 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Fairness Impacts of Private Ensembles Models
Paper and Code
May 19, 2023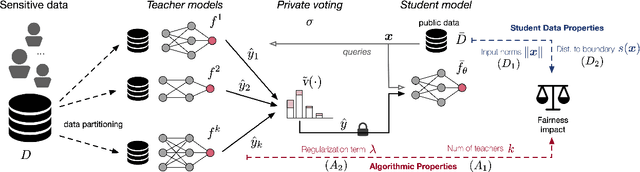



The Private Aggregation of Teacher Ensembles (PATE) is a machine learning framework that enables the creation of private models through the combination of multiple "teacher" models and a "student" model. The student model learns to predict an output based on the voting of the teachers, and the resulting model satisfies differential privacy. PATE has been shown to be effective in creating private models in semi-supervised settings or when protecting data labels is a priority. This paper explores whether the use of PATE can result in unfairness, and demonstrates that it can lead to accuracy disparities among groups of individuals. The paper also analyzes the algorithmic and data properties that contribute to these disproportionate impacts, why these aspects are affecting different groups disproportionately, and offers recommendations for mitigating these effects