 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking the Limits of Knowledge Propagation: How LLMs Fail at Multi-Step Reasoning with Conflicting Knowledge
Jan 21, 2026A common solution for mitigating outdated or incorrect information in Large Language Models (LLMs) is to provide updated facts in-context or through knowledge editing. However, these methods introduce knowledge conflicts when the knowledge update fails to overwrite the model's parametric knowledge, which propagate to faulty reasoning. Current benchmarks for this problem, however, largely focus only on single knowledge updates and fact recall without evaluating how these updates affect downstream reasoning. In this work, we introduce TRACK (Testing Reasoning Amid Conflicting Knowledge), a new benchmark for studying how LLMs propagate new knowledge through multi-step reasoning when it conflicts with the model's initial parametric knowledge. Spanning three reasoning-intensive scenarios (WIKI, CODE, and MATH), TRACK introduces multiple, realistic conflicts to mirror real-world complexity. Our results on TRACK reveal that providing updated facts to models for reasoning can worsen performance compared to providing no updated facts to a model, and that this performance degradation exacerbates as more updated facts are provided. We show this failure stems from both inability to faithfully integrate updated facts, but also flawed reasoning even when knowledge is integrated. TRACK provides a rigorous new benchmark to measure and guide future progress on propagating conflicting knowledge in multi-step reasoning.
GeoExplorer: Active Geo-localization with Curiosity-Driven Exploration
Jul 31, 2025Active Geo-localization (AGL) is the task of localizing a goal, represented in various modalities (e.g., aerial images, ground-level images, or text), within a predefined search area. Current methods approach AGL as a goal-reaching reinforcement learning (RL) problem with a distance-based reward. They localize the goal by implicitly learning to minimize the relative distance from it. However, when distance estimation becomes challenging or when encountering unseen targets and environments, the agent exhibits reduced robustness and generalization ability due to the less reliable exploration strategy learned during training. In this paper, we propose GeoExplorer, an AGL agent that incorporates curiosity-driven exploration through intrinsic rewards. Unlike distance-based rewards, our curiosity-driven reward is goal-agnostic, enabling robust, diverse, and contextually relevant exploration based on effective environment modeling. These capabilities have been proven through extensive experiments across four AGL benchmarks, demonstrating the effectiveness and generalization ability of GeoExplorer in diverse settings, particularly in localizing unfamiliar targets and environments.
PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning
Jul 08, 2025Long-context reasoning requires accurately identifying relevant information in extensive, noisy input contexts. Previous research shows that using test-time learning to encode context directly into model parameters can effectively enable reasoning over noisy information. However, meta-learning methods for enabling test-time learning are prohibitively memory-intensive, preventing their application to long context settings. In this work, we propose PERK (Parameter Efficient Reasoning over Knowledge), a scalable approach for learning to encode long input contexts using gradient updates to a lightweight model adapter at test time. Specifically, PERK employs two nested optimization loops in a meta-training phase. The inner loop rapidly encodes contexts into a low-rank adapter (LoRA) that serves as a parameter-efficient memory module for the base model. Concurrently, the outer loop learns to use the updated adapter to accurately recall and reason over relevant information from the encoded long context. Our evaluations on several long-context reasoning tasks show that PERK significantly outperforms the standard prompt-based long-context baseline, achieving average absolute performance gains of up to 90% for smaller models (GPT-2) and up to 27% for our largest evaluated model, Qwen-2.5-0.5B. In general, PERK is more robust to reasoning complexity, length extrapolation, and the locations of relevant information in contexts. Finally, we show that while PERK is memory-intensive during training, it scales more efficiently at inference time than prompt-based long-context inference.
Mixture of Cognitive Reasoners: Modular Reasoning with Brain-Like Specialization
Jun 16, 2025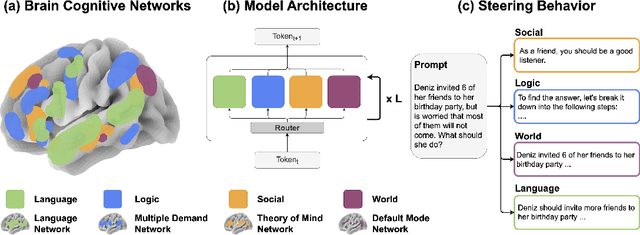
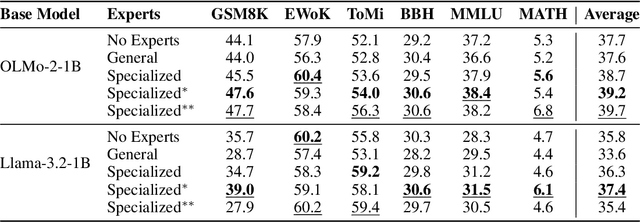
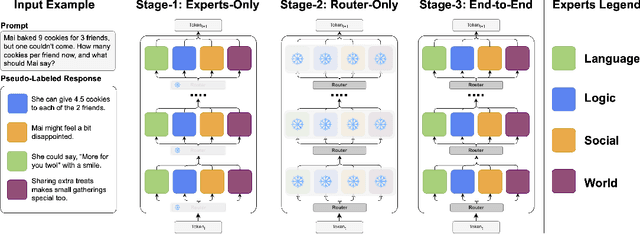
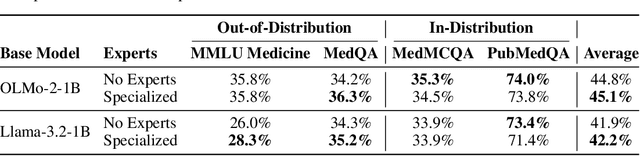
Human intelligence emerges from the interaction of specialized brain networks, each dedicated to distinct cognitive functions such as language processing, logical reasoning, social understanding, and memory retrieval. Inspired by this biological observation, we introduce the Mixture of Cognitive Reasoners (MiCRo) architecture and training paradigm: a modular transformer-based language model with a training curriculum that encourages the emergence of functional specialization among different modules. Inspired by studies in neuroscience, we partition the layers of a pretrained transformer model into four expert modules, each corresponding to a well-studied cognitive brain network. Our Brain-Like model has three key benefits over the state of the art: First, the specialized experts are highly interpretable and functionally critical, where removing a module significantly impairs performance on domain-relevant benchmarks. Second, our model outperforms comparable baselines that lack specialization on seven reasoning benchmarks. And third, the model's behavior can be steered at inference time by selectively emphasizing certain expert modules (e.g., favoring social over logical reasoning), enabling fine-grained control over the style of its response. Our findings suggest that biologically inspired inductive biases involved in human cognition lead to significant modeling gains in interpretability, performance, and controllability.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
V3Det Challenge 2024 on Vast Vocabulary and Open Vocabulary Object Detection: Methods and Results
Jun 17, 2024


Detecting objects in real-world scenes is a complex task due to various challenges, including the vast range of object categories, and potential encounters with previously unknown or unseen objects. The challenges necessitate the development of public benchmarks and challenges to advance the field of object detection. Inspired by the success of previous COCO and LVIS Challenges, we organize the V3Det Challenge 2024 in conjunction with the 4th Open World Vision Workshop: Visual Perception via Learning in an Open World (VPLOW) at CVPR 2024, Seattle, US. This challenge aims to push the boundaries of object detection research and encourage innovation in this field. The V3Det Challenge 2024 consists of two tracks: 1) Vast Vocabulary Object Detection: This track focuses on detecting objects from a large set of 13204 categories, testing the detection algorithm's ability to recognize and locate diverse objects. 2) Open Vocabulary Object Detection: This track goes a step further, requiring algorithms to detect objects from an open set of categories, including unknown objects. In the following sections, we will provide a comprehensive summary and analysis of the solutions submitted by participants. By analyzing the methods and solutions presented, we aim to inspire future research directions in vast vocabulary and open-vocabulary object detection, driving progress in this field. Challenge homepage: https://v3det.openxlab.org.cn/challenge
Complex Reasoning over Logical Queries on Commonsense Knowledge Graphs
Mar 12, 2024



Event commonsense reasoning requires the ability to reason about the relationship between events, as well as infer implicit context underlying that relationship. However, data scarcity makes it challenging for language models to learn to generate commonsense inferences for contexts and questions involving interactions between complex events. To address this demand, we present COM2 (COMplex COMmonsense), a new dataset created by sampling multi-hop logical queries (e.g., the joint effect or cause of both event A and B, or the effect of the effect of event C) from an existing commonsense knowledge graph (CSKG), and verbalizing them using handcrafted rules and large language models into multiple-choice and text generation questions. Our experiments show that language models trained on COM2 exhibit significant improvements in complex reasoning ability, resulting in enhanced zero-shot performance in both in-domain and out-of-domain tasks for question answering and generative commonsense reasoning, without expensive human annotations.
Mixed Pseudo Labels for Semi-Supervised Object Detection
Dec 12, 2023



While the pseudo-label method has demonstrated considerable success in semi-supervised object detection tasks, this paper uncovers notable limitations within this approach. Specifically, the pseudo-label method tends to amplify the inherent strengths of the detector while accentuating its weaknesses, which is manifested in the missed detection of pseudo-labels, particularly for small and tail category objects. To overcome these challenges, this paper proposes Mixed Pseudo Labels (MixPL), consisting of Mixup and Mosaic for pseudo-labeled data, to mitigate the negative impact of missed detections and balance the model's learning across different object scales. Additionally, the model's detection performance on tail categories is improved by resampling labeled data with relevant instances. Notably, MixPL consistently improves the performance of various detectors and obtains new state-of-the-art results with Faster R-CNN, FCOS, and DINO on COCO-Standard and COCO-Full benchmarks. Furthermore, MixPL also exhibits good scalability on large models, improving DINO Swin-L by 2.5% mAP and achieving nontrivial new records (60.2% mAP) on the COCO val2017 benchmark without extra annotations.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023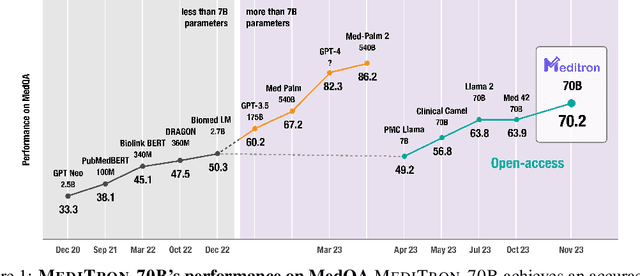
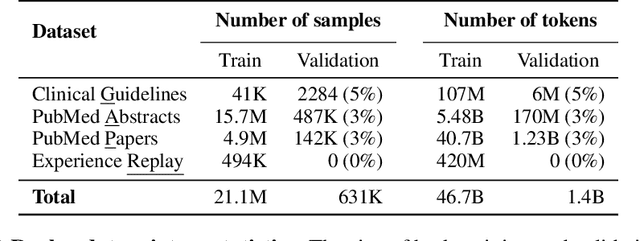
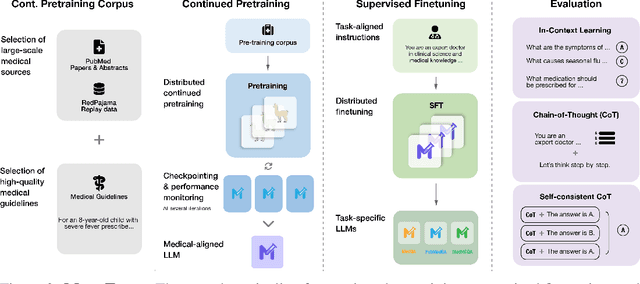

Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.