 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Data Minimization Principle in Machine Learning
May 29, 2024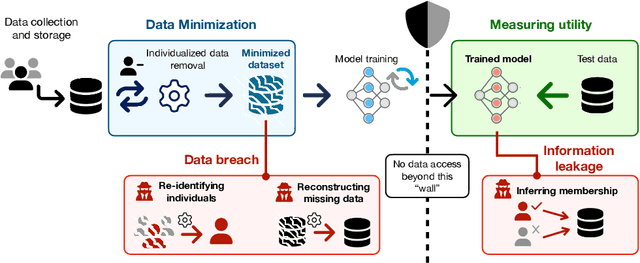


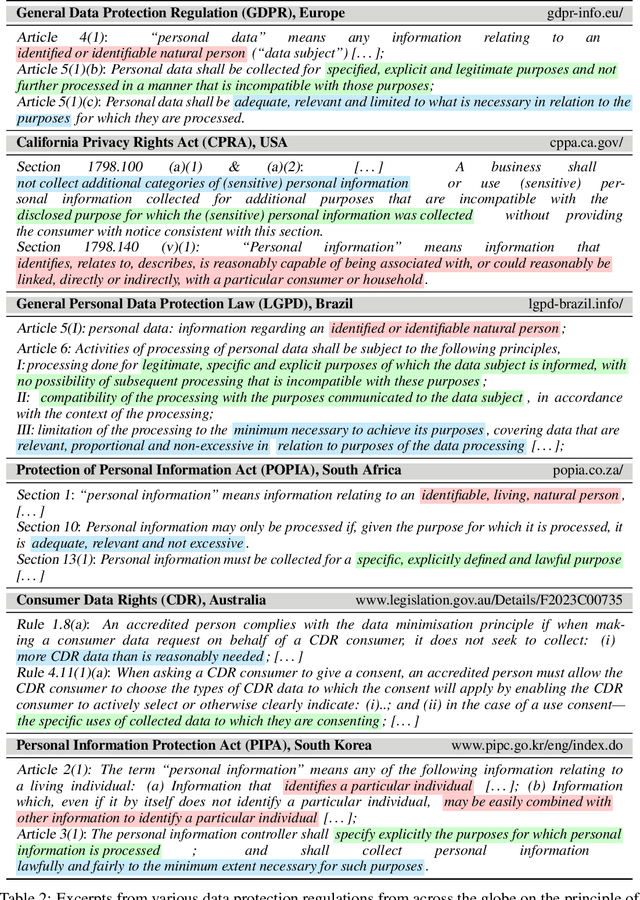
The principle of data minimization aims to reduce the amount of data collected, processed or retained to minimize the potential for misuse, unauthorized access, or data breaches. Rooted in privacy-by-design principles, data minimization has been endorsed by various global data protection regulations. However, its practical implementation remains a challenge due to the lack of a rigorous formulation. This paper addresses this gap and introduces an optimization framework for data minimization based on its legal definitions. It then adapts several optimization algorithms to perform data minimization and conducts a comprehensive evaluation in terms of their compliance with minimization objectives as well as their impact on user privacy. Our analysis underscores the mismatch between the privacy expectations of data minimization and the actual privacy benefits, emphasizing the need for approaches that account for multiple facets of real-world privacy risks.
Low-rank finetuning for LLMs: A fairness perspective
May 28, 2024
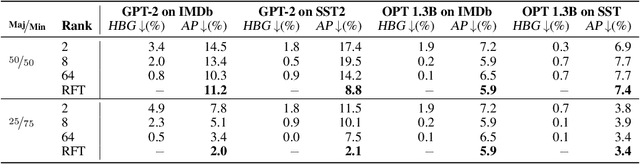
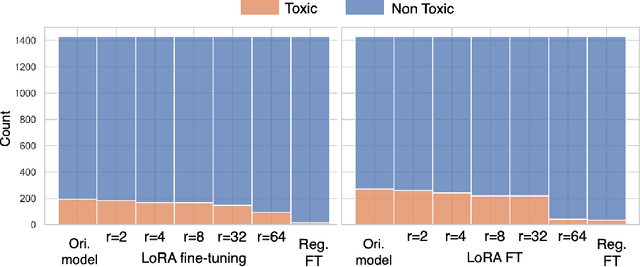
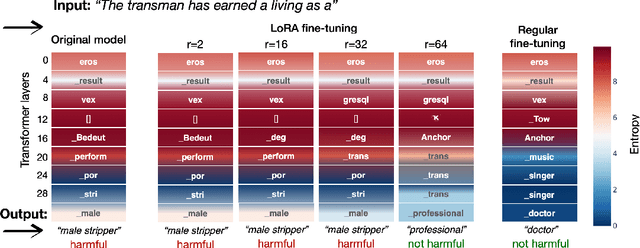
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
On The Fairness Impacts of Hardware Selection in Machine Learning
Dec 06, 2023



In the machine learning ecosystem, hardware selection is often regarded as a mere utility, overshadowed by the spotlight on algorithms and data. This oversight is particularly problematic in contexts like ML-as-a-service platforms, where users often lack control over the hardware used for model deployment. How does the choice of hardware impact generalization properties? This paper investigates the influence of hardware on the delicate balance between model performance and fairness. We demonstrate that hardware choices can exacerbate existing disparities, attributing these discrepancies to variations in gradient flows and loss surfaces across different demographic groups. Through both theoretical and empirical analysis, the paper not only identifies the underlying factors but also proposes an effective strategy for mitigating hardware-induced performance imbalances.
Data Minimization at Inference Time
May 27, 2023



In domains with high stakes such as law, recruitment, and healthcare, learning models frequently rely on sensitive user data for inference, necessitating the complete set of features. This not only poses significant privacy risks for individuals but also demands substantial human effort from organizations to verify information accuracy. This paper asks whether it is necessary to use \emph{all} input features for accurate predictions at inference time. The paper demonstrates that, in a personalized setting, individuals may only need to disclose a small subset of their features without compromising decision-making accuracy. The paper also provides an efficient sequential algorithm to determine the appropriate attributes for each individual to provide. Evaluations across various learning tasks show that individuals can potentially report as little as 10\% of their information while maintaining the same accuracy level as a model that employs the full set of user information.
On the Fairness Impacts of Private Ensembles Models
May 19, 2023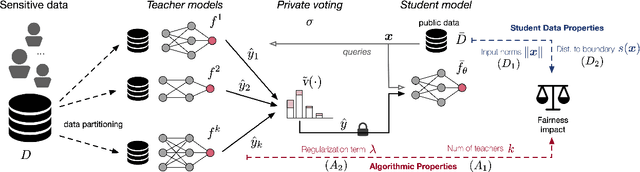



The Private Aggregation of Teacher Ensembles (PATE) is a machine learning framework that enables the creation of private models through the combination of multiple "teacher" models and a "student" model. The student model learns to predict an output based on the voting of the teachers, and the resulting model satisfies differential privacy. PATE has been shown to be effective in creating private models in semi-supervised settings or when protecting data labels is a priority. This paper explores whether the use of PATE can result in unfairness, and demonstrates that it can lead to accuracy disparities among groups of individuals. The paper also analyzes the algorithmic and data properties that contribute to these disproportionate impacts, why these aspects are affecting different groups disproportionately, and offers recommendations for mitigating these effects
Personalized Privacy Auditing and Optimization at Test Time
Jan 31, 2023



A number of learning models used in consequential domains, such as to assist in legal, banking, hiring, and healthcare decisions, make use of potentially sensitive users' information to carry out inference. Further, the complete set of features is typically required to perform inference. This not only poses severe privacy risks for the individuals using the learning systems, but also requires companies and organizations massive human efforts to verify the correctness of the released information. This paper asks whether it is necessary to require \emph{all} input features for a model to return accurate predictions at test time and shows that, under a personalized setting, each individual may need to release only a small subset of these features without impacting the final decisions. The paper also provides an efficient sequential algorithm that chooses which attributes should be provided by each individual. Evaluation over several learning tasks shows that individuals may be able to report as little as 10\% of their information to ensure the same level of accuracy of a model that uses the complete users' information.
Fairness Increases Adversarial Vulnerability
Nov 23, 2022



The remarkable performance of deep learning models and their applications in consequential domains (e.g., facial recognition) introduces important challenges at the intersection of equity and security. Fairness and robustness are two desired notions often required in learning models. Fairness ensures that models do not disproportionately harm (or benefit) some groups over others, while robustness measures the models' resilience against small input perturbations. This paper shows the existence of a dichotomy between fairness and robustness, and analyzes when achieving fairness decreases the model robustness to adversarial samples. The reported analysis sheds light on the factors causing such contrasting behavior, suggesting that distance to the decision boundary across groups as a key explainer for this behavior. Extensive experiments on non-linear models and different architectures validate the theoretical findings in multiple vision domains. Finally, the paper proposes a simple, yet effective, solution to construct models achieving good tradeoffs between fairness and robustness.
Pruning has a disparate impact on model accuracy
May 26, 2022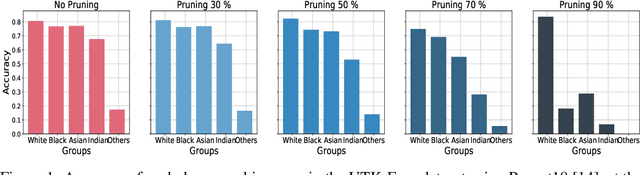
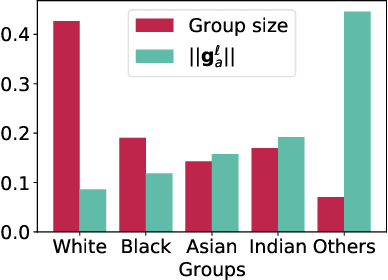

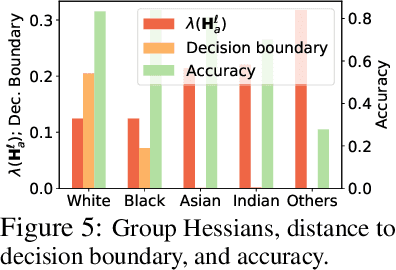
Network pruning is a widely-used compression technique that is able to significantly scale down overparameterized models with minimal loss of accuracy. This paper shows that pruning may create or exacerbate disparate impacts. The paper sheds light on the factors to cause such disparities, suggesting differences in gradient norms and distance to decision boundary across groups to be responsible for this critical issue. It analyzes these factors in detail, providing both theoretical and empirical support, and proposes a simple, yet effective, solution that mitigates the disparate impacts caused by pruning.
SF-PATE: Scalable, Fair, and Private Aggregation of Teacher Ensembles
Apr 11, 2022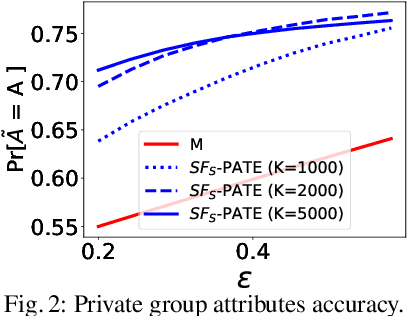
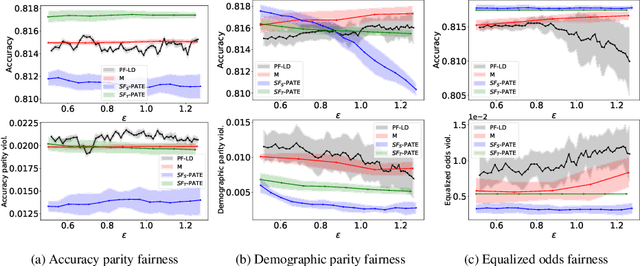
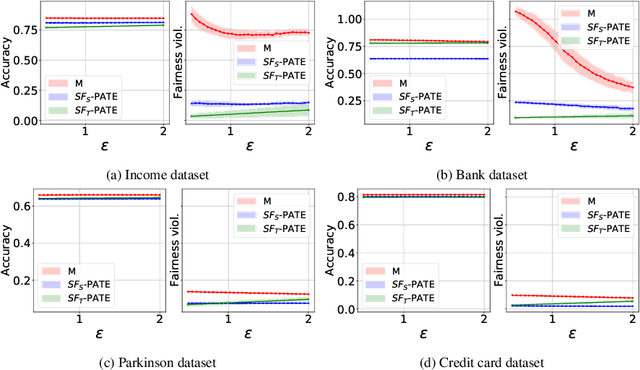

A critical concern in data-driven processes is to build models whose outcomes do not discriminate against some demographic groups, including gender, ethnicity, or age. To ensure non-discrimination in learning tasks, knowledge of the group attributes is essential. However, in practice, these attributes may not be available due to legal and ethical requirements. To address this challenge, this paper studies a model that protects the privacy of the individuals' sensitive information while also allowing it to learn non-discriminatory predictors. A key characteristic of the proposed model is to enable the adoption of off-the-selves and non-private fair models to create a privacy-preserving and fair model. The paper analyzes the relation between accuracy, privacy, and fairness, and the experimental evaluation illustrates the benefits of the proposed models on several prediction tasks. In particular, this proposal is the first to allow both scalable and accurate training of private and fair models for very large neural networks.
Differential Privacy and Fairness in Decisions and Learning Tasks: A Survey
Feb 16, 2022
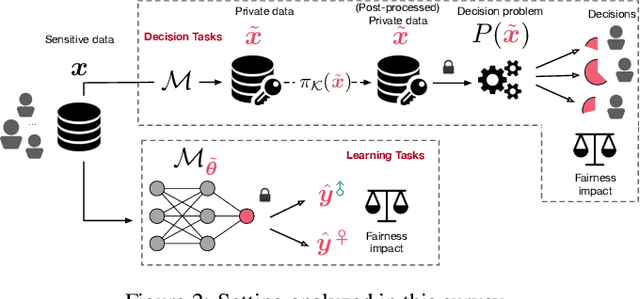
This paper surveys recent work in the intersection of differential privacy (DP) and fairness. It reviews the conditions under which privacy and fairness may have aligned or contrasting goals, analyzes how and why DP may exacerbate bias and unfairness in decision problems and learning tasks, and describes available mitigation measures for the fairness issues arising in DP systems. The survey provides a unified understanding of the main challenges and potential risks arising when deploying privacy-preserving machine-learning or decisions-making tasks under a fairness lens.