 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Community Data for Benchmarking Data Privacy Algorithms
Jun 20, 2023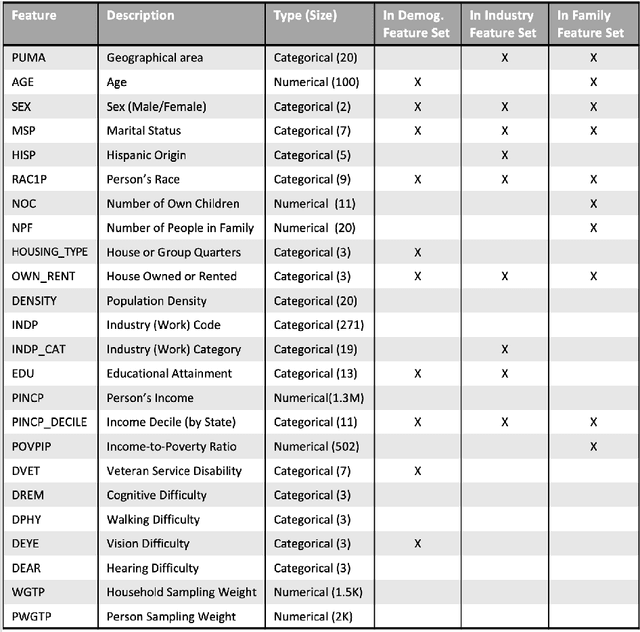



The Diverse Communities Data Excerpts are the core of a National Institute of Standards and Technology (NIST) program to strengthen understanding of tabular data deidentification technologies such as synthetic data. Synthetic data is an ambitious attempt to democratize the benefits of big data; it uses generative models to recreate sensitive personal data with new records for public release. However, it is vulnerable to the same bias and privacy issues that impact other machine learning applications, and can even amplify those issues. When deidentified data distributions introduce bias or artifacts, or leak sensitive information, they propagate these problems to downstream applications. Furthermore, real-world survey conditions such as diverse subpopulations, heterogeneous non-ordinal data spaces, and complex dependencies between features pose specific challenges for synthetic data algorithms. These observations motivate the need for real, diverse, and complex benchmark data to support a robust understanding of algorithm behavior. This paper introduces four contributions: new theoretical work on the relationship between diverse populations and challenges for equitable deidentification; public benchmark data focused on diverse populations and challenging features curated from the American Community Survey; an open source suite of evaluation metrology for deidentified datasets; and an archive of evaluation results on a broad collection of deidentification techniques. The initial set of evaluation results demonstrate the suitability of these tools for investigations in this field.
Toward Defining a Domain Complexity Measure Across Domains
Mar 07, 2023
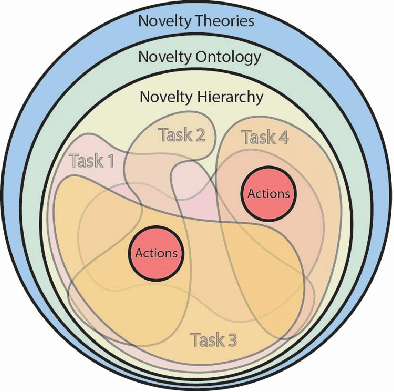


Artificial Intelligence (AI) systems planned for deployment in real-world applications frequently are researched and developed in closed simulation environments where all variables are controlled and known to the simulator or labeled benchmark datasets are used. Transition from these simulators, testbeds, and benchmark datasets to more open-world domains poses significant challenges to AI systems, including significant increases in the complexity of the domain and the inclusion of real-world novelties; the open-world environment contains numerous out-of-distribution elements that are not part in the AI systems' training set. Here, we propose a path to a general, domain-independent measure of domain complexity level. We distinguish two aspects of domain complexity: intrinsic and extrinsic. The intrinsic domain complexity is the complexity that exists by itself without any action or interaction from an AI agent performing a task on that domain. This is an agent-independent aspect of the domain complexity. The extrinsic domain complexity is agent- and task-dependent. Intrinsic and extrinsic elements combined capture the overall complexity of the domain. We frame the components that define and impact domain complexity levels in a domain-independent light. Domain-independent measures of complexity could enable quantitative predictions of the difficulty posed to AI systems when transitioning from one testbed or environment to another, when facing out-of-distribution data in open-world tasks, and when navigating the rapidly expanding solution and search spaces encountered in open-world domains.
Privacy and Bias Analysis of Disclosure Avoidance Systems
Jan 28, 2023



Disclosure avoidance (DA) systems are used to safeguard the confidentiality of data while allowing it to be analyzed and disseminated for analytic purposes. These methods, e.g., cell suppression, swapping, and k-anonymity, are commonly applied and may have significant societal and economic implications. However, a formal analysis of their privacy and bias guarantees has been lacking. This paper presents a framework that addresses this gap: it proposes differentially private versions of these mechanisms and derives their privacy bounds. In addition, the paper compares their performance with traditional differential privacy mechanisms in terms of accuracy and fairness on US Census data release and classification tasks. The results show that, contrary to popular beliefs, traditional differential privacy techniques may be superior in terms of accuracy and fairness to differential private counterparts of widely used DA mechanisms.