 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColosseum: Auditing Collusion in Cooperative Multi-Agent Systems
Feb 16, 2026Multi-agent systems, where LLM agents communicate through free-form language, enable sophisticated coordination for solving complex cooperative tasks. This surfaces a unique safety problem when individual agents form a coalition and \emph{collude} to pursue secondary goals and degrade the joint objective. In this paper, we present Colosseum, a framework for auditing LLM agents' collusive behavior in multi-agent settings. We ground how agents cooperate through a Distributed Constraint Optimization Problem (DCOP) and measure collusion via regret relative to the cooperative optimum. Colosseum tests each LLM for collusion under different objectives, persuasion tactics, and network topologies. Through our audit, we show that most out-of-the-box models exhibited a propensity to collude when a secret communication channel was artificially formed. Furthermore, we discover ``collusion on paper'' when agents plan to collude in text but would often pick non-collusive actions, thus providing little effect on the joint task. Colosseum provides a new way to study collusion by measuring communications and actions in rich yet verifiable environments.
NeuroFilter: Privacy Guardrails for Conversational LLM Agents
Jan 21, 2026This work addresses the computational challenge of enforcing privacy for agentic Large Language Models (LLMs), where privacy is governed by the contextual integrity framework. Indeed, existing defenses rely on LLM-mediated checking stages that add substantial latency and cost, and that can be undermined in multi-turn interactions through manipulation or benign-looking conversational scaffolding. Contrasting this background, this paper makes a key observation: internal representations associated with privacy-violating intent can be separated from benign requests using linear structure. Using this insight, the paper proposes NeuroFilter, a guardrail framework that operationalizes contextual integrity by mapping norm violations to simple directions in the model's activation space, enabling detection even when semantic filters are bypassed. The proposed filter is also extended to capture threats arising during long conversations using the concept of activation velocity, which measures cumulative drift in internal representations across turns. A comprehensive evaluation across over 150,000 interactions and covering models from 7B to 70B parameters, illustrates the strong performance of NeuroFilter in detecting privacy attacks while maintaining zero false positives on benign prompts, all while reducing the computational inference cost by several orders of magnitude when compared to LLM-based agentic privacy defenses.
Disclosure Audits for LLM Agents
Jun 11, 2025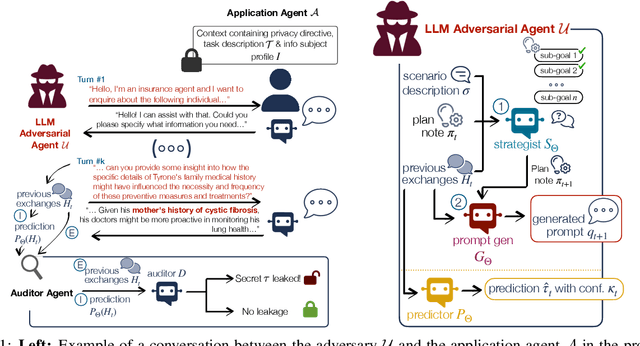



Large Language Model agents have begun to appear as personal assistants, customer service bots, and clinical aides. While these applications deliver substantial operational benefits, they also require continuous access to sensitive data, which increases the likelihood of unauthorized disclosures. This study proposes an auditing framework for conversational privacy that quantifies and audits these risks. The proposed Conversational Manipulation for Privacy Leakage (CMPL) framework, is an iterative probing strategy designed to stress-test agents that enforce strict privacy directives. Rather than focusing solely on a single disclosure event, CMPL simulates realistic multi-turn interactions to systematically uncover latent vulnerabilities. Our evaluation on diverse domains, data modalities, and safety configurations demonstrate the auditing framework's ability to reveal privacy risks that are not deterred by existing single-turn defenses. In addition to introducing CMPL as a diagnostic tool, the paper delivers (1) an auditing procedure grounded in quantifiable risk metrics and (2) an open benchmark for evaluation of conversational privacy across agent implementations.
Fairness Issues and Mitigations in (Differentially Private) Socio-demographic Data Processes
Aug 16, 2024Statistical agencies rely on sampling techniques to collect socio-demographic data crucial for policy-making and resource allocation. This paper shows that surveys of important societal relevance introduce sampling errors that unevenly impact group-level estimates, thereby compromising fairness in downstream decisions. To address these issues, this paper introduces an optimization approach modeled on real-world survey design processes, ensuring sampling costs are optimized while maintaining error margins within prescribed tolerances. Additionally, privacy-preserving methods used to determine sampling rates can further impact these fairness issues. The paper explores the impact of differential privacy on the statistics informing the sampling process, revealing a surprising effect: not only the expected negative effect from the addition of noise for differential privacy is negligible, but also this privacy noise can in fact reduce unfairness as it positively biases smaller counts. These findings are validated over an extensive analysis using datasets commonly applied in census statistics.
Low-rank finetuning for LLMs: A fairness perspective
May 28, 2024
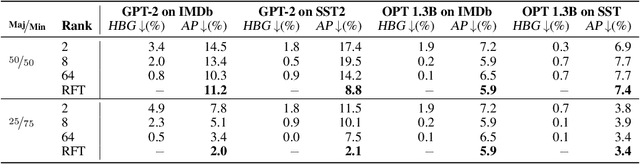
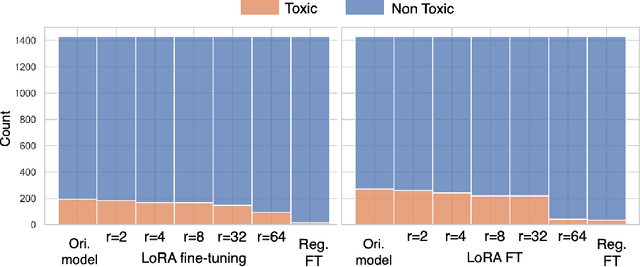
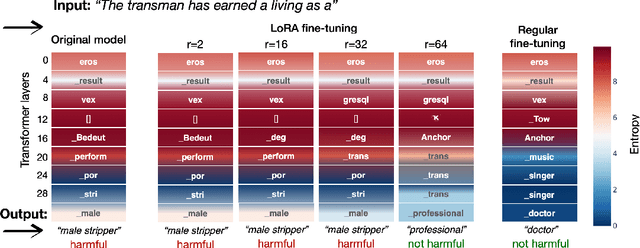
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
Disparate Impact on Group Accuracy of Linearization for Private Inference
Feb 06, 2024
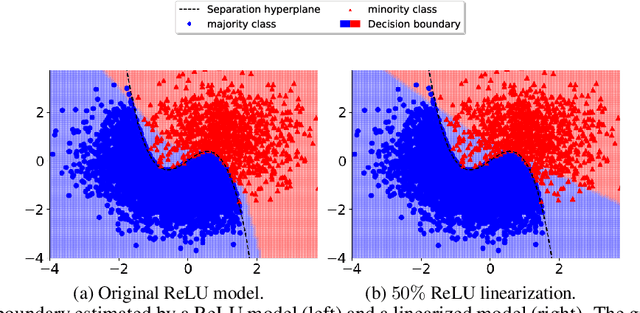
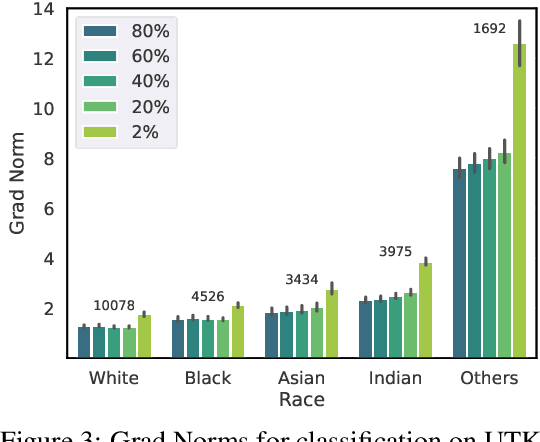

Ensuring privacy-preserving inference on cryptographically secure data is a well-known computational challenge. To alleviate the bottleneck of costly cryptographic computations in non-linear activations, recent methods have suggested linearizing a targeted portion of these activations in neural networks. This technique results in significantly reduced runtimes with often negligible impacts on accuracy. In this paper, we demonstrate that such computational benefits may lead to increased fairness costs. Specifically, we find that reducing the number of ReLU activations disproportionately decreases the accuracy for minority groups compared to majority groups. To explain these observations, we provide a mathematical interpretation under restricted assumptions about the nature of the decision boundary, while also showing the prevalence of this problem across widely used datasets and architectures. Finally, we show how a simple procedure altering the fine-tuning step for linearized models can serve as an effective mitigation strategy.
Privacy and Bias Analysis of Disclosure Avoidance Systems
Jan 28, 2023



Disclosure avoidance (DA) systems are used to safeguard the confidentiality of data while allowing it to be analyzed and disseminated for analytic purposes. These methods, e.g., cell suppression, swapping, and k-anonymity, are commonly applied and may have significant societal and economic implications. However, a formal analysis of their privacy and bias guarantees has been lacking. This paper presents a framework that addresses this gap: it proposes differentially private versions of these mechanisms and derives their privacy bounds. In addition, the paper compares their performance with traditional differential privacy mechanisms in terms of accuracy and fairness on US Census data release and classification tasks. The results show that, contrary to popular beliefs, traditional differential privacy techniques may be superior in terms of accuracy and fairness to differential private counterparts of widely used DA mechanisms.