 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADAR: Closed-Loop Robotic Data Generation via Semantic Planning and Autonomous Causal Environment Reset
Mar 12, 2026The acquisition of large-scale physical interaction data, a critical prerequisite for modern robot learning, is severely bottlenecked by the prohibitive cost and scalability limits of human-in-the-loop collection paradigms. To break this barrier, we introduce Robust Autonomous Data Acquisition for Robotics (RADAR), a fully autonomous, closed-loop data generation engine that completely removes human intervention from the collection cycle. RADAR elegantly divides the cognitive load into a four-module pipeline. Anchored by 2-5 3D human demonstrations as geometric priors, a Vision-Language Model first orchestrates scene-relevant task generation via precise semantic object grounding and skill retrieval. Next, a Graph Neural Network policy translates these subtasks into physical actions via in-context imitation learning. Following execution, the VLM performs automated success evaluation using a structured Visual Question Answering pipeline. Finally, to shatter the bottleneck of manual resets, a Finite State Machine orchestrates an autonomous environment reset and asymmetric data routing mechanism. Driven by simultaneous forward-reverse planning with a strict Last-In, First-Out causal sequence, the system seamlessly restores unstructured workspaces and robustly recovers from execution failures. This continuous brain-cerebellum synergy transforms data collection into a self-sustaining process. Extensive evaluations highlight RADAR's exceptional versatility. In simulation, our framework achieves up to 90% success rates on complex, long-horizon tasks, effortlessly solving challenges where traditional baselines plummet to near-zero performance. In real-world deployments, the system reliably executes diverse, contact-rich skills (e.g., deformable object manipulation) via few-shot adaptation without domain-specific fine-tuning, providing a highly scalable paradigm for robotic data acquisition.
Privacy and Bias Analysis of Disclosure Avoidance Systems
Jan 28, 2023



Disclosure avoidance (DA) systems are used to safeguard the confidentiality of data while allowing it to be analyzed and disseminated for analytic purposes. These methods, e.g., cell suppression, swapping, and k-anonymity, are commonly applied and may have significant societal and economic implications. However, a formal analysis of their privacy and bias guarantees has been lacking. This paper presents a framework that addresses this gap: it proposes differentially private versions of these mechanisms and derives their privacy bounds. In addition, the paper compares their performance with traditional differential privacy mechanisms in terms of accuracy and fairness on US Census data release and classification tasks. The results show that, contrary to popular beliefs, traditional differential privacy techniques may be superior in terms of accuracy and fairness to differential private counterparts of widely used DA mechanisms.
Fairness Increases Adversarial Vulnerability
Nov 23, 2022



The remarkable performance of deep learning models and their applications in consequential domains (e.g., facial recognition) introduces important challenges at the intersection of equity and security. Fairness and robustness are two desired notions often required in learning models. Fairness ensures that models do not disproportionately harm (or benefit) some groups over others, while robustness measures the models' resilience against small input perturbations. This paper shows the existence of a dichotomy between fairness and robustness, and analyzes when achieving fairness decreases the model robustness to adversarial samples. The reported analysis sheds light on the factors causing such contrasting behavior, suggesting that distance to the decision boundary across groups as a key explainer for this behavior. Extensive experiments on non-linear models and different architectures validate the theoretical findings in multiple vision domains. Finally, the paper proposes a simple, yet effective, solution to construct models achieving good tradeoffs between fairness and robustness.
SF-PATE: Scalable, Fair, and Private Aggregation of Teacher Ensembles
Apr 11, 2022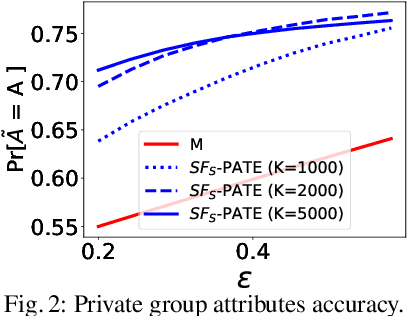
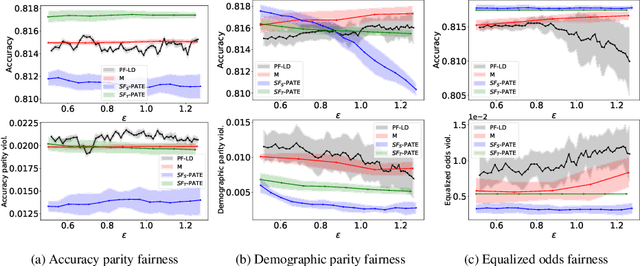
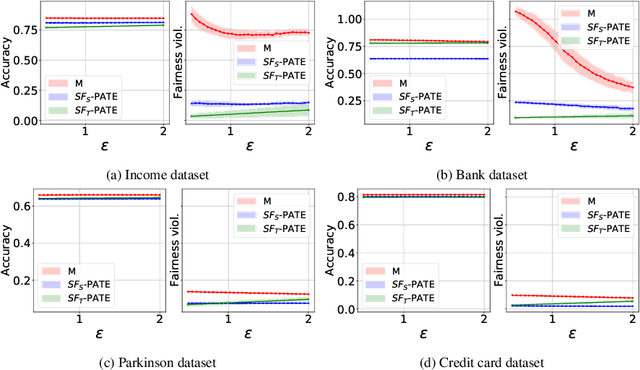

A critical concern in data-driven processes is to build models whose outcomes do not discriminate against some demographic groups, including gender, ethnicity, or age. To ensure non-discrimination in learning tasks, knowledge of the group attributes is essential. However, in practice, these attributes may not be available due to legal and ethical requirements. To address this challenge, this paper studies a model that protects the privacy of the individuals' sensitive information while also allowing it to learn non-discriminatory predictors. A key characteristic of the proposed model is to enable the adoption of off-the-selves and non-private fair models to create a privacy-preserving and fair model. The paper analyzes the relation between accuracy, privacy, and fairness, and the experimental evaluation illustrates the benefits of the proposed models on several prediction tasks. In particular, this proposal is the first to allow both scalable and accurate training of private and fair models for very large neural networks.
Differential Privacy and Fairness in Decisions and Learning Tasks: A Survey
Feb 16, 2022
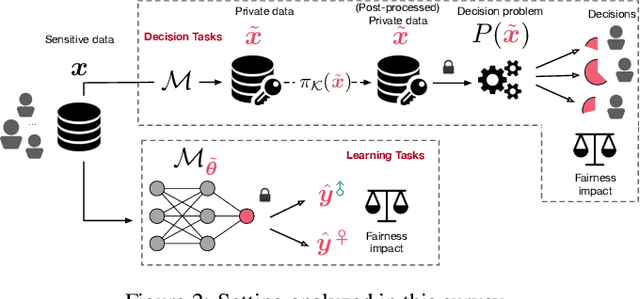
This paper surveys recent work in the intersection of differential privacy (DP) and fairness. It reviews the conditions under which privacy and fairness may have aligned or contrasting goals, analyzes how and why DP may exacerbate bias and unfairness in decision problems and learning tasks, and describes available mitigation measures for the fairness issues arising in DP systems. The survey provides a unified understanding of the main challenges and potential risks arising when deploying privacy-preserving machine-learning or decisions-making tasks under a fairness lens.
Post-processing of Differentially Private Data: A Fairness Perspective
Jan 24, 2022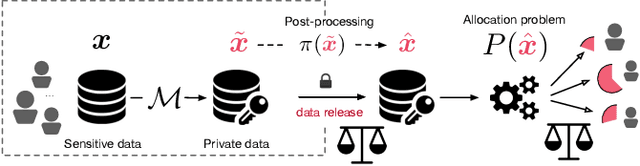

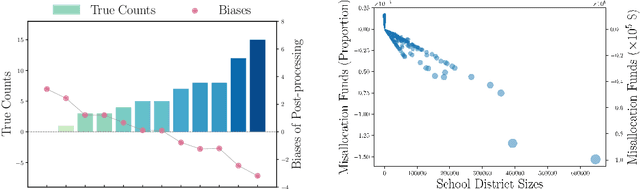

Post-processing immunity is a fundamental property of differential privacy: it enables arbitrary data-independent transformations to differentially private outputs without affecting their privacy guarantees. Post-processing is routinely applied in data-release applications, including census data, which are then used to make allocations with substantial societal impacts. This paper shows that post-processing causes disparate impacts on individuals or groups and analyzes two critical settings: the release of differentially private datasets and the use of such private datasets for downstream decisions, such as the allocation of funds informed by US Census data. In the first setting, the paper proposes tight bounds on the unfairness of traditional post-processing mechanisms, giving a unique tool to decision-makers to quantify the disparate impacts introduced by their release. In the second setting, this paper proposes a novel post-processing mechanism that is (approximately) optimal under different fairness metrics, either reducing fairness issues substantially or reducing the cost of privacy. The theoretical analysis is complemented with numerical simulations on Census data.
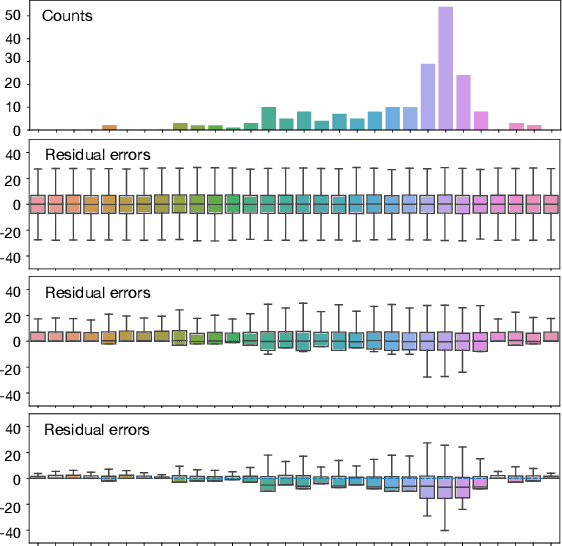
Bias and Variance of Post-processing in Differential Privacy
Oct 09, 2020
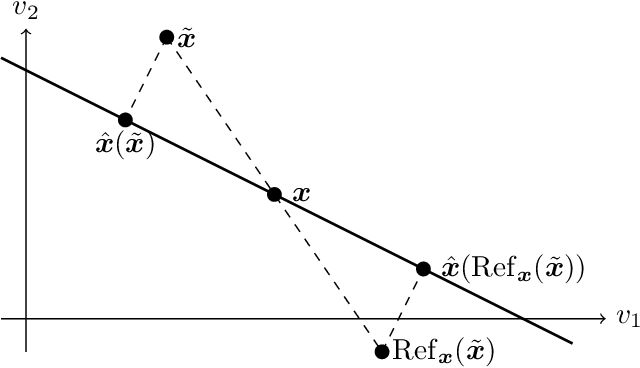
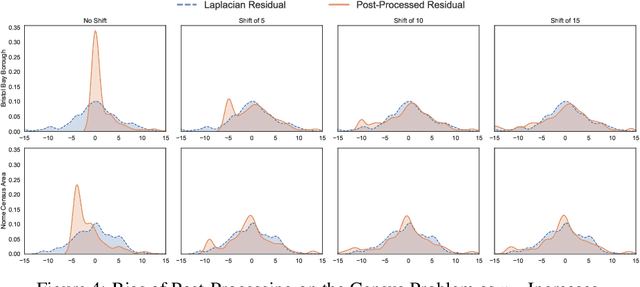
Post-processing immunity is a fundamental property of differential privacy: it enables the application of arbitrary data-independent transformations to the results of differentially private outputs without affecting their privacy guarantees. When query outputs must satisfy domain constraints, post-processing can be used to project the privacy-preserving outputs onto the feasible region. Moreover, when the feasible region is convex, a widely adopted class of post-processing steps is also guaranteed to improve accuracy. Post-processing has been applied successfully in many applications including census data-release, energy systems, and mobility. However, its effects on the noise distribution is poorly understood: It is often argued that post-processing may introduce bias and increase variance. This paper takes a first step towards understanding the properties of post-processing. It considers the release of census data and examines, both theoretically and empirically, the behavior of a widely adopted class of post-processing functions.
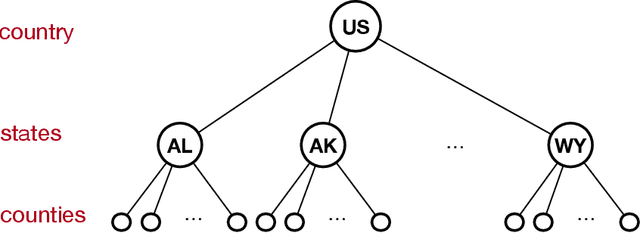
Differential Privacy of Hierarchical Census Data: An Optimization Approach
Jun 28, 2020
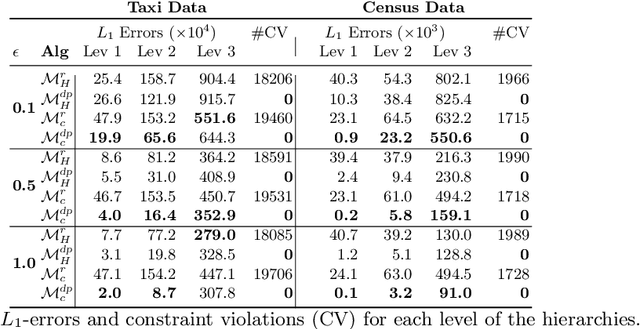
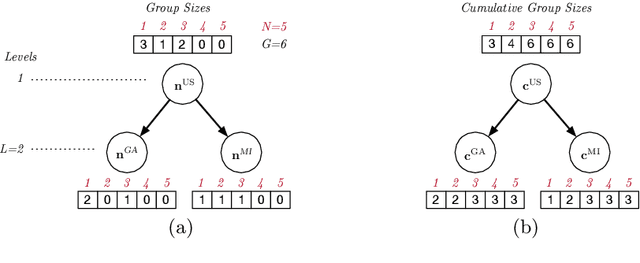

This paper is motivated by applications of a Census Bureau interested in releasing aggregate socio-economic data about a large population without revealing sensitive information about any individual. The released information can be the number of individuals living alone, the number of cars they own, or their salary brackets. Recent events have identified some of the privacy challenges faced by these organizations. To address them, this paper presents a novel differential-privacy mechanism for releasing hierarchical counts of individuals. The counts are reported at multiple granularities (e.g., the national, state, and county levels) and must be consistent across all levels. The core of the mechanism is an optimization model that redistributes the noise introduced to achieve differential privacy in order to meet the consistency constraints between the hierarchical levels. The key technical contribution of the paper shows that this optimization problem can be solved in polynomial time by exploiting the structure of its cost functions. Experimental results on very large, real datasets show that the proposed mechanism provides improvements of up to two orders of magnitude in terms of computational efficiency and accuracy with respect to other state-of-the-art techniques.