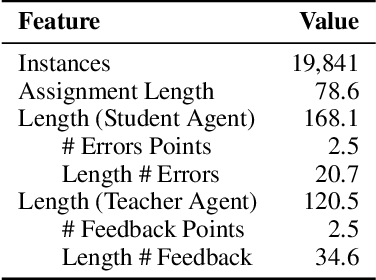
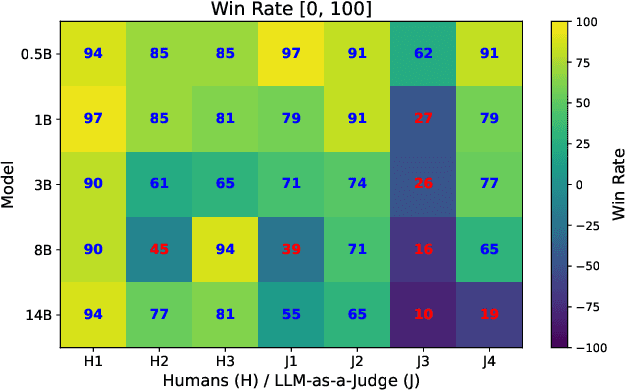
Providing high-quality feedback is crucial for student success but is constrained by time, cost, and limited data availability. We introduce Synthetic Educational Feedback Loops (SEFL), a novel framework designed to deliver immediate, on-demand feedback at scale without relying on extensive, real-world student data. In SEFL, two large language models (LLMs) operate in teacher--student roles to simulate assignment completion and formative feedback, generating abundant synthetic pairs of student work and corresponding critiques. We then fine-tune smaller, more computationally efficient LLMs on these synthetic pairs, enabling them to replicate key features of high-quality, goal-oriented feedback. Unlike personalized tutoring approaches that offer multi-turn, individualized instruction, SEFL specifically focuses on replicating the teacher-->student feedback loop for diverse assignments. Through both LLM-as-a-judge and human evaluations, we demonstrate that SEFL-tuned models outperform their non-tuned counterparts in feedback quality, clarity, and timeliness. These findings reveal SEFL's potential to transform feedback processes for higher education and beyond, offering an ethical and scalable alternative to conventional manual feedback cycles.