 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse Community Data for Benchmarking Data Privacy Algorithms
Paper and Code
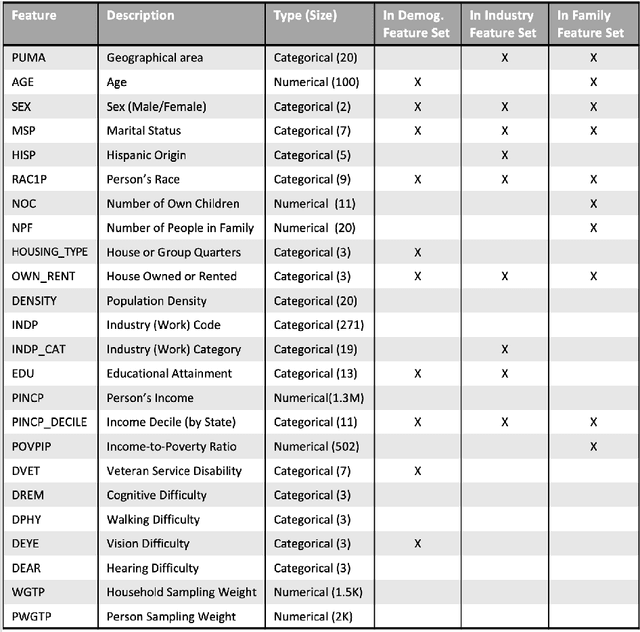



The Diverse Communities Data Excerpts are the core of a National Institute of Standards and Technology (NIST) program to strengthen understanding of tabular data deidentification technologies such as synthetic data. Synthetic data is an ambitious attempt to democratize the benefits of big data; it uses generative models to recreate sensitive personal data with new records for public release. However, it is vulnerable to the same bias and privacy issues that impact other machine learning applications, and can even amplify those issues. When deidentified data distributions introduce bias or artifacts, or leak sensitive information, they propagate these problems to downstream applications. Furthermore, real-world survey conditions such as diverse subpopulations, heterogeneous non-ordinal data spaces, and complex dependencies between features pose specific challenges for synthetic data algorithms. These observations motivate the need for real, diverse, and complex benchmark data to support a robust understanding of algorithm behavior. This paper introduces four contributions: new theoretical work on the relationship between diverse populations and challenges for equitable deidentification; public benchmark data focused on diverse populations and challenging features curated from the American Community Survey; an open source suite of evaluation metrology for deidentified datasets; and an archive of evaluation results on a broad collection of deidentification techniques. The initial set of evaluation results demonstrate the suitability of these tools for investigations in this field.