 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multilingual Divide and Its Impact on Global AI Safety
May 27, 2025Despite advances in large language model capabilities in recent years, a large gap remains in their capabilities and safety performance for many languages beyond a relatively small handful of globally dominant languages. This paper provides researchers, policymakers and governance experts with an overview of key challenges to bridging the "language gap" in AI and minimizing safety risks across languages. We provide an analysis of why the language gap in AI exists and grows, and how it creates disparities in global AI safety. We identify barriers to address these challenges, and recommend how those working in policy and governance can help address safety concerns associated with the language gap by supporting multilingual dataset creation, transparency, and research.
Aya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
The Leaderboard Illusion
Apr 29, 2025Measuring progress is fundamental to the advancement of any scientific field. As benchmarks play an increasingly central role, they also grow more susceptible to distortion. Chatbot Arena has emerged as the go-to leaderboard for ranking the most capable AI systems. Yet, in this work we identify systematic issues that have resulted in a distorted playing field. We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release and retract scores if desired. We establish that the ability of these providers to choose the best score leads to biased Arena scores due to selective disclosure of performance results. At an extreme, we identify 27 private LLM variants tested by Meta in the lead-up to the Llama-4 release. We also establish that proprietary closed models are sampled at higher rates (number of battles) and have fewer models removed from the arena than open-weight and open-source alternatives. Both these policies lead to large data access asymmetries over time. Providers like Google and OpenAI have received an estimated 19.2% and 20.4% of all data on the arena, respectively. In contrast, a combined 83 open-weight models have only received an estimated 29.7% of the total data. We show that access to Chatbot Arena data yields substantial benefits; even limited additional data can result in relative performance gains of up to 112% on the arena distribution, based on our conservative estimates. Together, these dynamics result in overfitting to Arena-specific dynamics rather than general model quality. The Arena builds on the substantial efforts of both the organizers and an open community that maintains this valuable evaluation platform. We offer actionable recommendations to reform the Chatbot Arena's evaluation framework and promote fairer, more transparent benchmarking for the field
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
Aya Expanse: Combining Research Breakthroughs for a New Multilingual Frontier
Dec 05, 2024



We introduce the Aya Expanse model family, a new generation of 8B and 32B parameter multilingual language models, aiming to address the critical challenge of developing highly performant multilingual models that match or surpass the capabilities of monolingual models. By leveraging several years of research at Cohere For AI and Cohere, including advancements in data arbitrage, multilingual preference training, and model merging, Aya Expanse sets a new state-of-the-art in multilingual performance. Our evaluations on the Arena-Hard-Auto dataset, translated into 23 languages, demonstrate that Aya Expanse 8B and 32B outperform leading open-weight models in their respective parameter classes, including Gemma 2, Qwen 2.5, and Llama 3.1, achieving up to a 76.6% win-rate. Notably, Aya Expanse 32B outperforms Llama 3.1 70B, a model with twice as many parameters, achieving a 54.0% win-rate. In this short technical report, we present extended evaluation results for the Aya Expanse model family and release their open-weights, together with a new multilingual evaluation dataset m-ArenaHard.
Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation
Dec 04, 2024



Cultural biases in multilingual datasets pose significant challenges for their effectiveness as global benchmarks. These biases stem not only from language but also from the cultural knowledge required to interpret questions, reducing the practical utility of translated datasets like MMLU. Furthermore, translation often introduces artifacts that can distort the meaning or clarity of questions in the target language. A common practice in multilingual evaluation is to rely on machine-translated evaluation sets, but simply translating a dataset is insufficient to address these challenges. In this work, we trace the impact of both of these issues on multilingual evaluations and ensuing model performances. Our large-scale evaluation of state-of-the-art open and proprietary models illustrates that progress on MMLU depends heavily on learning Western-centric concepts, with 28% of all questions requiring culturally sensitive knowledge. Moreover, for questions requiring geographic knowledge, an astounding 84.9% focus on either North American or European regions. Rankings of model evaluations change depending on whether they are evaluated on the full portion or the subset of questions annotated as culturally sensitive, showing the distortion to model rankings when blindly relying on translated MMLU. We release Global-MMLU, an improved MMLU with evaluation coverage across 42 languages -- with improved overall quality by engaging with compensated professional and community annotators to verify translation quality while also rigorously evaluating cultural biases present in the original dataset. This comprehensive Global-MMLU set also includes designated subsets labeled as culturally sensitive and culturally agnostic to allow for more holistic, complete evaluation.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model
Feb 12, 2024
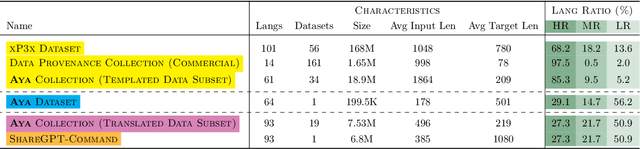
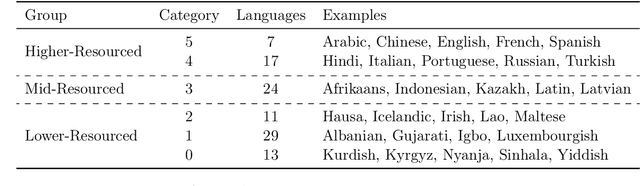

Recent breakthroughs in large language models (LLMs) have centered around a handful of data-rich languages. What does it take to broaden access to breakthroughs beyond first-class citizen languages? Our work introduces Aya, a massively multilingual generative language model that follows instructions in 101 languages of which over 50% are considered as lower-resourced. Aya outperforms mT0 and BLOOMZ on the majority of tasks while covering double the number of languages. We introduce extensive new evaluation suites that broaden the state-of-art for multilingual eval across 99 languages -- including discriminative and generative tasks, human evaluation, and simulated win rates that cover both held-out tasks and in-distribution performance. Furthermore, we conduct detailed investigations on the optimal finetuning mixture composition, data pruning, as well as the toxicity, bias, and safety of our models. We open-source our instruction datasets and our model at https://hf.co/CohereForAI/aya-101
Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning
Feb 09, 2024
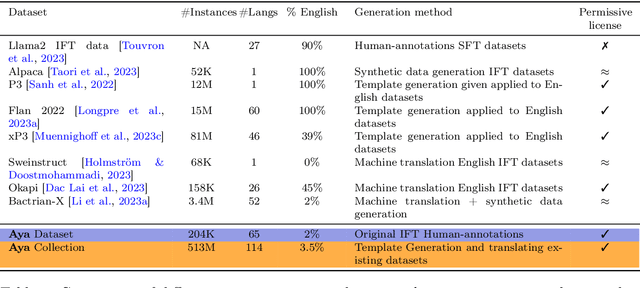
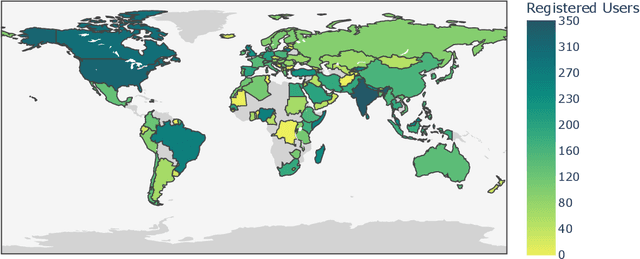
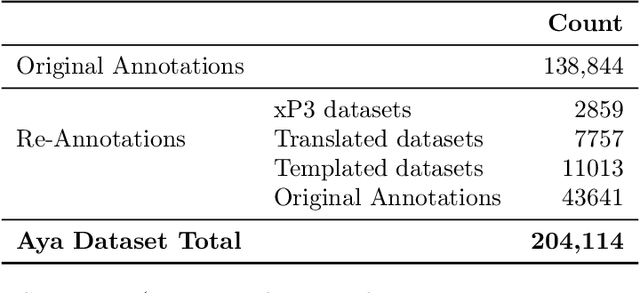
Datasets are foundational to many breakthroughs in modern artificial intelligence. Many recent achievements in the space of natural language processing (NLP) can be attributed to the finetuning of pre-trained models on a diverse set of tasks that enables a large language model (LLM) to respond to instructions. Instruction fine-tuning (IFT) requires specifically constructed and annotated datasets. However, existing datasets are almost all in the English language. In this work, our primary goal is to bridge the language gap by building a human-curated instruction-following dataset spanning 65 languages. We worked with fluent speakers of languages from around the world to collect natural instances of instructions and completions. Furthermore, we create the most extensive multilingual collection to date, comprising 513 million instances through templating and translating existing datasets across 114 languages. In total, we contribute four key resources: we develop and open-source the Aya Annotation Platform, the Aya Dataset, the Aya Collection, and the Aya Evaluation Suite. The Aya initiative also serves as a valuable case study in participatory research, involving collaborators from 119 countries. We see this as a valuable framework for future research collaborations that aim to bridge gaps in resources.