 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Cyclic Sparse Training: Is it Enough?
Jun 07, 2024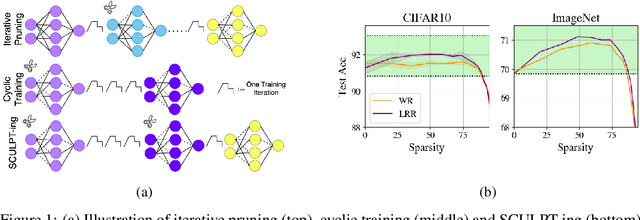

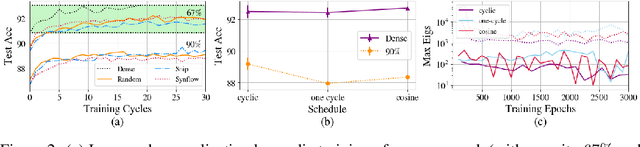

The success of iterative pruning methods in achieving state-of-the-art sparse networks has largely been attributed to improved mask identification and an implicit regularization induced by pruning. We challenge this hypothesis and instead posit that their repeated cyclic training schedules enable improved optimization. To verify this, we show that pruning at initialization is significantly boosted by repeated cyclic training, even outperforming standard iterative pruning methods. The dominant mechanism how this is achieved, as we conjecture, can be attributed to a better exploration of the loss landscape leading to a lower training loss. However, at high sparsity, repeated cyclic training alone is not enough for competitive performance. A strong coupling between learnt parameter initialization and mask seems to be required. Standard methods obtain this coupling via expensive pruning-training iterations, starting from a dense network. To achieve this with sparse training instead, we propose SCULPT-ing, i.e., repeated cyclic training of any sparse mask followed by a single pruning step to couple the parameters and the mask, which is able to match the performance of state-of-the-art iterative pruning methods in the high sparsity regime at reduced computational cost.
On The Fairness Impacts of Hardware Selection in Machine Learning
Dec 06, 2023



In the machine learning ecosystem, hardware selection is often regarded as a mere utility, overshadowed by the spotlight on algorithms and data. This oversight is particularly problematic in contexts like ML-as-a-service platforms, where users often lack control over the hardware used for model deployment. How does the choice of hardware impact generalization properties? This paper investigates the influence of hardware on the delicate balance between model performance and fairness. We demonstrate that hardware choices can exacerbate existing disparities, attributing these discrepancies to variations in gradient flows and loss surfaces across different demographic groups. Through both theoretical and empirical analysis, the paper not only identifies the underlying factors but also proposes an effective strategy for mitigating hardware-induced performance imbalances.
Accelerated CNN Training Through Gradient Approximation
Aug 15, 2019
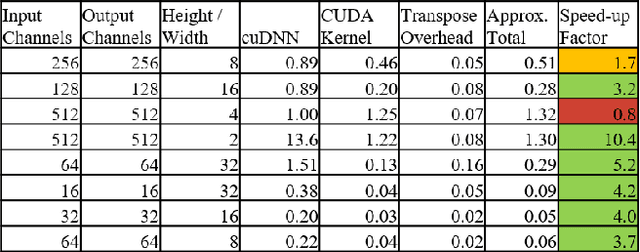


Training deep convolutional neural networks such as VGG and ResNet by gradient descent is an expensive exercise requiring specialized hardware such as GPUs. Recent works have examined the possibility of approximating the gradient computation while maintaining the same convergence properties. While promising, the approximations only work on relatively small datasets such as MNIST. They also fail to achieve real wall-clock speedups due to lack of efficient GPU implementations of the proposed approximation methods. In this work, we explore three alternative methods to approximate gradients, with an efficient GPU kernel implementation for one of them. We achieve wall-clock speedup with ResNet-20 and VGG-19 on the CIFAR-10 dataset upwards of 7%, with a minimal loss in validation accuracy.