 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyclic Sparse Training: Is it Enough?
Paper and Code
Jun 07, 2024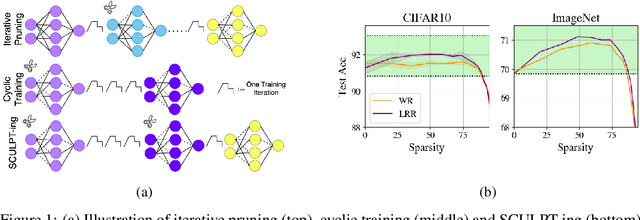

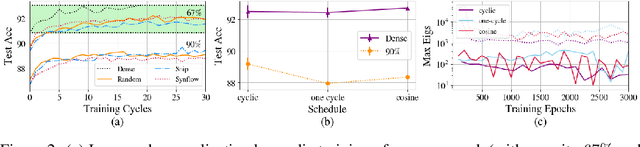

The success of iterative pruning methods in achieving state-of-the-art sparse networks has largely been attributed to improved mask identification and an implicit regularization induced by pruning. We challenge this hypothesis and instead posit that their repeated cyclic training schedules enable improved optimization. To verify this, we show that pruning at initialization is significantly boosted by repeated cyclic training, even outperforming standard iterative pruning methods. The dominant mechanism how this is achieved, as we conjecture, can be attributed to a better exploration of the loss landscape leading to a lower training loss. However, at high sparsity, repeated cyclic training alone is not enough for competitive performance. A strong coupling between learnt parameter initialization and mask seems to be required. Standard methods obtain this coupling via expensive pruning-training iterations, starting from a dense network. To achieve this with sparse training instead, we propose SCULPT-ing, i.e., repeated cyclic training of any sparse mask followed by a single pruning step to couple the parameters and the mask, which is able to match the performance of state-of-the-art iterative pruning methods in the high sparsity regime at reduced computational cost.