 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Social Laboratory: A Psychometric Framework for Multi-Agent LLM Evaluation
Oct 01, 2025As Large Language Models (LLMs) transition from static tools to autonomous agents, traditional evaluation benchmarks that measure performance on downstream tasks are becoming insufficient. These methods fail to capture the emergent social and cognitive dynamics that arise when agents communicate, persuade, and collaborate in interactive environments. To address this gap, we introduce a novel evaluation framework that uses multi-agent debate as a controlled "social laboratory" to discover and quantify these behaviors. In our framework, LLM-based agents, instantiated with distinct personas and incentives, deliberate on a wide range of challenging topics under the supervision of an LLM moderator. Our analysis, enabled by a new suite of psychometric and semantic metrics, reveals several key findings. Across hundreds of debates, we uncover a powerful and robust emergent tendency for agents to seek consensus, consistently reaching high semantic agreement ({\mu} > 0.88) even without explicit instruction and across sensitive topics. We show that assigned personas induce stable, measurable psychometric profiles, particularly in cognitive effort, and that the moderators persona can significantly alter debate outcomes by structuring the environment, a key finding for external AI alignment. This work provides a blueprint for a new class of dynamic, psychometrically grounded evaluation protocols designed for the agentic setting, offering a crucial methodology for understanding and shaping the social behaviors of the next generation of AI agents. We have released the code and results at https://github.com/znreza/multi-agent-LLM-eval-for-debate.
Small Models, Big Support: A Local LLM Framework for Teacher-Centric Content Creation and Assessment using RAG and CAG
Jun 06, 2025While Large Language Models (LLMs) are increasingly utilized as student-facing educational aids, their potential to directly support educators, particularly through locally deployable and customizable open-source solutions, remains significantly underexplored. Many existing educational solutions rely on cloud-based infrastructure or proprietary tools, which are costly and may raise privacy concerns. Regulated industries with limited budgets require affordable, self-hosted solutions. We introduce an end-to-end, open-source framework leveraging small (3B-7B parameters), locally deployed LLMs for customized teaching material generation and assessment. Our system uniquely incorporates an interactive loop crucial for effective small-model refinement, and an auxiliary LLM verifier to mitigate jailbreaking risks, enhancing output reliability and safety. Utilizing Retrieval and Context Augmented Generation (RAG/CAG), it produces factually accurate, customized pedagogically-styled content. Deployed on-premises for data privacy and validated through an evaluation pipeline and a college physics pilot, our findings show that carefully engineered small LLM systems can offer robust, affordable, practical, and safe educator support, achieving utility comparable to larger models for targeted tasks.
Low-rank finetuning for LLMs: A fairness perspective
May 28, 2024
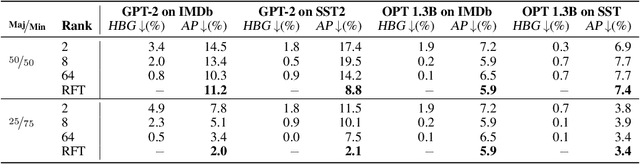
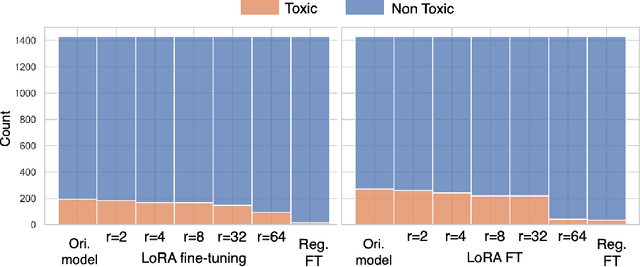
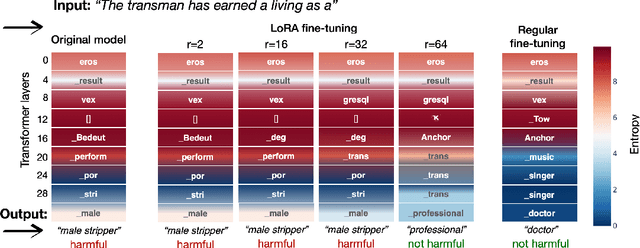
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.