 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-processing of Differentially Private Data: A Fairness Perspective
Paper and Code
Jan 24, 2022

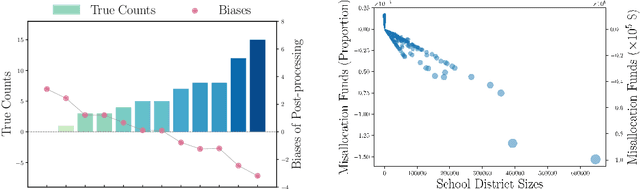

Post-processing immunity is a fundamental property of differential privacy: it enables arbitrary data-independent transformations to differentially private outputs without affecting their privacy guarantees. Post-processing is routinely applied in data-release applications, including census data, which are then used to make allocations with substantial societal impacts. This paper shows that post-processing causes disparate impacts on individuals or groups and analyzes two critical settings: the release of differentially private datasets and the use of such private datasets for downstream decisions, such as the allocation of funds informed by US Census data. In the first setting, the paper proposes tight bounds on the unfairness of traditional post-processing mechanisms, giving a unique tool to decision-makers to quantify the disparate impacts introduced by their release. In the second setting, this paper proposes a novel post-processing mechanism that is (approximately) optimal under different fairness metrics, either reducing fairness issues substantially or reducing the cost of privacy. The theoretical analysis is complemented with numerical simulations on Census data.